作者:James Imber,Tim Atherton
RISC(精简指令集计算机)的设计理念长久性地改变了计算的面貌,在本文中,我们提出了一种全新涉及神经网络加速器功能的方案:精简操作集计算(ROSC)。
从 RISC 及其演变情况来看,重点是小型、高度灵活和低层级的指令集,允许更深入的流水、向编译器的复杂性转移以及更好的整体性能。RISC 几十年来一直主导着计算机架构,是当今领先处理器架构的基础。
然而,RISC 的优势在某些操作局限于少量特定操作的应用。这种计算问题的一个典型例子是卷积神经网络(CNN) 推理,其中绝大多数的计算和带宽要求针对少量层:例如,卷积、池化和激活。在这样的设置中,需要使用硬件加速器,并针对这些常见任务进行专用的固定功能实现。执行这些操作之外的任何操作都将导致硬件无法打造最佳状态,要消耗更多的功耗和面积,以达到每秒相同的目标操作数。
ROSC概念
围绕高度优化的固定功能硬件构建神经网络加速器(NNA),可以很好地满足网络的绝大多数计算需求。然而,不可避免地会留下大量相对不常见的层类型:这些类型通常只占计算需求的一小部分,并且可能包括诸如softmax、argmax 和globalreduces等。我们需要一个好的方法来处理这些层类型。
高度优化的专用硬件加速器的问题是,它们聚焦范围很窄:每个模块都被精心设计成可以非常好地完成某项任务。
这导致有限的专用化,这通常被理解为将硬件的应用限制在为其设计的领域。
精简运算集计算(ROSC)是Imagination Technologies(IMG) 解决此问题的办法。它来自对某些硬件加速器包含高度伪装的通用操作集的认识。ROSC 正在通过一个或多个可用的固定功能操作构建新的操作(加速器上不存在针对这种操作的专门硬件)。
如何做到这一点,一开始并不明显,往往需要一些创造力——硬件有时会以高度非正统的方式使用!然而,随着这些技术的库被构建来实现常见操作,重用它们来构建新操作变得越来越容易。作为一种方法,这可以将加速器的灵活性远远扩展到其主要应用之外。它为硬件加速器带来了 RISC 的许多优点,例如操作重用、通用性和编译器的复杂性转移,而无需引入新的硬件。
ROSC 更常规的替代方案通常如下:
- 在另一台设备上执行这些操作,如 CPU、GPU 或 DSP。这是不可取的,因为它消耗系统带宽和系统其余部分的宝贵计算资源。
- 在增加通用可编程单元,如微处理器在内置或旁置的设计。这增加了缺少的功能,但增加了硬件复杂性以及电源和面积开销。与固定功能硬件相比,此类硬件的计算密度(单位面积的操作数)通常较低。
- 在为每个缺失的层类型添加更多专用硬件块。虽然这允许高度优化新模块的实现,但它使架构处于不断追赶最新技术的位置(即它不能面向未来)。它还会导致硬件膨胀和暗硅问题。
以上所有缺点,如增加面积和功耗或消耗CPU时间和带宽等系统资源。相比之下,ROSC 提供了一种优雅的方式,复用我们既有的固定功能硬件重用于常见的神经网络操作,支持非常广泛的其他层类型。
使用 ROSC 构建复杂层
例如,softmax可由硬件支持操作构建,如下所示。在这种情况下,目标架构是 IMG Series4 NNA(IMG 4系列NNA)。
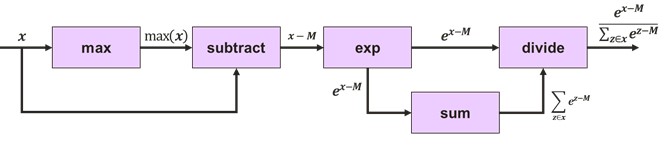
- 一个1×1的卷积其中权重全部为1可以用来实现跨通道的求和。
- 除法可以用一个张量与另一个张量的倒数相乘来实现。Series4的 LRN(本地响应归一化)模块可以配置为计算倒数。
- 跨通道最大值可以通过将Channel方向到空间轴上并执行一系列空间最大池化操作来实现。之后,它被转置回Channel方向。
- 由于指数仅限于负值和零输入值,激活 LUT 可以配置为指数衰减函数。
不适用固定硬件的常用模式一般会降低利用率。然而,把数据保留在设备上的收益通常大于这个缺点。例如,假设在上述softmax实现中,我们仅实现了4核IMG 4系列NNA的1%的利用率。这个 NNA 全速时有40 TOPS,因此即使在 1% 的利用率下,这仍然以非常可观的 400 GOPS下工作。片上存储器的可用性结合 Imagination 的张量分片算法意味着中间数据可以保持本地,最大限度地减少带宽消耗。终于,我们避免了需要协处理器来执行此层,并且不需要占用主机 CPU 时间。ROSC有利于代码重用。例如,一旦我们为Softmax 生成了用于除法和跨通道最大值的实现,我们就可以在其他层中重复使用这些实现。比如归一化操作,它重用softmax的除法实现。平方根操作也通过 LRN 模块实施。全局平均值减使用的技巧与我们在softmax中用于全局最大值减的技巧相同。
不难看出如何以这种方式构建可重复使用的底层构建库,从而使实现新的层类型变得越来越简单。这就是我们如何使用 ROSC 实现面向未来技术的方法。ROSC 还自然地适用于现有的图向下编译器(如 Glow 和 TVM),在那里我们可以将高级层分解为上图所示的计算图,并用由原始神经网络操作组成的子图依次替换每个部分。
在由一小部分复杂操作(如神经网络推理)主导的应用程序中,使用固定功能硬件使计算密度最大化,从而产生 CISC 处理器,乍一看,其功能覆盖范围极其有限。但是,我们发现,我们可以重新分配专用的 NNA 硬件(在我们的例子中是IMG 4系列),以覆盖范围极广的层类型。
以这种高度非正统的方式使用硬件往往会降低利用率。然而,只有少部分工作负载需要我们这样做,我们发现这通常是一个值得付出的代价,因为它提高了整体性能,并降低了带宽和功耗,特别是因为与典型SoC 中的其他可用设备相比,NNA的计算能力非常强大。
作者介绍

James Imber是Imagination Technologies公司人工智能研究团队的成员,主要从事神经网络加速器、编译器和针对嵌入式系统的低精度推理工作。在半导体知识产权行业担任研究员九年,他已累计获得24项专利,并在包括ECCV和ICPR在内的国际计算机视觉会议上发表论文。他在萨里大学视觉、语音和信号处理中心(CVSSP) 攻读了关于形状辅助内在图像分解的博士学位,并持有南安普敦大学电子工程的学士学位。

Tim Atherton是Imagination Technologies人工智能研究总监。在加入Imagination之前,Tim 是沃里克大学的获奖学者(计算机科学),专门从事生物视觉、高性能计算 (HPC)架构的数学模型以及向商业和政府机构的技术转让。
原文链接:https://www.embedded.com/reduced-operation-set-computing-rosc-for-nna-fu...
声明:本文为原创文章,转载需注明作者、出处及原文链接。





