作者: Eleanor Brash
对于每一代 GPU,Imagination 内部的性能团队都会运行广泛的测试内容,分析并理解不同类型的工作负载及其瓶颈。作为分析的一部分,数据显示许多现代游戏在执行后处理算法上花费了越来越多的时间,以实现景深、光晕、模糊等效果。
大多数这些后处理过程都是以纹理采样为主的过滤效果,它们对算术逻辑单元 (ALU) 的要求不高,但受限于纹理处理单元 (TPU) 的吞吐率。解决这个问题的一种方法是简单地改变 TPU 单元与 USC/ALU 比例。然而,我们的分析表明这并非一个好策略,原因有以下几点。
首先,在常规渲染过程中,D系列 GPU 中 ALU 与 TPU 的比例已经是最佳的,增加更多的 TPU 并不会带来任何好处,因为工作负载受限于 ALU。同时,其他处理过程是 TPU 密集型的,同时也是带宽密集型的,因此增强 TPU 并不会有帮助,因为没有足够的带宽来满足额外的 TPU 吞吐量,因此性能不会得到提升。
我们的团队发现后处理工作负载以及计算图像处理工作负载具有以下特点:
- 在一个区域内进行规则的处理/采样,有大量的采样点重复利用,这些采样点命中纹理缓存;
- 对单一渲染目标/纹理进行2D采样,不涉及层次细节 (LOD) 和透视。
上述两个特性促使我们在 D系列 GPU 中实现了新的 TPU 模式,可以使性能翻倍,但仅当硬件检测到这些特性时才生效。第一个特性是重要的,因为常规的采样加上样本重复利用率高(例如,移动窗口滤波器)可以避免带宽限制。第二个特性也是重要的,因为它使我们能够保持重复逻辑的数量较低,避免所有 TPU 逻辑均翻倍的前提下,提供峰值吞吐率翻倍的效果。
这种方法的结果是适度增加了TPU 的大小,但在策略生效的情况下性能翻倍,同时保持与总体特性相平衡。IMG D 系列 GPU 实现了真正的加速,并避免了 ALU 和/或带宽瓶颈情况,这些情况下 TPU 已经足够快。这意味着对于某些类型的处理,DXT-48-1536 将有效地表现出等同 DXT-96-1536的性能,每时钟处理双倍数量的双线性滤波纹理样本,与前代 CXT-48-1536 相比则可提供两倍的执行速率。
作为示例,下图显示了一个典型的手机游戏及其渲染过程。顶部的条形图从左边开始,显示了各种 Vulkan 渲染过程,其中包含几个预处理过程,通常用于阴影贴图,对深度测试单元造成很大压力。渲染的第二阶段是主场景,本例中是一个 GBuffer 渲染过程和一个光照过程。我们可以看到,这是帧处理时间的主要部分,ALU和 TPU 的负载相对均衡;这通过红色曲线(TPU 负载)和绿色曲线(ALU 负载)表示。我们可以看到,随着时间的推移,两者都显示出平均利用率,这对于主场景来说是典型的,其中 ALU 和 TPU 工作的混合比例平衡。
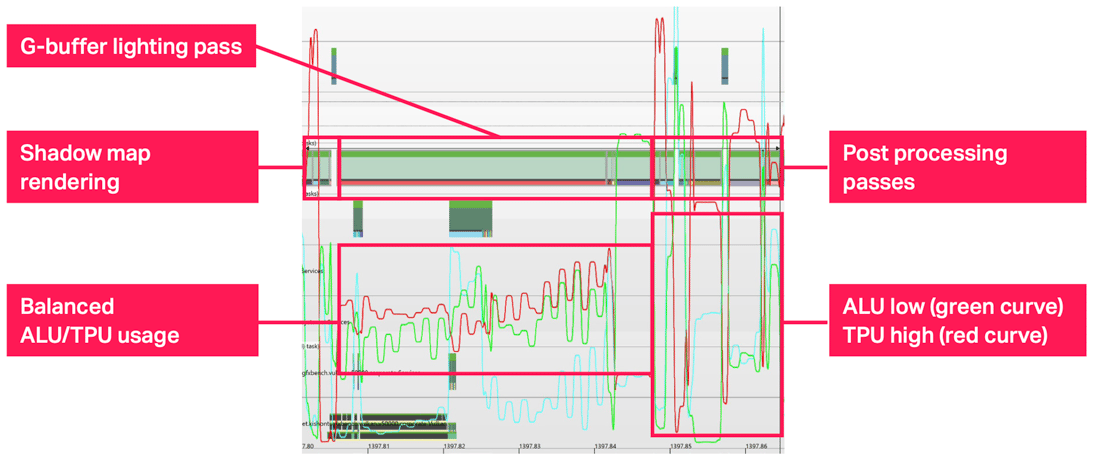
最让我们感兴趣的渲染过程是最后一组,即后处理过程。通常,这是在之前的主渲染过程之上应用光晕、模糊等许多 HDR 风格后处理效果的地方。在这个区域值得注意的是,红色的 TPU 曲线在很多情况下都升高,而绿色的 ALU 曲线却非常低。这表明 TPU 单元造成了处理瓶颈——而这正是 2D 双速率 TPU 设计要解决的问题。它为这些工作负载将 TPU 的速度翻倍,从而将渲染时间减少了一半,加快了帧渲染的速度。
欲了解IMG DXT 中 PowerVR 架构的更多改进细节,可以查阅白皮书《面向大众的光线追踪》(Ray Tracing for the Masses)。
英文链接:https://blog.imaginationtech.com/2d-dual-rate-texturing-in-d-series-gpu
声明:本文为原创文章,转载需注明出处及原文链接,否则,我们将保留追究其法律责任的权利。





