本文由半导体产业纵横(ID:ICVIEWS)编译自chipestimate
3D多芯片设计背后的驱动因素以及3D封装的关键芯片到芯片和接口IP要求。
3D 多芯片设计的市场预测显示,硅片的设计和交付方式将发生前所未有的变化。IDTechEx 预测到 2028 年 Chiplet 市场规模将达到 4110 亿美元。Market.us 报告预测先进封装的规模将从 2023 年的 350 亿美元增长到 2033 年的 1580 亿美元,在同一报告中,Market.us 预测 1550 亿美元中超过 600 亿美元将是 3D SoC 和 3D 堆叠存储器。这些数字和报告证实了快速采用多芯片设计和 3D 封装的趋势。本文重点介绍了 3D 多芯片设计背后的驱动因素以及 3D 封装的关键芯片到芯片和接口 IP 要求。
为了克服摩尔定律的限制并充分利用多芯片设计,设计人员可以通过多种方式在单个封装中集成异构和同质芯片,如图 1 所示。
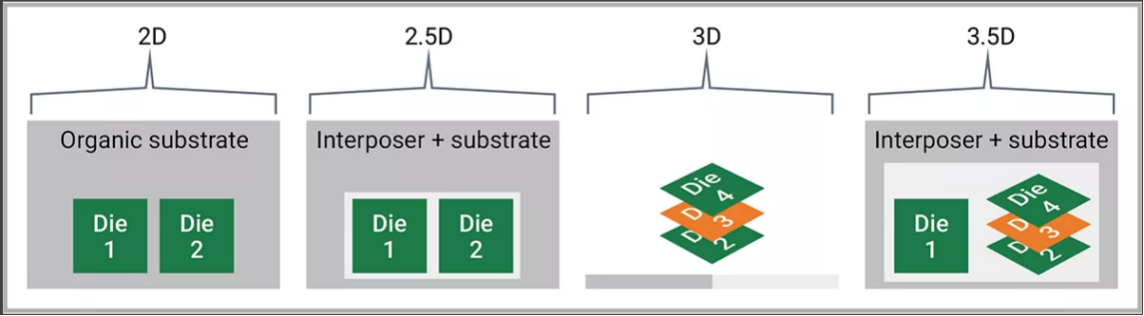
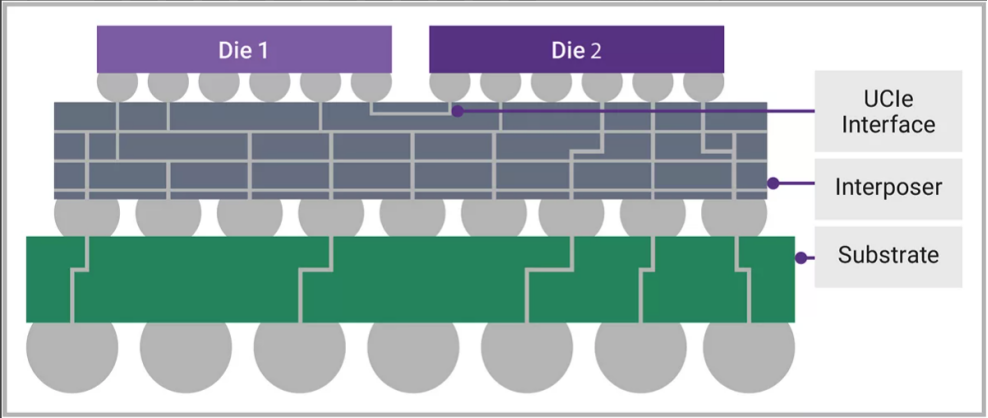
第一个例子展示了在一个封装中集成 2 个或更多芯片,使用有机基板与单端或差分 IO 或短距离串行收发器连接。2D 集成方法成本相对较低,但芯片之间的带宽有限。在 2.5D 集成中,如图 2 所示,使用更高性能的中介层来实现多个芯片之间的高密度信号路由。然后将信号路由到封装基板并输出到封装引脚。芯片通过芯片到芯片接口(如 UCIe)连接,每通道数据速率为 40G 或更高,旨在提供更高的带宽,同时管理延迟和热约束权衡。
3D 集成可以减小尺寸,但更重要的是增加互连密度、降低延迟和降低互连功率,以实现更好的可扩展性。在 3.5D 集成中,包括从 3D 芯片堆栈到另一个 2D 芯片或 3D 芯片堆栈的芯片到芯片连接。
2.5D 多芯片设计驱动因素
先进的工艺节点正在推动更多的晶体管,但随着摩尔定律的放缓和对提高复杂 AI 工作负载的计算性能的需求,设计需要比单个 800mm2 光罩所包含的更多的处理能力。作为第一步,设计人员可以将两个或更多芯片放置在通过并行或串行 I/O 连接的封装中,以扩展到更多的处理能力。更好的方法是将功能分解为多个较小的芯片(也称为小芯片)。较小的芯片可以提高良率,并且即使增加了芯片到芯片接口的硅片面积和先进封装成本,也可以提供更低成本的解决方案。这种多芯片设计方法包括优化每个芯片的工艺节点的选项,从而可以节省更多成本。
通过精心规划,产品经理和架构师可以从可重复使用的芯片芯片集合中抽取,这些芯片可以集成在高级封装中。例如,低端系统可能只有一个 AI 加速器芯片,而高性能产品可能包含多个 AI 加速器芯片以扩展性能。每个产品都可以使用同一组基本芯片以不同的组合或拓扑结构创建,以优化处理、热管理和成本需求。此外,通过重复使用芯片并创建新的封装来生产新产品,新系统的实施速度比使用传统方法流片单片芯片要快得多,而且总拥有成本要低得多。
2.5D 集成已经在 FPGA 等应用中大规模生产了十多年。2.5D 集成面临的一些挑战是用于互连多个芯片的硅中介层的尺寸有限(近期为 3-5 个掩模版)。这限制了单个封装中可以包含的芯片数量。较大的硅中介层会带来可靠性问题,例如脆性和翘曲,这可能会影响凸块连接的可靠性。为了解决其中一些尺寸和可靠性问题并扩展 2.5D 集成的实用性,业界正在开发带有或不带有硅桥的新型再分布层 (RDL) 中介层。硅桥可以增加比 RDL 中介层单独提供的更高的信号密度路由。
3D多芯片设计驱动程序
2.5D 集成已推动了多芯片产品的浪潮,但 2.5D 互连确实成为带宽、处理和低延迟需求的限制因素,而这些需求的增长速度快于串行 2.5D 芯片到芯片链接能力。一种改进方法是使用 3D 芯片堆叠。3D 封装有可能大幅提高互连密度,同时降低延迟和互连功耗,在某些拓扑中几乎采用线到线链接。UCIe 规范显示,UCIe Advanced(或 UCI-A)互连的目标带宽规范为每平方毫米 (mm2) 188-1350 GB/s,而 UCIe-3D 的目标值为每 mm2 4TB/s,假设凸块间距为 9um,如表 1 所示。同时,功率效率从 0.25 pJ/b 目标提高到 <0.05 pJ/b 目标。以计算芯片作为顶部芯片、缓存存储器芯片作为底部芯片的系统为例,3D 封装的低延迟优势至关重要。

3D 封装的 IP 注意事项
实现 3D 封装在可扩展性和性能方面提供了许多好处,但也带来了新的挑战。为了应对这些挑战,需要一种新方法和新工具来进行架构定义和规划、可行性评估、原型设计和高级封装设计。设计人员需要考虑新的多物理方面,例如不同芯片上元件之间的串扰以及多个芯片的热管理,其中一个芯片可能会加热附近的芯片。
有了 3D 封装,IO 不再需要放置在芯片的边缘。此外,通过使用混合键合技术,芯片之间的垂直芯片到芯片连接更加紧密。混合键合使用微小的铜对铜连接(<10um)连接封装中的芯片。
接口 IP 3D 集成
在考虑将接口 IP 与片外 IO PHY 集成时,并不像采用现有的 2D 实现并通过支持 3D 的工具运行它们那么简单。IP 提供商必须仔细考虑提供在特定 3D IC 拓扑环境中工作的 IP。这将需要 IP 提供商和设计人员之间建立比过去更紧密的合作关系。
一种常见的 3D 拓扑是晶圆上芯片 (CoW)。这种拓扑将经过测试的芯片堆叠在经过测试的晶圆顶部,然后切割成单个已知良好的芯片堆栈,然后组装和测试以创建最终产品。芯片与晶圆的键合可以使用金属对金属混合键合技术或焊料凸块连接。在这种拓扑中,与标准的面朝下的倒装芯片组装相比,底部芯片是翻转的,因此金属面朝上并直接面向顶部芯片的金属,这是标准方向,如图 3 所示。这提供了 2 个芯片之间最高密度和最低电阻的连接,但仅限于 2 个芯片的堆栈。面对面拓扑将芯片保持在标准倒装芯片面朝下的方向,但允许在 HBM 存储器等应用中堆叠 2 个以上的芯片。
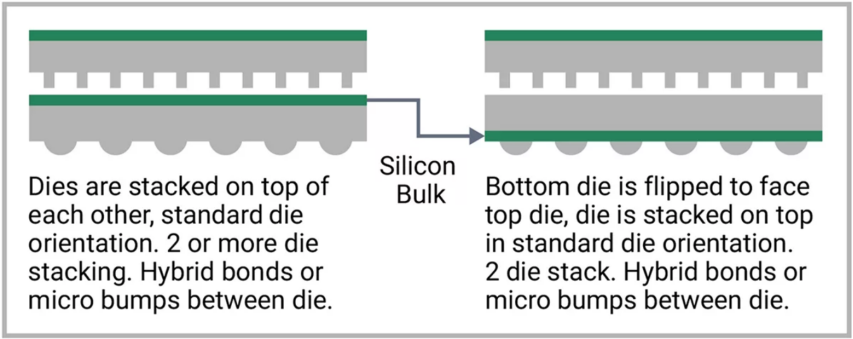
在Face-to-Back拓扑中,典型的堆栈将尖端计算节点作为顶部芯片,而下部芯片将位于较旧且成本较低的工艺节点上,并包括模拟和 I/O 功能,这些功能不会从扩展到最新节点中受益太多。
可能包含的底部芯片接口 IP 示例有 2.5D UCIe 接口(用于连接到同一封装中的其他 3D 堆栈或 2D 芯片)或 PCIe 6.0/7.0 或 224G 以太网接口(用于通过封装连接到外界)。在这些情况下,必须重新定位 PHY IP,以便来自凸块的信号通过硅通孔 (TSV) 穿过硅块连接到金属层并路由到扩散层硅器件。IO 可能还需要考虑添加 TSV 和路由以将信号和电源连接到顶部芯片。在这种情况下,底部芯片(PHY IP)的尺寸可能会增加,以考虑这些额外的信号,并且设计人员必须执行额外的分析来解决多物理场对 TSV 信号和嵌入式电感的影响。
本文转自:半导体产业纵横,转载此文目的在于传递更多信息,版权归原作者所有。如不支持转载,请联系小编demi@eetrend.com删除。





