作者:BENNY HAR-EVEN
众所周知我们的GPU产品每年都会有重大的进步——毕竟它们是我们引以为傲的产品之一,然而这次的情况有点不一样。近期我们发布了全新的GPU产品,这次我们取得了非凡的飞跃。今天我们很荣幸的向大家介绍Imagination A系列GPU产品,它包括一系列的核心产品,而且还引入了一个新的GPU架构。如图所示A系列相比目前的PowerVR GPU性能提升了2.5倍(或150%),正常情况下新的产品会提升性能20-25%,比如Oppo Reno Z手机上采用的PowerVR Series9XM,因此这无疑是一次重要的飞跃,这次的更新意味着效率提升,对于相同的性能需求功耗只需要从前的60%。

这是A系列GPU最吸引人的特性——没有时钟节流的持续运行——这肯定会让游戏玩家非常高兴。随着游戏机的不断普及,对于很多人来说智能手机是最常用的游戏平台,这使得你更有可能想在手机上玩一段时间的游戏,无论是在火车上还是宅在家里,有了A系列GPU你将能够享受更加出色的游戏性能,不会因为手机发热而造成游戏卡顿现象。
虽然A系列对于游戏行业来说是伟大的改变,但是我们更加自豪的是它也同时为其他很多市场,比如汽车、机顶盒、数字电视和服务器带来了性能的提升,这也是我们如此推广它的原因。
无处不在的GPU
A系列GPU的增强AI能力是性能提升的关键,我们现在的设备变得越来越“智能”,比如人脸识别登录、照片的自动分类以及拍照增强功能等,这就需要SoC器件为机器学习提供更多的性能,特别是神经网络。A系列产品满足了这一需求,其性能是Series9XM的8倍。

为了迎合市场的各个方面,我们发布了三个产品类型的七个核心:A系列AXT、AXM、AXE。
- IMG AXT-64-2048旗舰性能;2.0 TFLOPS, 64 Gpixels,AI性能8TOPS
- IMG AXT-48-1536用于高级移动设备;1.5 TFLOPS, 48 Gpixels, 6TOPS
- IMG AXT- 32-1024高性能移动设备和汽车;1 TFLOPs, 32 Gpixels, 4TOPS
- IMG AXT-16-512适用于中高端性能的移动设备和汽车;0.5 TFLOPS, 16 Gpixels,2TOPS
- IMG AXM-8-256适用于中端移动设备;0.25 TFLOPS, 8 Gpixels,1TOPS,
对于低成本的细分市场,IMG A系列在面积、成本和效率方面仍然是最好的选择:
- IMG AXE-2-16适用于高端物联网、入口DTV/STB、显示器和其他填充率驱动应用;2 PPC, 16 GFLOPS, 2 Gpixels
- IMG AXE-1-16用于入门级的移动设备和物联网,是同类中最快支持Vulkan的GPU;1 PPC, 16 GFLOPS和1 Gpixels
你可能已经注意到名单里没有提到PowerVR——但这并不是说A系列不是PowerVR产品,它也是其中之一,然而PowerVR并不是这个名字的一部分,而是指我们底层渲染的一种方法,它仍然是A系列的核心,也是我们与竞争对手的区别所在,即基于分块延时渲染(TBDR)。
核心名称中的数字不是任意的,而是不用指示性能的,第一个数字指的是每个时钟像素的填充率,主要用于高分辨率游戏,第二个代表FP32操作的性能——即计算能力。同时量子化神经网络计算(或者换句话说人工智能)使用的是整数计算,该范围还可以提供每秒最多8Tera的操作性能。
相比我们现在提供的产品,A系列产品有了显著的性能提升,你可能会想知道我们是如何一步到位的做到这一点的,这些改进源于各方面的性能增强,如下图所示。
ALU单元的超级带宽
然而,带来显著性能加速的原因是ALU单元的变化,ALU单元的全称是算术逻辑单元,它是图形处理单元的基本部分,在这里可以为图形和计算任务提供强大的计算性能。对于A系列而言我们已经从双MAD x32带宽的ALU改成单MAD 125线程宽的ALU。通过转换成128线程宽的单元我们现在能够在每个时钟内执行更多的操作指令,这是提升功耗效率的基础。当然保证ALU单元有足够的数据也是关键,我们已经实现了几个机制来确保我们可以做到这一点,其结果是性能显著提升,功耗明显降低。A系列的设计也是高度可扩展的,因此我们可以从一个扩展到四个可扩展的处理单元(SPU)来创建符合市场需求的核心产品,同时仍然保持最小的器件面积。
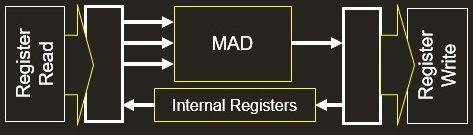
配置缓存空间
A系列产品的一个新的特性是缓存大小可以根据自己的需要进行配置,允许用户显著降低GPU带宽需求,现在可以减少更多的系统缓存,以减少使用系统内存的需求,或者允许使用性价比高的外部RAM来降低功耗、发热量和系统成本。
完美的图像质量
这不仅仅是最初的性能问题——A系列还提供我们更加喜欢的“完美像素”特性,这可以归结为在不牺牲图像质量的情况下提供出色性能的一系列技术,为此我们使用了许多新技术和老技术,我们有独特的PVRIC4图像压缩技术,使用无损或高度优化的有损压缩,以确保至少减少50%的带宽从而节省50%的内存占用。我们还提出了新的细节和各项异性滤波算法,这两种算法都能够显著提高图像质量。

HyperLane技术
A系列还引入了HyperLane技术,这些超级通道是8个独立的硬件控制通道,每个都在内存中进行隔离,实现安全、高效的多任务处理。这意味着你可以在GPU上同时运行AI任务,而且无需减速。这是通过我们所说的HyperLane动态性能控制来实现的,它确保了硬件的充分利用。任何限制的容量都可以用来确保最大的性能,并且可以对任务进行优先排序,从而防止它们永远小于某个阈值。例如你可以在使用信息娱乐系统的同时,在GPU上运行一个仪表盘集群,而不必担心至关重要的仪表盘集群的性能受到影响。超级通道(HyperLane)也可以用来保护数据,视频流可以通过GPU,而不必担心被黑客访问——这在机顶盒或数字电视产品中非常的重要。

AI协同功能
当网络模型得到适当的优化时,AI应用就可以在GPU上运行,而你可以在专用硬件(比如PowerVR NNA神经网络加速器)上运行,从而实现数量级更高、功耗更低的性能。借助A系列的AI协同功能用户还有另外一个便利,当你一起使用我们的GPU和NNA时,完全可编程的AI工作负载可以充分的被执行,使用Imagination DNN API在CPU、GPU或NNA之间划分层从而确保根据应用程序的需要在最合适的时机运行工作负载。
面向2020
这些只是A系列 GPU IP的一些功能特性,它将成为性能最高的一款产品,我们有信心A系列能够满足从移动到数字电视、汽车等广泛市场的需求,这就是为什么我们称它为“面向一切的GPU”,它能够提供持续的性能而不需要限制,尤其是满足各类玩家的需求。当然它还支持最新的图形库标准,比如Vulkan 1.1,因此开发人员可以最有效的使用硬件的性能,从最小的内核到最大内核设计。
更重要的是A系列只是一个开始,我们有一个基于此的产品开发路线图,在未来几个月和几年内我们将带来更多的产品设计,现在如果你正在为产品设计寻找GPU IP,那么A系列无疑是你最好的选择。
我们将继续跟进这篇,并与其他作者一起深入探讨A系列是如何对特定市场产生影响的。更多关于PowerVR的新闻和公告请大家关注我们的博客,并且在推特上关注我们@ImaginationTech,@PowerVRInsider。如果你想与我们继续谈谈IMG A系列,请大家随时联系我们。

原文链接:https://www.imgtec.com/blog/img-a-series-the-gpu-for-generation-2020/
声明:本文为原创文章,转载需注明作者、出处及原文链接,否则,本网站将保留追究其法律责任的权利。





