作者: 张建中
人们常用“模糊计算”(Fuzzy Computing)笼统地代表诸如模糊系统、模糊语言、模糊推理、模糊逻辑、模糊控制、模糊遗传和模糊聚类等模糊应用领域中所用到的诸多算法及其理论。在这些应用系统中,广泛地应用了模糊集理论,并揉和了人工智能的其他手段,因此模糊计算也常常与人工智能相联系。由于模糊计算可以表现事物本身性质的内在不确定性,因此它可以模拟人脑认识客观世界的非精确、非线性的信息处理能力和亦此亦彼的模糊概念和模糊逻辑。
概念是人类思维的基本形式之一,它反映了客观事物的本质特征。一个概念有它的内涵和外延,内涵是指该概念所反映的事物本质属性的总和,也就是概念的内容;外延是指一个概念所确指的对象的范围。例如“人”这个概念的内涵是指能制造工具,并使用工具进行劳动的动物,外延是指古今中外一切的人。在生产实践、科学实验以及日常生活中,人们经常会遇到诸多模糊概念,如大与小、轻与重、快与慢、动与静、深与浅、美与丑等都包含着一些模糊概念。
美国数学家、控制论专家L.A.Zadeh博士于1965年发表了关于模糊集的论文,首次提出了表达事物模糊性的重要概念——隶属函数(Membership Function)。这篇论文把元素对集的隶属度从原来的非0即1推广到可以取区间[0,1]的任何值,这样用隶属度定量的描述论域中元素符合论域概念的程度,实现了对普通集合的扩展,从而可以用隶属函数表示模糊集。模糊集理论构成了模糊计算系统的基础,人们在此基础上把人工智能中关于知识表示和推理的方法引入进来,或者说把模糊集理论用到知识工程中去就形成了模糊逻辑和模糊推理。为了克服这些模糊系统知识获取的不足及学习能力低下的缺点,又把神经网络计算加入到这些模糊系统中,形成了模糊神经系统。这些研究都成为人工智能研究的热点,因为它们表现出了许多领域专家才具有的能力。同时,这些模糊系统在计算形式上一般多以数值计算为主,也通常被人们归为软计算、智能计算的范畴。
模糊计算在应用上可一点都不模糊,其应用范围非常广泛,它在家电产品中的应用已被人们所接受,如模糊洗衣机、模糊冰箱、模糊相机等。另外,在专家系统、智能控制等许多系统中,模糊计算也都能大显身手,其原因就在于它的工作方式与人类的认知过程有着极大的相似性。
模糊数学(Fuzzy Mathematics),研究现实中许多界限不分明问题的一种数学工具,已广泛应用于模糊控制、模糊识别、模糊聚类分析、模糊决策、模糊评判、系统理论、信息检索、医学、生物学等各个方面。然而模糊数学最重要的应用领域是计算机智能,不少人认为它与新一代计算机的研发有着极其密切的联系。模糊数学基本概念之一是模糊集合,利用模糊集合、模糊矩阵、模糊运算和模糊逻辑等,能很好地处理各个不同领域应用中的模糊问题。
按照经典集合的理论,每一个集合必须由确定的元素构成,元素之于集合的隶属关系是明确的,这一性质可以用特征函数 μA(x) 来表示,即有:
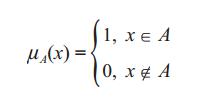
模糊数学把特征函数改写成所谓的“隶属函数 μA(x) :0≤ μA(x) ≤1”,在这里 A 被称为模糊集合, μA(x) 为隶属度。经典集合论要求 μA(x) 取 0 或 1 两个值,模糊集合则突破了这一限制, μA(x) = 1 表示百分之百隶属于模糊集合A, μA(x) = 0 表示完全不属于模糊集合 A,还可以有20%隶属于模糊集合 A,80%隶属于模糊集合 A ,等等,即可取 [0,1] 区间内的任意值。由于人脑的思维包括精确的和模糊的两个方面,因此模糊数学在人工智能系统模拟人类思维的过程中起到了重要作用,它与新型的计算机设计和许多模糊计算密切相关。
模糊数学的基本思想是隶属度,应用模糊数学建立数学模型的关键是建立符合实际的隶属函数。如何确定一个模糊集的隶属函数至今还是尚未得到很好解决的问题。常用的确定隶属函数的方法有模糊统计法、指派法、专家经验法、二元对比排序法及根据问题的实际意义来确定的方法等。模糊统计方法是一种客观方法,主要是在模糊统计试验的基础上根据隶属度的客观存在性来确定的;指派方法主要依据人们的实践经验来确定某些模糊集隶属函数的一种方法;在实际应用中,用来确定模糊集的隶属函数的方法是多种多样的,主要根据问题的实际意义来确定。譬如,在经济管理、社会管理中,可以借助于已有的“客观尺度”作为模糊集的隶属度。
由于模糊性概念已经找到了模糊集的描述方式,人们运用概念进行判断、评价、推理、决策和控制的过程也可以用模糊性数学的方法来描述。这些方法构成了一种模糊性系统理论,构成了一种思辨数学的雏形,已经在医学、气象、心理、经济管理、石油、地质、环境、生物、农业、林业、化工、语言、控制、遥感、教育、体育等方面取得多方面具体的研究和应用成果。
模糊理论(Fuzzy Theory)是指用到了模糊集合的基本概念或连续隶属度函数的理论,可分为模糊数学,模糊系统,不确定性和信息,模糊决策,模糊逻辑与人工智能众多分支,它们并不是完全独立的,之间存在着紧密的联系,例如,模糊控制就会用到模糊数学和模糊逻辑中的概念。从实际应用的观点来看,模糊理论的应用大部分集中在模糊系统上,尤其集中在模糊控制上,也有一些模糊专家系统应用于医疗诊断和决策支持。
模糊概念(Fuzzy Concept)是指这个概念的外延具有不确定性,或者说它的外延是不清晰的,是模糊的。例如“青年”这个概念,它的内涵我们是清楚的,但是它的外延,即什么样的年龄阶段内的人是青年,恐怕就很难说情楚,因为在“年轻”和“不年轻”之间没有一个确定的边界,这就是一个模糊概念。需要注意的几点:首先,人们在认识模糊性时,是允许有主观性的,也就是说每个人对模糊事物的界限不完全一样,承认一定的主观性是认识模糊性的一个特点。例如,我们让 100 个人说出“年轻人”的年龄范围,那么我们将会得到数十个不同的答案。尽管如此,当我们用模糊统计的方法进行分析时,年轻人的年龄界限分布又具有一定的规律性;其次,模糊性是精确性的对立面,但不能消极地理解模糊性代表的是落后的事物,恰恰相反,我们在处理客观事物时,经常借助于模糊性。例如,在一个有许多人的房间里,找一位“年老的高个子男人”,这是不难办到的。这里所说的“年老”、“高个子”都是模糊概念,然而我们只要将这些模糊概念经过头脑的分析判断,很快就可以在人群中找到此人。如果我们要求用计算机查询,那么就要把所有人的年龄,身高的具体数据输入计算机,然后我们才可以从人群中找这样的人。最后,人们对模糊性的认识往往同随机性混淆起来,其实它们之间有着根本的区别。随机性是其本身具有明确的含义,只是由于发生的条件不充分,而使得在条件与事件之间不能出现确定的因果关系,从而事件的出现与否表现出一种随机性。而事物的模糊性是指我们要处理的事物的概念本身就是模糊的,即一个对象是否符合这个概念难以确定,也就是由于概念外延模糊而带来的不确定性。
模糊逻辑(Fuzzy Logic)不是二元逻辑——非此即彼的推理,也不是传统意义的多值逻辑,而是在承认事物隶属真值中间过渡性的同时,还认为事物在形态和类属方面具有亦此亦彼性、模棱两可性——模糊性。模糊逻辑善于表达界限不清晰的定性知识与经验,它借助于隶属度函数概念,区分模糊集合,处理模糊关系,模拟人脑实施规则型推理,解决因“排中律”的逻辑破缺产生的种种不确定问题。模糊逻辑模仿人脑的不确定性概念判断、推理思维方式,对于模型未知或不能确定的描述系统,以及强非线性、大滞后的控制对象,应用模糊集合和模糊规则进行推理,表达过渡性界限或定性知识经验,模拟人脑方式,实行模糊综合判断,推理解决常规方法难于对付的规则型模糊信息问题。
模糊系统(Fuzzy System)基于模糊数学理论,能够对事物进行模糊处理。在模糊系统中,元素与模糊集合之间的关系是不确定的,即在传统集合论中元素与集合“非此即彼”的关系不适合模糊逻辑。元素与模糊集合的隶属关系是通过隶属度函数来度量的。当一个元素确定属于某个模糊集合,则这个元素对该模糊集合的隶属度为1;当这个元素确定不属于该模糊集合时,则此时的隶属度值为 0 ;当无法确定该元素是否属于该模糊集合时,隶属度值为一个属于 0 到 1 之间的连续数值。模糊系统能够很好处理人们生活中的模糊概念,清晰地表达知识,而且善于利用学科领域的知识,具有很强的推理能力。模糊系统主要应用在自动控制、模式识别和故障诊断等领域并且取得了令人振奋的成果,但是大多数模糊系统都是利用已有的专家知识,缺乏自学习能力,无法对自动提取模糊规则和生成隶属度函数。针对这一问题,可以通过与神经网络算法、遗传算法等自学习能力强的算法融合来解决。目前,很多学者正在研究模糊神经网络和神经模糊系统,这是对传统算法研究和应用的创新。
把模糊概念和一些传统算法及智能算法结合起来,形成了一大批的模糊算法,下面简举几例。
模糊遗传算法(Fuzzy Genetic Algorithm)是指基于模糊逻辑的遗传算法,是当前遗传算法发展的一个新方向。它充分利用了人们对遗传算法已有的知识和经验,并且修正和完善了这些经验,有助于对遗传算法的遗传算子及参数设置与遗传算法性能关系的理解;同时在遗传算法运行过程中,实现了对遗传算法参数或算子的动态调整,保证了整个遗传算法搜索过程中合理的利用性和探索性关系。把模糊逻辑用于遗传算法,是从两个方面着手的:一方面,把已有的关于遗传算法的知识和经验用模糊语言来描述,并用于在线控制遗传操作和参数设置,形成动态遗传算法;另一方面,借鉴模糊逻辑及模糊集合运算的思想,得到模糊编码和相应模糊遗传操作,以改进遗传算法的性能。
模糊聚类算法(Fuzzy Cluster Algorithm)是一种采用模糊数学语言对事物按一定的要求进行描述和分类的数学方法,一般是指根据研究对象本身的属性来构造模糊矩阵,并在此基础上根据一定的隶属度来确定聚类关系,即用模糊数学的方法把样本之间的模糊关系定量的确定,从而客观且准确地进行聚类。聚类就是将数据集分成多个类或簇,使得各个类之间的数据差别应尽可能大,类内之间的数据差别应尽可能小,即为“最小化类间相似性,最大化类内相似性”原则。聚类分析是数理统计中的一种多元分析方法,它是用数学方法定量地确定样本的亲疏关系,从而客观地划分类型。事物之间的界限,有些是确切的,有些则是模糊的。例人群中的面貌相像程度之间的界限是模糊的,天气阴、晴之间的界限也是模糊的。当聚类涉及事物之间的模糊界限时,需运用模糊聚类分析方法。模糊聚类分析广泛应用在气象预报、地质、农业、林业等方面。通常把被聚类的事物称为样本,将被聚类的一组事物称为样本集。模糊聚类分析有两种基本方法:系统聚类法和逐步聚类法。
模糊数学及其计算的产生不仅拓广了经典数学的基础,而且也是计算机科学向人们的自然机理方面发展的重大突破。它在科学技术、经济发展和社会学等问题的广泛应用领域中显示了巨大的力量,虽然发展的历史并不很长,但已被国内外数学界以及信息、系统、计算机和自动控制科技界人员的普遍关注,具有极其广阔应用前景。
作者: 张建中
出处:http://zhangjianzhong.blog.kepu.cn/20181206101852.html





