漏洞挖掘、利用及修复——从人工到自动的跨越
demi 在 周一, 12/10/2018 - 11:55 提交
随着互联网的普及,各类App如雨后春笋般产生。受限于代码质量,App中或多或少的会存在各类漏洞。据统计,CVE(http://cve.mitre.org/)及CNNVD(http://www.cnnvd.org.cn/)能够涵盖的漏洞多达100000个,严重威胁着网络及用户安全。当前,二进制漏洞挖掘主要依靠专业人员的人工审计,从而能够提供准确的漏洞点、漏洞利用及修补方案。
然而,人工审计与挖掘存在以下缺陷:
1. 开发团队往往缺少专业的安全人员,不能及时发现漏洞;
2. 面对数量庞大的漏洞,安全人员疲于应对。而自动化漏洞挖掘能够为人工审计提供良好的补充,也更为经济。
那么要构建这样一个自动化漏洞挖掘的系统需要哪些技术呢?下面,我们介绍一些具有代表性的相关技术。
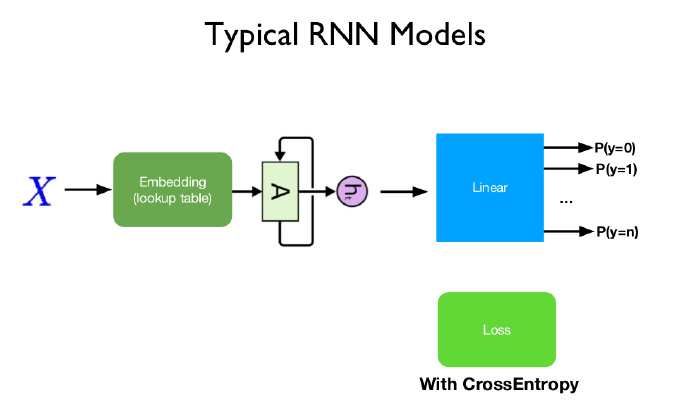
一、自动化漏洞挖掘技术
当我们拿到一个App以后,首要的工作是找到该App中的漏洞点。从被检测程序是否被运行的角度可知,自动化漏洞挖掘技术可分为静态分析、动态分析及混合分析。