在大模型开发中,嵌入模型一直是研究和应用的核心。然而,随着模型规模的不断扩大,其对计算资源的需求也日益增加,尤其是在 CPU 上的运行效率往往成为瓶颈。
▎https://huggingface.co/blog/static-embeddings
本文介绍一种全新的静态嵌入模型训练方法,能够在 CPU 上实现比当前最先进的嵌入模型快 100 到 400 倍的速度提升,同时保留了大部分的性能表现。
新发布的两大高效模型
基于这一创新方法,我们训练了两个极其高效的嵌入模型:
1. sentence-transformers/static-retrieval-mrl-en-v1:专为英语检索任务设计,性能卓越。
2. sentence-transformers/static-similarity-mrl-multilingual-v1:适用于多语言相似性任务,覆盖广泛语言。
与常见的同类模型(如 all-mpnet-base-v2 和 multilingual-e5-small)相比,这两个模型在 CPU 上的运行速度提升了 100 到 400 倍,同时在各种基准测试中至少达到了它们 85% 的性能表现。
什么是嵌入(Embeddings)?
在自然语言处理(NLP)的世界里,嵌入(Embeddings)是最重要的工具之一。它几乎可以解决所有类型的自然语言任务,是连接人类语言和机器理解的桥梁。
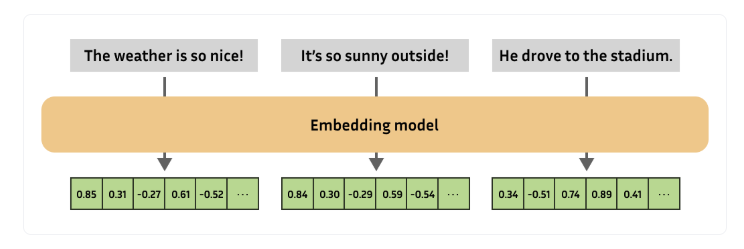
简单来说,嵌入是一种将复杂对象(如文本、图像、音频等)转换为数值表示的方法。这些数值表示可以被计算机轻松处理和分析,从而帮助我们解决各种问题。
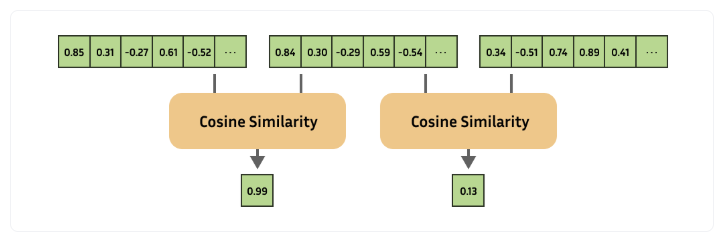
现代的嵌入模型通常包含几个关键步骤,这些步骤被称为“推理”(Inference)。
- 分词器(Tokenizer):将文本切分成一个个“词”或“子词”,这些“词”是模型能够理解的基本单位。
- 编码器(Encoder):这是模型的核心部分,通常是一个带有注意力机制的语言模型。它会根据上下文计算每个“词”的嵌入向量。
- 池化器(Pooler):将所有“词”的嵌入向量合并成一个整体的文本嵌入向量。
例如,单词“bank”在不同的上下文中(如“河岸”或“银行”)会有不同的嵌入向量,因为编码器会根据上下文来调整它的含义。
虽然带有大量注意力层的大模型能够生成高质量的嵌入向量,但它们的计算成本非常高。在推理过程中,编码器几乎占据了所有计算时间,导致速度非常慢。
静态嵌入是一种不依赖于复杂注意力模型的嵌入方法。它通过预先计算好的“词”嵌入向量来实现快速推理。
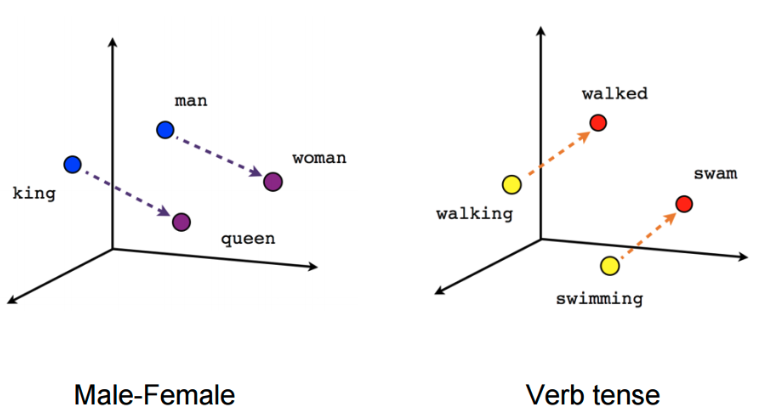
早在 Transformer 架构出现之前,静态嵌入就已经被广泛使用了。常见的静态嵌入模型包括 GLoVe 和 word2vec。最近,Model2Vec 这种技术可以将预训练的嵌入模型转换为静态嵌入模型,进一步提升了效率。
在静态嵌入模型中,编码器的步骤非常简单:只需要根据输入的“词”查找预先计算好的嵌入向量即可。这样一来,推理速度可以提升几个数量级,而质量损失却非常小。
重新定义静态嵌入模型
通过引入对比学习损失函数(Contrastive Learning Loss Function)和嵌套表示学习(Matryoshka Representation Learning),成功地让静态嵌入模型在速度和性能上实现了双重突破。
对比学习是一种强大的训练技术,它通过将相似的样本拉近、不相似的样本推远,来优化嵌入向量的表示。在我们的方法中,对比学习损失函数是提升静态嵌入模型性能的核心。
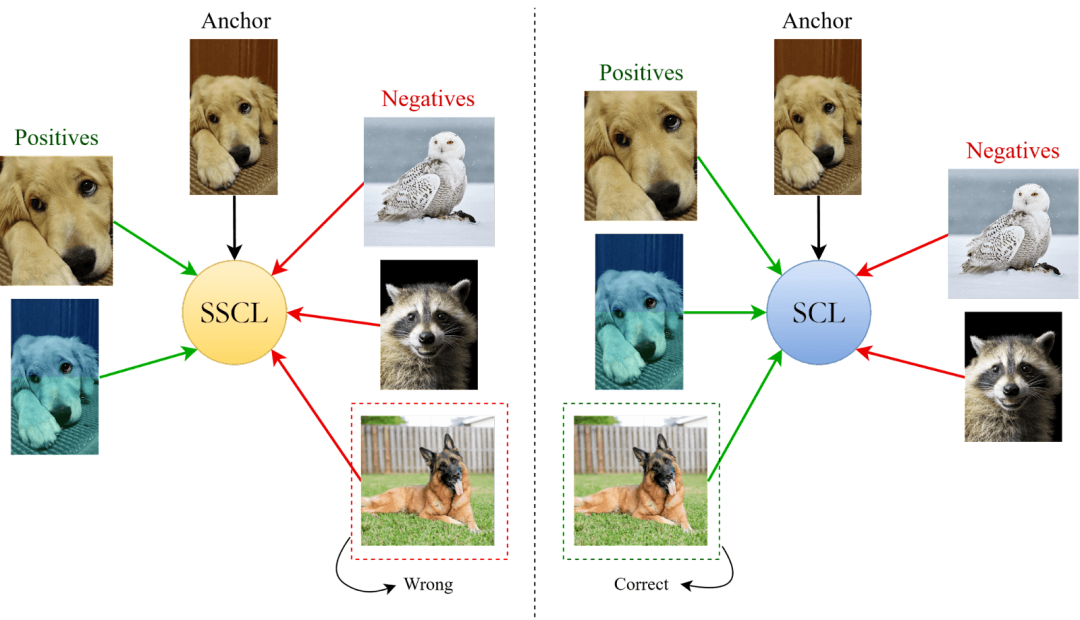
除了对比学习,我们还引入了嵌套表示学习(Matryoshka Representation Learning)。这是一种非常巧妙的技术,它允许我们使用嵌入向量的截断版本,从而进一步提升模型的推理速度。
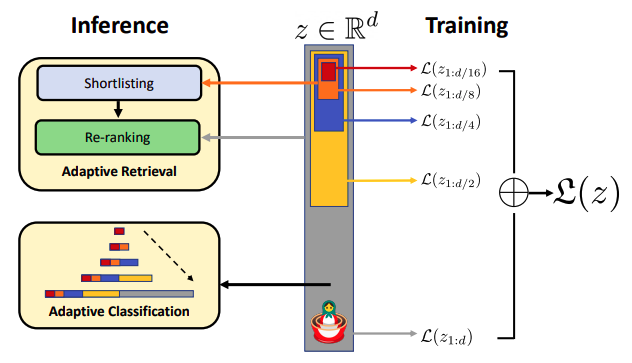
想象一下,一个嵌入向量就像一个俄罗斯套娃(Matryoshka),我们可以根据需要选择使用完整的向量,或者只使用其中的一部分。通过这种方式,我们可以在不牺牲太多性能的情况下,显著减少计算量,让模型运行得更快。
训练细节
借助 Sentence Transformers 这一强大的工具,我们可以将训练过程拆解为几个关键组件。
① 数据集(Dataset)
② 损失函数(Loss Function)
③ 训练参数(Training Arguments,可选)
④ 评估器(Evaluator,可选)
⑤ 训练器(Trainer)
模型选择
我们选择了 StaticEmbedding 模块。这个模块的核心优势在于它的高效性,它通过避免填充(padding)和高效的前向传播方法来计算和池化嵌入向量。简单来说,它就像一个经过优化的 PyTorch EmbeddingBag,本质上是一个高效的嵌入表(即嵌入向量的查找表),并结合了平均池化操作。
SentenceTransformer(
(0): StaticEmbedding(
(embedding): EmbeddingBag(30522, 1024, mode='mean')
)
)嵌入模型的应用场景大致可以分为两类:检索任务和通用任务(如分类、聚类、语义相似性等)。为了满足这些不同的需求,我们决定分别训练两个模型:一个专注于检索的单语模型,以及一个面向通用相似性任务的多语种模型。
- English Retrieval
在检索任务中,模型需要快速准确地从大量文本中找到与查询最相关的文档。然而,多语言检索的训练数据相对有限,因此我们决定专注于英语检索模型。
from sentence_transformers import SentenceTransformer
from sentence_transformers.models import StaticEmbedding
from tokenizers import Tokenizer
tokenizer = Tokenizer.from_pretrained("google-bert/bert-base-uncased")
static_embedding = StaticEmbedding(tokenizer, embedding_dim=1024)
model = SentenceTransformer(modules=[static_embedding])- Multilingual Similarity
与检索模型不同,通用相似性模型需要处理多种语言,并且要适应各种任务(如分类、聚类、语义相似性等)。
from sentence_transformers import SentenceTransformer
from sentence_transformers.models import StaticEmbedding
from tokenizers import Tokenizer
tokenizer = Tokenizer.from_pretrained("google-bert/bert-base-multilingual-uncased")
static_embedding = StaticEmbedding(tokenizer, embedding_dim=1024)
model = SentenceTransformer(modules=[static_embedding])损失函数的选择
在 Sentence Transformers 中,损失函数必须与训练数据的格式相匹配。根据数据的不同格式,我们可以选择不同的损失函数。我们的数据主要有以下几种格式:
- (anchor, positive) 对:没有标签
- (anchor, positive, negative) 三元组:没有标签
- (anchor, positive, negative_1, ..., negative_n) 元组:没有标签
此外还有三种优秀的损失函数:
- MultipleNegativesRankingLoss (MNRL)
MNRL 是一种广泛使用的损失函数,也被称为“批内负样本损失”或 InfoNCE 损失。它的核心思想是:给定一个锚点(例如一个问题),模型需要从所有正样本和负样本(例如所有答案)中,为锚点分配最高的相似性分数给对应的正样本。
如果提供额外的负样本,它们将作为“批内负样本”,帮助模型更好地“挑选”正确的正样本。负样本越难区分,模型的性能就会越强。因此,较大的批量大小会增加批内负样本的数量,从而提升模型性能(在一定范围内)。
- CachedMultipleNegativesRankingLoss (CMNRL)
CMNRL 是 MNRL 的扩展版本,它通过 GradCache 技术实现了在不增加内存消耗的情况下,任意增加批量大小。这种方法特别适合内存有限的场景。
如果你的硬件已经能够支持足够大的批量大小(例如使用 MNRL),那么可以直接使用 MNRL,以节省 CMNRL 带来的额外 20% 训练时间成本。
- GISTEmbedLoss (GIST)
GIST 是 MNRL 的另一种扩展版本,它通过一个引导的 Sentence Transformer 模型来过滤潜在的假负样本。假负样本可能会对模型性能产生负面影响,而真正的难负样本(与正样本非常接近但不完全相同)则有助于提升性能。因此,这种过滤需要非常谨慎地处理。
在我们的项目中,我们选择了 MultipleNegativesRankingLoss (MNRL) ,原因如下:
1. 硬件限制:我们的静态嵌入模型非常轻量级,可以在单个 RTX 3090(24GB 内存)上轻松处理 2048 个样本的批量大小。因此,我们不需要使用 CMNRL 来扩展批量大小。
2. 训练效率:由于我们的模型训练速度非常快,使用 GIST 的引导机制会显著降低训练速度。因此,我们选择了简单高效的 MNRL。
from sentence_transformers.losses import MultipleNegativesRankingLoss
# Prepare a model to train
tokenizer = Tokenizer.from_pretrained("google-bert/bert-base-uncased")
static_embedding = StaticEmbedding(tokenizer, embedding_dim=1024)
model = SentenceTransformer(modules=[static_embedding])
# Initialize the MNRL loss given the model
loss = MultipleNegativesRankingLoss(model)
MatryoshkaLoss 是 Sentence Transformers 提供的一种损失修饰器,它可以在标准损失函数的基础上,让模型学习如何在嵌入向量的不同维度上存储信息。具体来说,MatryoshkaLoss 会要求模型在以下几种维度上同时优化:
- 完整的嵌入维度:模型需要在标准的嵌入维度上表现良好。
- 截断的嵌入维度:模型还需要在截断后的维度上保持性能。
from sentence_transformers import SentenceTransformer
from sentence_transformers.losses import MultipleNegativesRankingLoss, MatryoshkaLoss
# Prepare a model to train
tokenizer = Tokenizer.from_pretrained("google-bert/bert-base-uncased")
static_embedding = StaticEmbedding(tokenizer, embedding_dim=1024)
model = SentenceTransformer(modules=[static_embedding])
# Initialize the MNRL loss given the model
base_loss = MultipleNegativesRankingLoss(model)
loss = MatryoshkaLoss(model, base_loss, matryoshka_dims=[1024, 768, 512, 256, 128, 64, 32])
训练参数选择
训练轮数:num_train_epochs = 1:我们选择了仅训练 1 个轮次。这听起来可能有些意外,但考虑到我们有足够的数据,重复训练相同的样本并不会带来太多额外的收益。
批量大小:per_device_train_batch_size/per_device_eval_batch_size = 2048:我们选择了 2048 作为训练和评估的批量大小。这个大小能够在我们的硬件(RTX 3090)上轻松运行,同时也能充分利用 GPU 的计算能力。
学习率:learning_rate = 2e-1:我们选择了一个相对较高的学习率 2e-1。这比传统的嵌入模型训练(通常使用 2e-5)要大得多。
预热比例:warmup_ratio = 0.1:我们选择了 10% 的预热比例。预热策略可以帮助模型在训练初期逐渐适应高学习率,从而避免过早收敛或震荡。
bf16 = True:如果硬件支持,我们推荐使用 bf16(混合精度训练)。bf16 不仅可以加速训练,还能减少内存占用。
batch_sampler = BatchSamplers.NO_DUPLICATES:对于使用批内负样本的损失函数(如 MNRL),避免批次内的重复样本是非常重要的。重复样本可能会导致假负样本的出现,从而削弱模型的性能。
多数据集采样器:multi_dataset_batch_sampler = MultiDatasetBatchSamplers.PROPORTIONAL:在多数据集训练时,不同数据集的大小可能不同。我们选择了 按比例采样 的策略,确保每个数据集的样本都能被充分利用,即使这会导致数据分布不完全均匀。
run_name = "static-retrieval-mrl-en-v1"
# or
# run_name = "static-similarity-mrl-multilingual-v1"
args = SentenceTransformerTrainingArguments(
# Required parameter:
output_dir=f"models/{run_name}",
# Optional training parameters:
num_train_epochs=1,
per_device_train_batch_size=2048,
per_device_eval_batch_size=2048,
learning_rate=2e-1,
warmup_ratio=0.1,
fp16=False, # Set to False if you get an error that your GPU can't run on FP16
bf16=True, # Set to True if you have a GPU that supports BF16
batch_sampler=BatchSamplers.NO_DUPLICATES, # MultipleNegativesRankingLoss benefits from no duplicate samples in a batch
multi_dataset_batch_sampler=MultiDatasetBatchSamplers.PROPORTIONAL,
# Optional tracking/debugging parameters:
eval_strategy="steps",
eval_steps=1000,
save_strategy="steps",
save_steps=1000,
save_total_limit=2,
logging_steps=1000,
logging_first_step=True,
run_name=run_name, # Used if `wandb`, `tensorboard`, or `neptune`, etc. is installed
)选择评估器
训练损失虽然重要,但它更多地反映了模型在训练数据上的拟合程度。然而,我们真正关心的是模型在实际任务中的表现,比如检索任务中的 NDCG(归一化折损累计增益)、MAP(平均精度均值)、MRR(平均倒数排名),或者语义相似性任务中的 Spearman 相关性,以及三元组任务中的 Triplet 准确率。
在选择评估器时,我们特别关注了 NanoBEIREvaluator。这是一个专门为检索任务设计的评估器,能够快速运行在 NanoBEIR 数据集 上的信息检索基准测试。
简单高效:NanoBEIREvaluator 能够快速运行,适合在训练过程中频繁评估模型性能。
指标丰富:它提供了多种信息检索指标,如 NDCG、MAP 和 MRR,能够全面反映模型在检索任务中的表现。
与 MTEB Leaderboard 对齐:NanoBEIR 数据集是 MTEB Leaderboard 中检索任务的简化版本,使用 NanoBEIREvaluator 可以让我们更好地与社区中的其他模型进行对比。
from sentence_transformers import SentenceTransformer
from sentence_transformers.evaluation import NanoBEIREvaluator
# Load an example pre-trained model to finetune further
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
# Initialize the NanoBEIR Evaluator
evaluator = NanoBEIREvaluator()
# Run it on any Sentence Transformer model
evaluator(model)模型表现
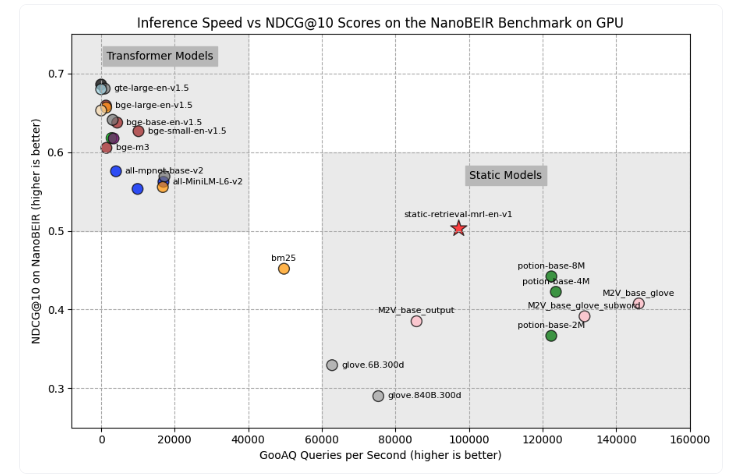
GPU速度
CPU速度
Matryoshka 维度
模型总结
在过去的探索中,我们从创意构思到模型完成,经历了多个步骤,并详细记录了两个最终模型——static-retrieval-mrl-en-v1(英语检索模型)和 static-similarity-mrl-multilingual-v1(多语言相似性模型)的训练和评估过程。这些模型不仅在性能上表现出色,还在推理速度上展现了巨大的优势。
在推理速度方面,静态嵌入模型的表现更是令人惊叹:
- 在 GPU 上,静态嵌入模型比传统模型快 10-25倍。
- 在 CPU 上,静态嵌入模型比传统模型快 100-400倍。
通过使用 Matryoshka 损失函数,我们能够在不损失太多性能的情况下,显著减小嵌入向量的维度。这不仅进一步提升了模型的推理速度,还为下游任务提供了更高的灵活性。
- static-similarity-mrl-multilingual-v1 在英语语义相似性任务(STS)中,将嵌入向量缩小 4倍,仅导致 0.56% 的性能下降。
- static-retrieval-mrl-en-v1 在英语检索任务中,将嵌入向量缩小 2倍,仅导致 1.47% 的性能下降。
本文转自:Coggle数据科学,转载此文目的在于传递更多信息,版权归原作者所有。如不支持转载,请联系小编demi@eetrend.com删除。





