大语言模型(LLMs)如今在各个领域都备受瞩目,甚至被尝试应用于时间序列预测。但问题来了:大语言模型真的适合时间序列预测吗?

本文来自NIPS 2024,来自来自弗吉尼亚大学和华盛顿大学的研究团队发现基于大语言模型的时间序列预测方法,其表现并不比简单的、不依赖语言模型的方法更好,甚至在很多情况下还更差!但这些基于大语言模型的方法却需要消耗大量的计算资源。这不禁让人怀疑,大语言模型在时间序列预测中真的有用吗?
Are Language Models Actually Useful for Time Series Forecasting?
https://openreview.net/pdf?id=DV15UbHCY1
大语言模型是时序「鸡肋」吗?
时间序列分析在很多领域都非常重要,比如预测疾病的传播、分析零售销售数据、医疗健康监测以及金融市场的预测等。很多研究开始尝试将预训练的大语言模型(LLMs)应用到时间序列分析中,这种想法听起来很合理,因为语言模型本身就是处理文本序列的高手,而时间序列数据也有很强的顺序依赖性。
相关的这些研究的核心思路是:既然大语言模型擅长处理文本序列中的顺序关系,那么它们也应该能够处理时间序列数据中的顺序依赖性。
通过微调GPT-2中的Transformer模块和位置编码,让预训练的大语言模型更好地适应时间序列数据[5]。
通过重新编程的方式,将大语言模型的词嵌入与时间序列嵌入对齐,成功地在LLaMA上展示了时间序列数据的良好表示[50]。
将时间序列分割成重叠的块,这样可以在保留数据特征的同时缩短时间序列长度[15]。
除了大语言模型,时间序列预测领域还有一批“小而美”的对手。这些模型虽然规模小,但效率高,甚至在某些情况下超过了大语言模型。如(如Informer、FEDformer和Autoformer)拥有较好的预测性能,能够同时捕捉时间序列的幅度和相位信息,从而超越了基于Transformer的模型。
实验设计方法
论文希望搞清楚大语言模型在时间序列预测中到底有多大用处。为此,他们选择了三种最先进的基于大语言模型的时间序列预测方法,并提出了三种“消融方法”(ablation methods),也就是去掉或替换大语言模型的实验设计。 具体来说,这三种消融方法分别是:

“w/o LLM”:直接去掉大语言模型,看看剩下的结构能不能独立完成任务。
“LLM2Attn”:用一个简单的多头注意力层替换大语言模型。
“LLM2Trsf”:用一个简单的Transformer模块替换大语言模型。
实验模型
实验中选用了三种最近非常流行的时间序列预测方法,这些方法都基于大语言模型,而且在GitHub上收获了大量关注:
OneFitsAll:这个方法也被称为GPT4TS,它通过实例归一化和“块”化处理输入的时间序列,然后将其传递到线性层以获得语言模型的输入表示。
Time-LLM:这个方法通过“块”化将输入的时间序列进行标记化,并使用多头注意力将其与低维词嵌入对齐。然后,将这些对齐后的输出与描述性统计特征的嵌入结合,传递给预训练的冻结语言模型。
CALF:这个方法将输入的时间序列的每个通道视为一个“词”,并通过交叉注意力将其与语言模型的低维词嵌入对齐。这种表示被传递给预训练的冻结语言模型以获得“文本预测”。
实验数据集
为了验证这些方法的有效性,研究人员选择了八个真实世界的数据集进行测试。这些数据集涵盖了多种领域,包括电力、疾病、天气、交通和经济等。具体数据集如下:

ETT:包含电力变压器相关的七个因素,分为四个子集,其中ETTh1和ETTh2是按小时记录的,ETTm1和ETTm2是每15分钟记录一次。
Illness:记录了美国疾病控制中心每周的流感病例数据,描述了流感样病例与总病例的比例。
Weather:来自美国1600个地点的本地气候数据,每个数据点包含11个气候特征。
Traffic:来自加利福尼亚交通部门的小时数据集,记录了旧金山湾区高速公路的交通拥堵率。
Electricity:记录了321名客户从2012年到2014年的小时用电量。
Exchange Rate:记录了1990年至2016年八个国家货币的每日汇率。
Covid Deaths:记录了2020年1月至8月期间266个国家和地区的COVID-19每日死亡数据。
**Taxi (30 min)**:记录了2015年1月至2016年1月期间纽约市1214个地点的出租车行程数据,每30分钟记录一次。
评价指标
实验结果的评价指标是预测值与真实值之间的平均绝对误差(MAE)和均方误差(MSE)。
实验结果
在实验中,研究人员围绕以下六个关键问题展开研究:
预训练语言模型是否有助于预测性能?
基于LLM的方法是否值得付出计算成本?
语言模型的预训练是否对预测任务有帮助?
LLMs是否能有效捕捉时间序列的顺序依赖性?
LLMs是否对少样本学习有帮助?
LLMs的性能到底来自哪里?
RQ1:预训练语言模型是否有助于预测性能?
实验结果显示,预训练的LLMs在时间序列预测任务中并没有表现出明显的优势。在13个数据集和两种指标(MAE和MSE)的测试中,去掉或替换LLMs的消融方法在大多数情况下都优于或等于原始的LLM方法。具体来说:

在26次测试中,消融方法在26次中优于或等于Time-LLM;
在26次测试中,消融方法在22次中优于或等于CALF;
在26次测试中,消融方法在19次中优于或等于OneFitsAll。
这表明,LLMs在时间序列预测中的作用并没有想象中的那么大。
RQ2:基于LLM的方法是否值得付出计算成本?
虽然LLMs在预测性能上并没有显著提升,但它们的计算成本却非常高。例如,Time-LLM拥有66.42亿个参数,在Weather数据集上训练需要3003分钟。相比之下,消融方法只有245万个参数,平均训练时间仅为2.17分钟。在推理时间上,LLMs也比消融方法慢了数十倍。
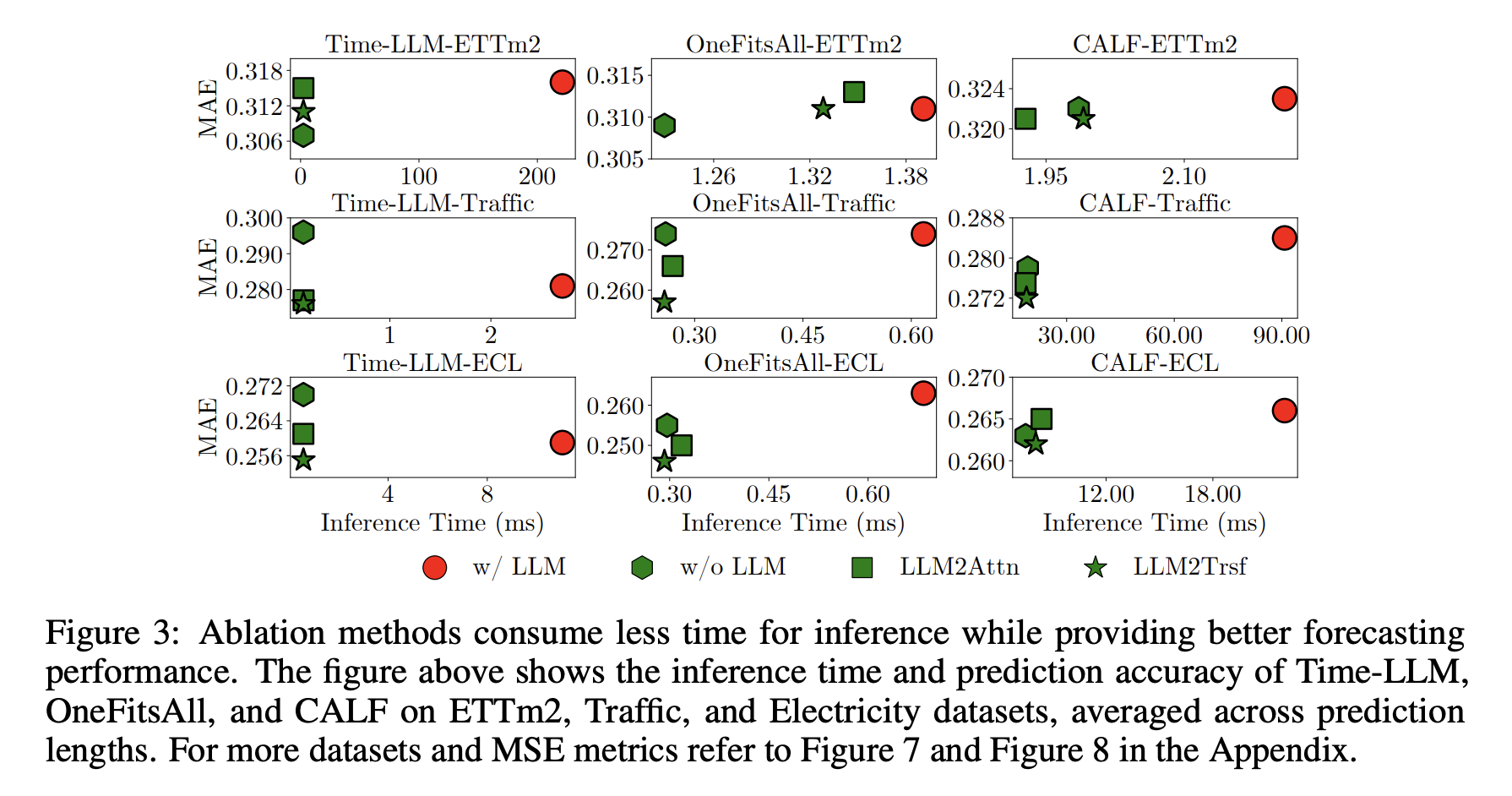
这表明,尽管LLMs的计算成本很高,但并没有带来相应的性能提升。
RQ3:语言模型的预训练是否对预测任务有帮助?
为了验证预训练是否对时间序列预测有帮助,研究人员设计了四种实验组合:
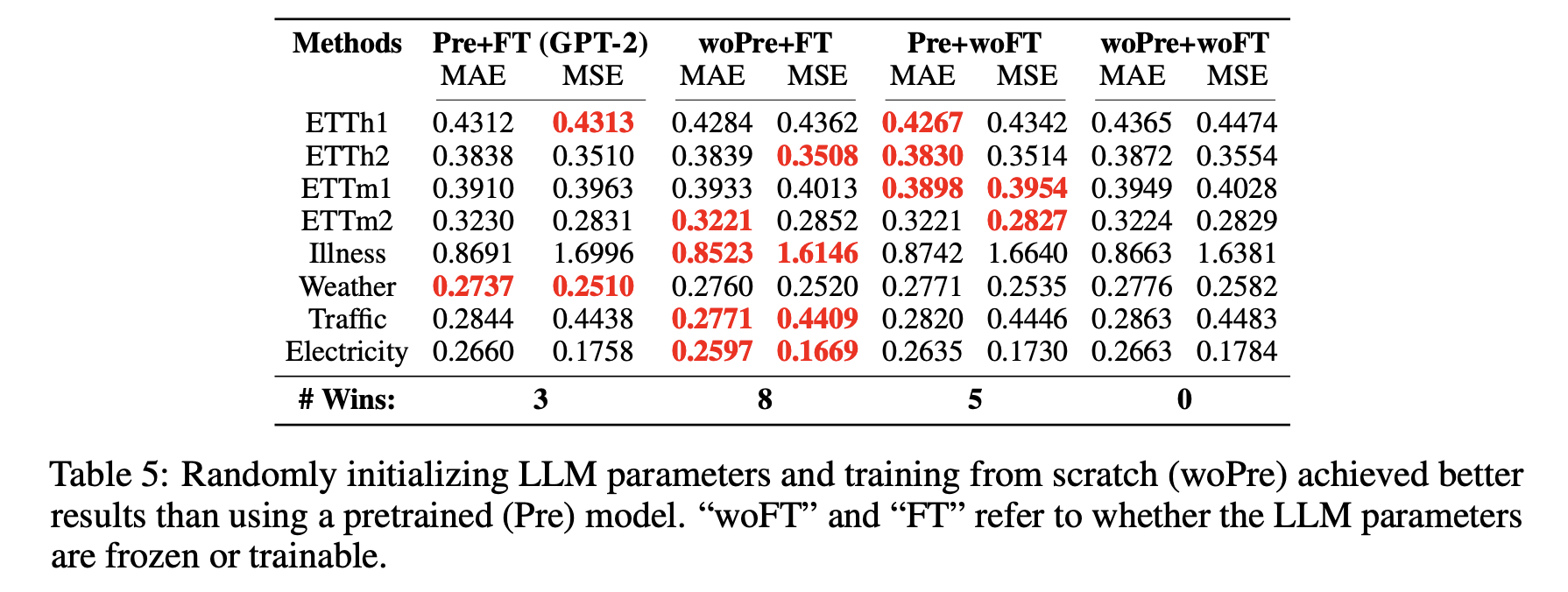
预训练+微调:这是原始方法,即在时间序列数据上微调预训练的LLMs。
随机初始化+微调:随机初始化LLMs的权重,从头开始训练。
预训练+不微调:冻结LLMs的权重,不进行微调。
随机初始化+不微调:完全随机初始化LLMs的权重,不进行微调。
实验结果显示,在8个数据集上,随机初始化+微调的方法表现最好的次数最多(8次),而预训练+微调的方法只表现最好3次。这表明,预训练的语言知识对时间序列预测的帮助非常有限。
RQ4:LLMs是否能有效捕捉时间序列的顺序依赖性?
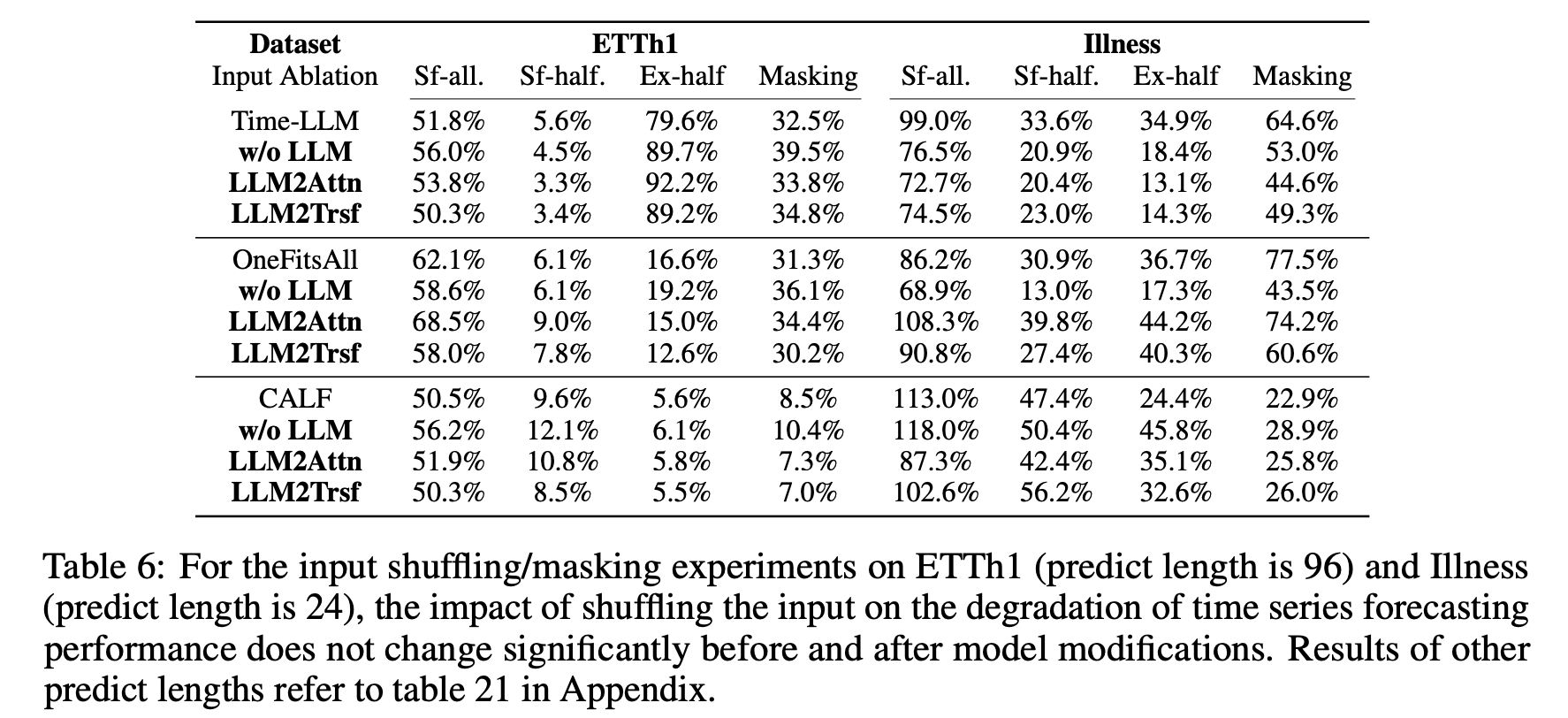
为了测试LLMs是否能有效捕捉时间序列的顺序依赖性,研究人员尝试了三种输入打乱方式:完全打乱、打乱前半部分和交换前后两部分。结果显示,LLMs在打乱输入后表现并没有明显下降,这表明它们并没有独特的能力来捕捉时间序列的顺序依赖性。
RQ5:LLMs是否对少样本学习有帮助?

研究人员还测试了LLMs在少样本学习场景下的表现。他们用每个数据集的10%数据训练模型,发现LLMs的表现并没有比消融方法更好。这表明,LLMs在少样本学习中也并没有明显的优势。
RQ6:LLMs的性能到底来自哪里?
为了探究LLMs的性能来源,研究人员分析了LLM时间序列模型中常用的编码技术,如“块”化(patching)和注意力机制。实验结果显示,一种结合“块”化和单层注意力的简单结构(PAttn)在小数据集上表现优异,甚至可以与LLMs相媲美。对于大数据集,使用CALF的编码器(LTrsf)表现更好。
这表明,LLMs的性能可能更多地来自于其编码结构,而不是预训练的语言知识。
论文结论
通过这些实验,研究人员得出了一个令人意外的结论:尽管LLMs在时间序列预测中非常受欢迎,但它们并没有显著提升预测性能。相反,简单的消融方法不仅性能更好,而且计算成本更低。
这并不意味着LLMs在时间序列分析中没有用武之地,而是提醒我们,LLMs可能更适合那些需要语言和时间序列结合的任务,比如时间序列推理或社会理解。
本文转自:Coggle数据科学,转载此文目的在于传递更多信息,版权归原作者所有。如不支持转载,请联系小编demi@eetrend.com删除。





