[收藏]机器学习高清思维导图(统计基础知识)
demi 在 周四, 10/11/2018 - 17:18 提交
分享17张机器学习高清思维导图:描述性统计:表格和图形法 、描述性统计:数值方法、概率、概率分布、抽样分布、区间估计、假设检验、两总体均值之差和比例之差的推断、总体方差的统计推断、多个比率的比较&独立性检验&拟合优度检验、实验设计&方差分析、简单线性回归、残差分析、多元回归、回归分析、时间序列及预测、非参数方法...
导图概览(点击图片查看缩放大图)
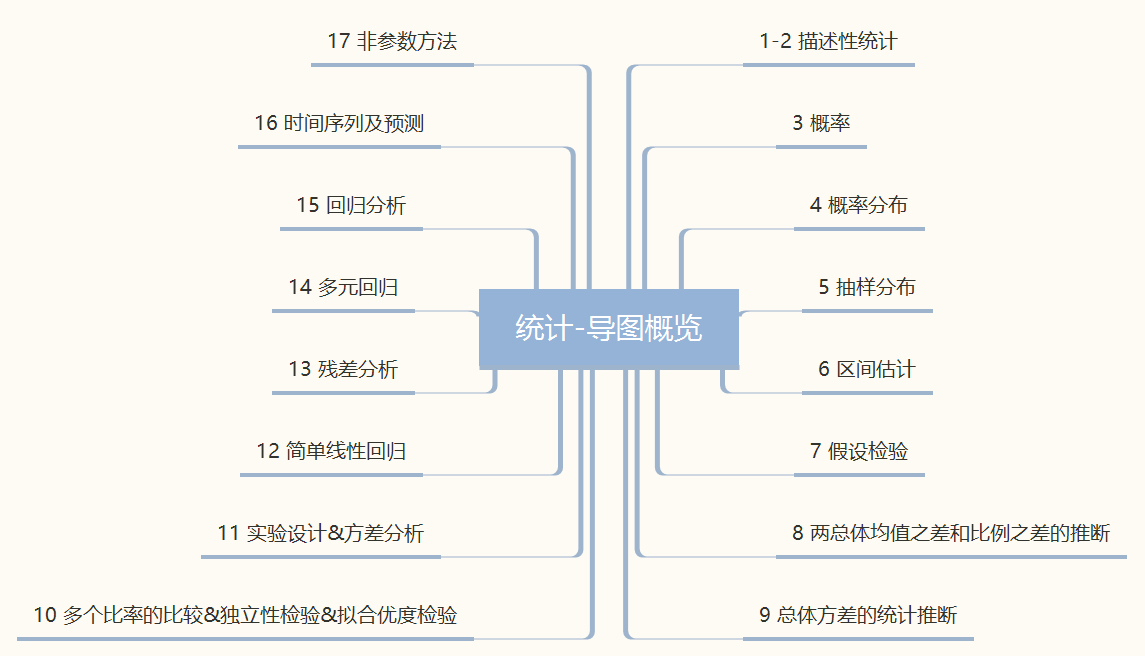
描述性统计:表格和图形法
分享17张机器学习高清思维导图:描述性统计:表格和图形法 、描述性统计:数值方法、概率、概率分布、抽样分布、区间估计、假设检验、两总体均值之差和比例之差的推断、总体方差的统计推断、多个比率的比较&独立性检验&拟合优度检验、实验设计&方差分析、简单线性回归、残差分析、多元回归、回归分析、时间序列及预测、非参数方法...
导图概览(点击图片查看缩放大图)
描述性统计:表格和图形法

人类智能在宏观上有心理学,微观上有分子生物学等学科研究。但每个方向研究到一定阶段就停滞了,没有哪个学科能告诉我们:为什么能有智能,如何才能产生智能。即使已经了解了大脑的很多知识,人类智能仍然是个黑盒子。
对黑盒的研究,要么从外部观察其行为,然后来模拟其结构,可称为自上而下的研究;要么猜测其结构,然后从外部的输入输出来验证其行为,可称为自下而上的研究。题目所说的自上而下还是自下而上即是从哪个方向来研究强人工智能问题。
宏观上研究的成果中,最显而易见的就是类人机器人。这类机器人从行为、语言、表情等方面来模拟人。如果最终能让人觉得这些机器人是真人,那么这个方向就算是成功了。当然,从现在的成果来看还不成功。另一方面是深蓝、沃森这样的依靠在下棋、回答问题等方面来战胜人类智能,从而证明自己能力。从这些特定的领域上来看,它们是比较成功的。但就算是把上面提到的所有方面都合到一起,也很难认为他们达到了人类的能力。
微观上的研究,是从感知器的结构被提出来后开始的。从此产生了现在的人工神经网络、机器学习等大量的算法和研究成果,解决了很多实际问题。从微观上出发,证明了它们从微观结构上模拟的优势,但需要花费大量时间建立问题模型。

这篇博客主要介绍处理不平衡数据的技巧,那么什么是不平衡数据呢?比如说一位医生做了一个病例对照研究,数据集由病例10人和对照990人组成,建立好一个逻辑回归模型后,并对建立的模型进行内部验证,居然发现其正确率高达99%,然后把他兴奋坏了,觉得可以将该成果发表到顶级期刊上,从此走上人生巅峰。然而,我们可以发现,该模型不管怎么预测,都能得到正常的结果,所谓的99%的正确率,原来是建立在1000个人中10个病例都发现不了的基础上。从这个例子可以看出,当遇到不平衡数据时,以总体分类准确率为学习目标的传统分类算法会过多地关注多数类,从而使得少数类样本的分类性能下降。
介绍
不平衡数据广泛存在于各个领域,但在二分类问题中尤其常见,表现为其中的一个类别所占的比例远远高于另外的一个类。比如:银行欺诈检测、市场营销、网络入侵检测等领域。
这些领域中的数据集有哪些共同点呢?可以发现在这些领域中使用的数据通常不到1%,但一旦发生就是一件“有趣”的事件(例如使用信用卡的欺诈者的违规交易,用户点击广告或原本已损坏的服务器在扫描其网络)。然而,大多数机器学习算法对于不平衡数据集都不能很好地工作。
以下七种技术可以帮助我们训练分类器来检测异常类。

随着无人车技术发展越发成熟,越来越多人开始关注这个号称拥有万亿量级市场的新型行业。那么今天,我就先简单介绍下通常无人车所拥有的传感器。
首先,在汽车前玻璃上装有两个摄像头,就像人眼一样,构立体图像,可以捕捉图像数据和距离数据。

其次,在两个立体相机中间是一个交通信号识别摄像头.通常交通信号灯在十字路口的另一边,因此需要特殊镜头,让摄像头捕捉足够的成像距离,可以检测远处的信号。

转载自公众号:论智(ID:jqr_AI)
作者:Adel Nehme
编译:weakish
编者按:和数据科学研究生Adel Nehme一起,探索卷积神经网络(机器视觉和图像识别领域最重要的深度学习技术之一)背后的直觉。
背景
随着AI的突破持续吸引公众注意,人们开始不加区别地使用“人工智能”、“机器学习”、“深度学习”等术语。然而,了解这些术语的区别,有助于把握AI技术的发展趋势。
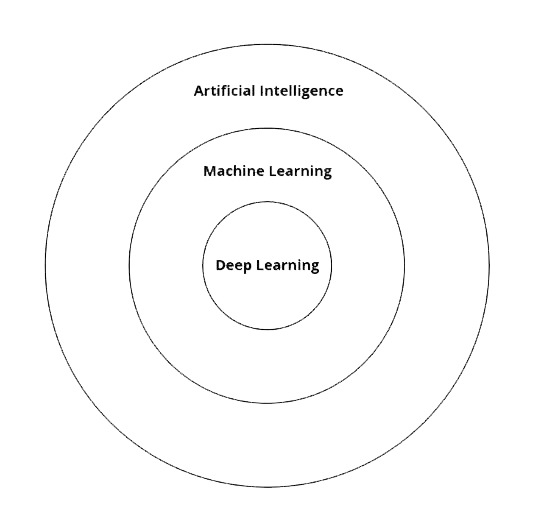
我们可以把这三个术语想象成三个同心圆,其中人工智能包含了机器学习,机器学习又包含了深度学习。
简单来说,有一些任务,传统上认为需要通过人类认知活动才能完成,开发执行这些任务的计算机系统,即为人工智能。

从概念提出到落地实践,从风险评估到监理全程跟踪监管,关于智慧城市规划与建设的探讨从未停止。全球来说,智慧城市的建设呈点状分布。美国迪比克市、韩国仁川市、爱尔兰戈尔韦湾、丹麦哥本哈根…它们探索着城市发展的智慧路径。
自2009年,美国IBM公司在中国连续召开了22场智慧城市讨论会,引爆“智慧城市”理念之后,我国不少城市也积极加入了这个“智慧愿景”的探索。然而国内外城市由于建设背景不同、探索路径不同,因而在摸索过程中得出的经验与教训也不尽相同。
智慧城市建设的背景
伴随着信息技术的飞速发展,美国、英国、日本、韩国等发达国家开始研究如何运用新一代信息技术来重新审视城市的本质、城市发展目标的定位、城市功能的培育、城市结构的调整、城市形象与特色等一系列现代城市发展中的关键问题,针对如何加大信息技术在城市管理、服务和运行中的创新性应用,相继提出了发展“智慧城市”的战略举措,把智慧城市建设作为提升城市竞争力的重要手段,城市智能发展的新模式开始孕育成型。

作者:宿永杰
宿永杰现就职于某知名互联网公司担任数据挖掘工程师,PC 端全栈开发工程师,擅长 Java 大数据开发、Python、SQL 数据分析挖掘等,参与过客户画像、客户识别以及自然语言处理等项目的开发,目前致力于中文自然语言处理的研究。
为什么会有分词
我们知道自然语言处理中词为最小的处理单元,当你的语料为句子、短文本、篇章时,我们要做的第一步就是分词。
由于英语的基本组成单位就是词,分词是比较容易的。其句子基本上就是由标点符号、空格和词构成,那么只要根据空格和标点符号将词语分割即可。
中文和英文就有很大不同了。虽然基本组成单位也是词,但是中文文本是由连续的字序列构成,词与词之间是没有天然的分隔符,所以中文分词相对来说困难很多。

0. 前言
看了台大的李宏毅老师关于Attention部分的内容,这一部分讲得挺好的(其实李宏毅老师其它部分的内容也不错,比较幽默,安利一下),记录一下,本博客的大部分内容据来自李宏毅老师的授课资料:Attention-based Model。如发现有误,望不吝赐教。
1. 为什么需要Attention
最基本的seq2seq模型包含一个encoder和一个decoder,通常的做法是将一个输入的句子编码成一个固定大小的state,然后作为decoder的初始状态(当然也可以作为每一时刻的输入),但这样的一个状态对于decoder中的所有时刻都是一样的。

众所周知,网页不仅应该被快速加载,同时还应该流畅运行,比如快速响应的交互,如丝般顺滑的动画……
一、GPU 加速能做什么?
首先我们要了解什么是 16ms 优化
• 大多数设备的刷新频率是 60 次/秒,(1000/60 = 16.6ms)也就说是浏览器对每一帧画面的渲染工作要在 16ms 内完成,超出这个时间,页面的渲染就会出现卡顿现象,影响用户体验。
• 浏览器在一帧里面,会依次执行以下这些动作。减少或者避免 layout,paint 可以让页面不卡顿,动画效果更加流畅。

受Hubel和Wiesel对猫视觉皮层电生理研究启发,有人提出卷积神经网络(CNN),Yann Lecun 最早将CNN用于手写数字识别并一直保持了其在该问题的霸主地位。近年来卷积神经网络在多个方向持续发力,在语音识别、人脸识别、通用物体识别、运动分析、自然语言处理甚至脑电波分析方面均有突破。本文将会深度详解cnn卷积神经网络原理,对人工智能领域感兴趣的朋友请继续往下看。

卷积神经网络