卷积神经网络(Convolutional Neural Network, CNN)是深度学习中专门处理网格结构数据(如图像、视频、音频)的里程碑式模型。它通过模仿生物视觉系统的层次化感知机制,让机器具备了从像素中提取抽象特征、理解视觉世界的能力,成为计算机视觉领域的核心引擎。

一、核心思想:局部感知与层次抽象
1. 为何需要CNN?
● 图像数据特性:高维度(如224x224x3)、空间局部相关性(相邻像素关联性强)
● 传统FNN的缺陷:全连接导致参数爆炸(224x224图像输入需超15万个权重)
● 生物视觉启发:视网膜细胞仅响应局部区域,层级传递抽象信息

2. 核心创新
● 局部连接:神经元仅连接输入区域的局部窗口(如3x3)
● 权值共享:同一滤波器(Filter)扫描整张图像,提取统一特征
● 层次化特征提取:
底层:边缘、纹理→ 中层:部件(眼睛、车轮) → 高层:物体(人脸、汽车)
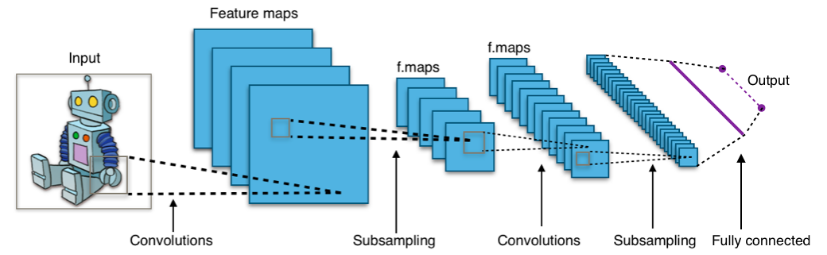
二、CNN五大核心组件
1. 卷积层(Convolution Layer)
滤波器(Kernel):可学习的特征检测器(如垂直边缘检测器)
尺寸:3x3、5x5等
深度:决定输出特征图数量(如64个滤波器→64张特征图)
关键参数:
- 步长(Stride):滑动步长(1或2常见)
- 填充(Padding):边缘补零保持尺寸
2. 激活函数(Activation Function)
作用:引入非线性,增强模型表达能力
主流选择:ReLU(f(x)=max(0,x)),缓解梯度消失
3. 池化层(Pooling Layer)
目的:降维、平移不变性、防止过拟合
常见类型:
- 最大池化(Max Pooling):取窗口内最大值(保留显著特征)
- 平均池化(Average Pooling):取窗口内平均值(平滑特征)
典型参数:2x2窗口,步长2 → 尺寸减半
4. 全连接层(Fully Connected Layer)
- 位置:网络末端(卷积层之后)
- 功能:将高阶特征映射到分类/回归结果
- 示例:ImageNet分类最后两层 → [4096, 1000]
5. 标准化与正则化
- 批归一化(Batch Norm):加速训练,减少对初始化的敏感度
- Dropout:随机屏蔽神经元,增强泛化能力

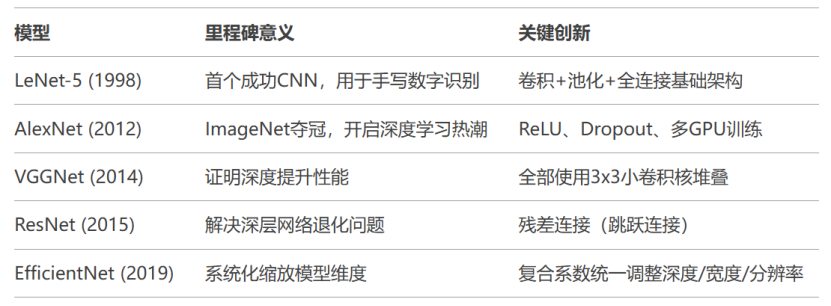
三、经典CNN架构演进史
四、CNN如何“看懂”图像?——可视化解析
1. 特征图可视化
- 第一层:检测边缘、颜色梯度
- 中间层:识别纹理、部件(车轮、窗户)
- 深层:响应完整物体(狗脸、汽车轮廓)
2. 类激活图(CAM)
- 技术:通过梯度加权显示图像关键区域
- 应用:解释模型为何判断图为“非洲象”(聚焦长牙和耳朵)
五、CNN的四大优势
参数效率:权值共享大幅减少参数量(比FNN少100-1000倍)
平移不变性:物体位置变化不影响识别结果
层次化特征:自动学习从低级到高级的抽象表示
硬件友好:卷积运算高度并行化,适合GPU加速
六、实战应用场景
1. 图像分类
- ImageNet挑战:ResNet-50实现超95% Top-5准确率
- 医学影像:CNN诊断糖尿病视网膜病变媲美专科医生
2. 目标检测
- YOLO系列:实时检测视频中数百种物体(30 FPS)
- Mask R-CNN:像素级分割肿瘤区域
3. 图像生成
- GAN:生成逼真人脸、艺术品
- 风格迁移:将梵高画风迁移至照片
4. 视频分析
- 行为识别:检测跌倒、打架等异常行为
- 自动驾驶:多摄像头融合感知周围环境
5. 跨模态应用
- 文字生成图像:DALL·E 2根据描述生成创意图片
- 视频描述生成:自动生成足球比赛解说字幕
七、挑战与未来方向
1. 当前局限
- 数据依赖:需大量标注数据(医学影像标注成本高)
- 计算成本:训练ViT-Huge需数千GPU小时
- 脆弱性:对抗样本可轻易欺骗模型
2. 前沿探索
- 轻量化CNN:MobileNet、ShuffleNet适配移动端
- 神经架构搜索(NAS):自动化设计最优网络结构
- Transformer融合:Swin Transformer结合CNN局部性与全局注意力
- 3D CNN:处理视频、医学体数据(如CT扫描)
总结:CNN——数字视觉的开拓者
从识别邮政编码到驾驶汽车,CNN将人类对视觉的理解编码成可计算的规则。它不仅是技术工具,更是一面镜子——让我们重新思考“看见”的本质:智能,始于对模式的觉察,成于层次的抽象。
学习建议:
- 使用可视化工具(如CNN Explainer)观察卷积过程
- 从PyTorch/Keras快速实现CIFAR-10分类(代码 < 50行)
- 尝试微调预训练模型(如ResNet)解决实际任务
正如望远镜扩展了人类的视野,CNN正在扩展机器的视界——这不是冰冷的计算,而是人类认知边疆的又一次壮丽远征。
本文转自:华算科技,转载此文目的在于传递更多信息,版权归原作者所有。如不支持转载,请联系小编demi@eetrend.com删除。





