Imagination 近日宣布了与MulticoreWare.Inc公司的合作,后者是多核和异构计算环境软件解决方案和开发工具的领先供应商。MulticoreWare公司在展锐T710开发板上实现双目视觉算法stereoBM的openCL版本的移植和优化,移植后的算法在GPU平台上性能提升明显。
展锐T710开发板内部集成了Imagination GM9446显示芯片,主频为800MHz,采用12nm工艺制造,支持openCL4.0, openCL1.2和openGL3.0版本,最高性能能够达到128 FP32 FLOPs/Clock 和256 FP16 FLOPs/Clock。CPU支持八核处理器,主频2.0GHz, 内部集成AI神经网络处理器NPU,综合算力达4.2TOPS。

为了进一步提升开发板的算力,MulticoreWare团队在双目视觉stereoBM的OpenCL实现中,使用了开发板的Imagination GM9446系列GPU作为运算核心,相对于传统CPU的双目视觉算法stereo版本得到了极高的加速比。
这组算法的设计充分使用了Imagination GM9446的特点,采用大窗口尺寸和小分辨率图像620x188,local memory存储优化等方式提高了程序的性能。
算法经过调整不同的参数,窗口winSize大小为21,n_disp为64的时候,性能达到最佳。通常kernel越复杂,寄存器占用的空间就越大,最大工作组的大小就越小,有时候发挥不出来并行流水线的最大数量,从而影响性能。
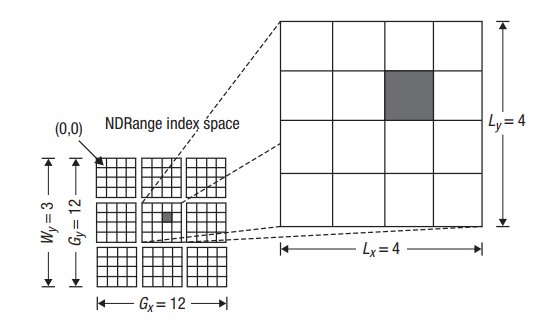
MulticoreWare公司团队在对kernel代码优化内部的寄存器使用量,根据GM9446内部结构,设置合理的global全局工作组大小256x图片高度,local工作大小为256,从而最大程度发挥GPU并行流水线的并发量,一般情况下,第一个维度的工作组大小应该是wave大小的倍数(例如32),这样可以充分利用wave资源,MulticoreWare团队根据多年优化经验,手动调整工作组大小以满足这个条件来保证性能有所提升。
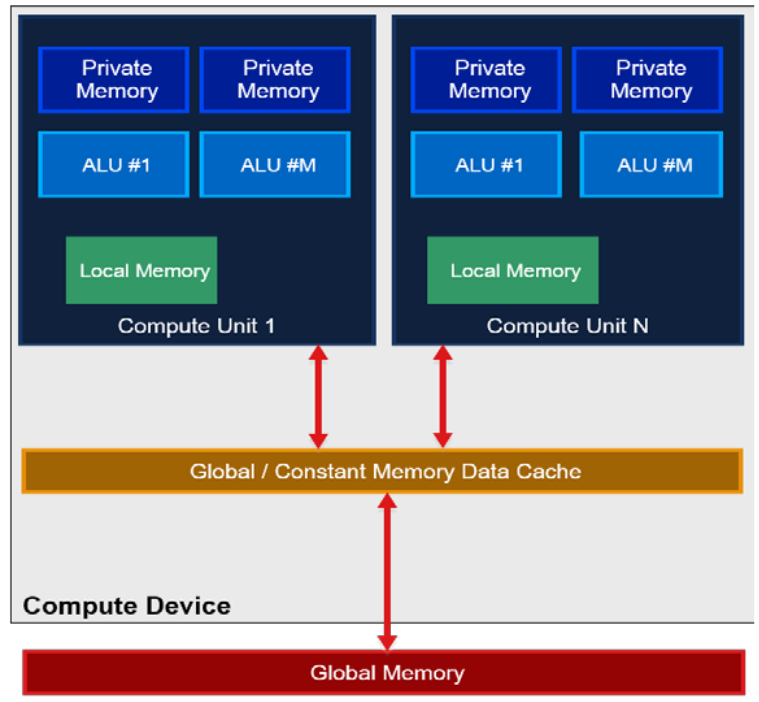
此外内存读取也是影响kernel运行效率的一方面,在OpenCL中一般有全局global内存,本地local内存,常量Constant和Private四种形式组成,MulticoreWare公司团队在将stereo算法重新调整内存布局,将主机内存使用零拷贝技术与GPU内存直接填充,另外将内核kernel多次内存访问的数据,从global内存转存到local内存中,虽然增加了一次转存数据的时间,但是对于对此存取数据整体时间是缩减的,从降低IO时间的角度整体提高了kernel内核的运行效率,性能也有所改善。
运行10次后进行效率对比,GPU比CPU计算最高提速80倍左右,平均提速50倍左右。

未来Imagination和MulticoreWare两家公司将致力于共同促进OpenCL在行业中的广泛采用,鼓励OpenCL广泛应用于异构计算、APU、以及CPU和GPU独立计算的领域中,实现计算资源利用率最大化、高效率处理数据传输。





