当特征选择完成后,可以直接训练模型了,但是可能由于特征矩阵过大,导致计算量大,训练时间长的问题,因此降低特征矩阵维度也是必不可少的。降维(dimensionality reduction)是指通过对原有的feature进行重新组合,形成新的feature,选取其中的principal components。
降维作用:
1)降低时间复杂度和空间复杂度
2)节省了提取不必要特征的开销
3)去掉数据集中夹杂的噪
4)较简单的模型在小数据集上有更强的鲁棒性
5)当数据能有较少的特征进行解释,我们可以更好 的解释数据,使得我们可以提取知识。
6)实现数据可视化
数据降维方法主要分为线性方法和非线性方法,其中前者主要有PCA、LDA、矩阵分解SVD等多种方式,后者则包括ISOMAP,t-SNE以及UMAP等。
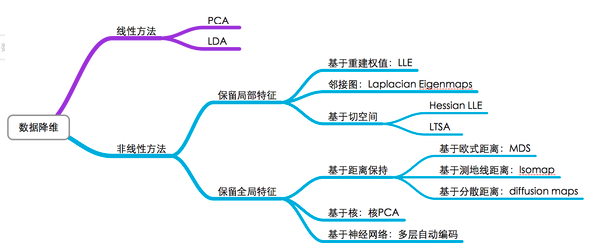
本文主要介绍常用的线性降维方法:主成分分析法(PCA)和线性判别分析(LDA)。PCA和LDA有很多的相似点,其本质是要将原始的样本映射到维度更低的样本空间中,但是PCA和LDA的映射目标不一样:PCA是为了让映射后的样本具有最大的发散性;而LDA是为了让映射后的样本有最好的分类性能。所以说PCA是一种无监督的降维方法,而LDA是一种有监督的降维方法。
1、主成分分析法(PCA)
使用decomposition库的PCA类选择特征的代码如下:
from sklearn.decomposition import PCA #主成分分析法,返回降维后的数据 #参数n_components为主成分数目 PCA(n_components=2).fit_transform(iris.data)
2、线性判别分析法(LDA)
使用lda库的LDA类选择特征的代码如下:
from sklearn.lda import LDA #线性判别分析法,返回降维后的数据 #参数n_components为降维后的维数 LDA(n_components=2).fit_transform(iris.data, iris.target)
......
参考:
https://blog.csdn.net/ma416539432/article/details/53286028
https://www.cnblogs.com/jasonfreak/p/5448385.html
https://zhuanlan.zhihu.com/p/43225794
本文转自:博客园 - EO_Admin,转载此文目的在于传递更多信息,版权归原作者所有。





