自动驾驶汽车环境感知需要哪些传感器?
demi 在 周三, 10/31/2018 - 11:43 提交
自动驾驶汽车是依靠人工智能、视觉计算、激光雷达、监控装置和全球定位系统协同合作,让电脑可以在没有人类主动的操作下,自动、安全地操作机动车辆,其主要由环境感知系统、定位导航系统、路径规划系统、速度控制系统、运动控制系统、中央处理单元、数据传输总线等组成。
自动驾驶汽车在传统汽车的基础上扩展了视觉感知功能、实时相对地图功能、高速规划与控制功能,增加了全球定位系统天线、工业级计算机、GPS 接收机、雷达等核心软硬件。感知环节通过各种传感器采集周围环境基本信息,是自动驾驶的基础,主要包括毫米波雷达、激光雷达、超声波传感器、图像传感器等。
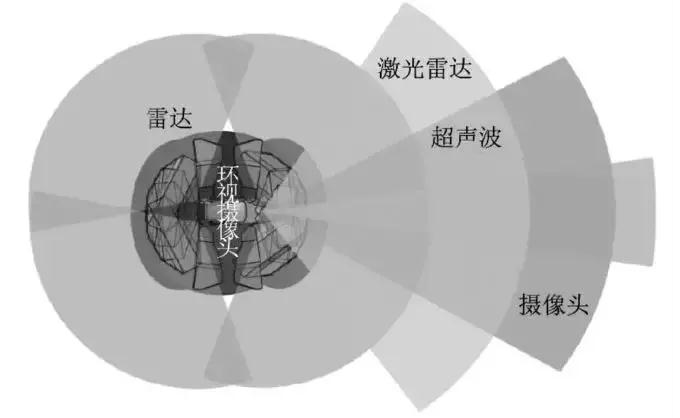
4种传感器及其产业链介绍
1、毫米波雷达