许多人经常难以理解Bagging和Boosting的核心要点。
本文通过动画展示了这两种技术的内部工作原理:
简而言之,集成方法将多个模型结合在一起以构建一个更强大的模型。
它们基本上是建立在这样一个思想之上的,即通过汇总多个模型的预测结果,可以减轻各个单独模型的缺陷。

集成方法主要使用两种不同的策略构建:
- 装袋(Bagging)
- 提升(Boosting)
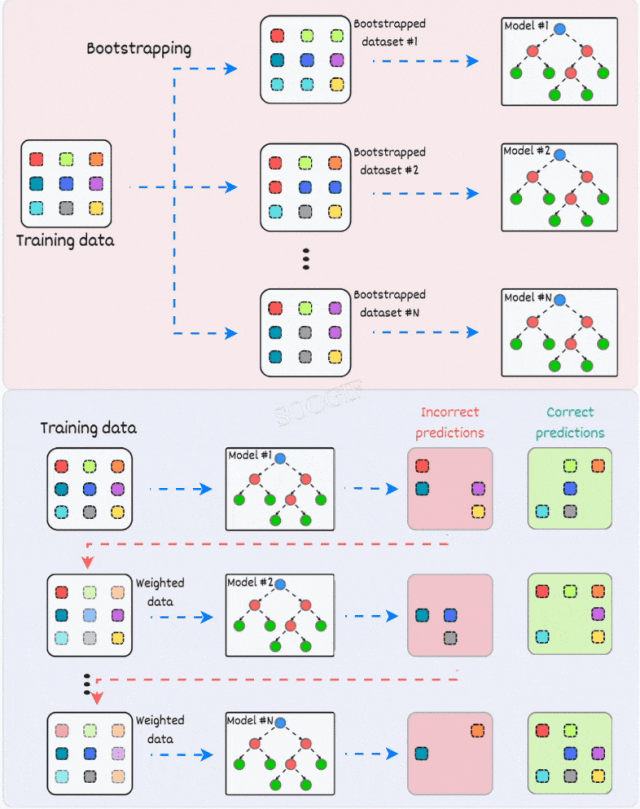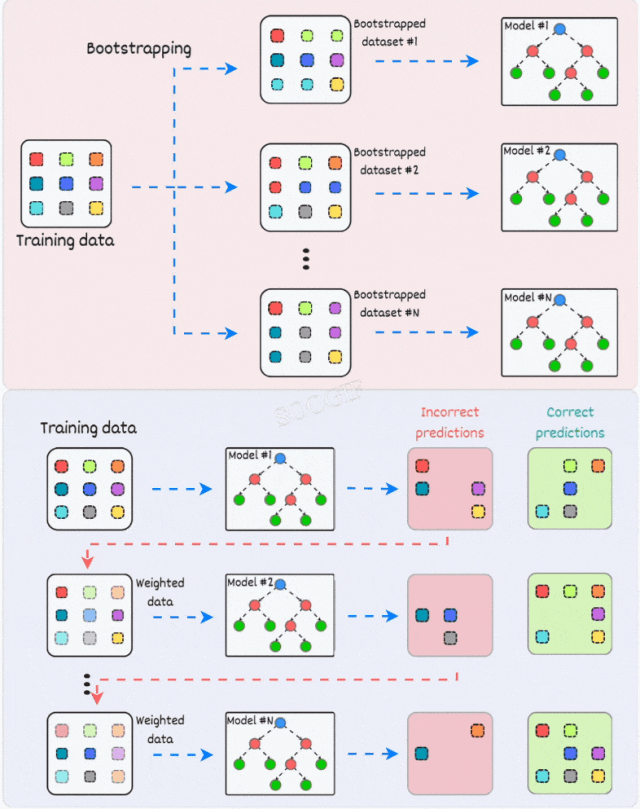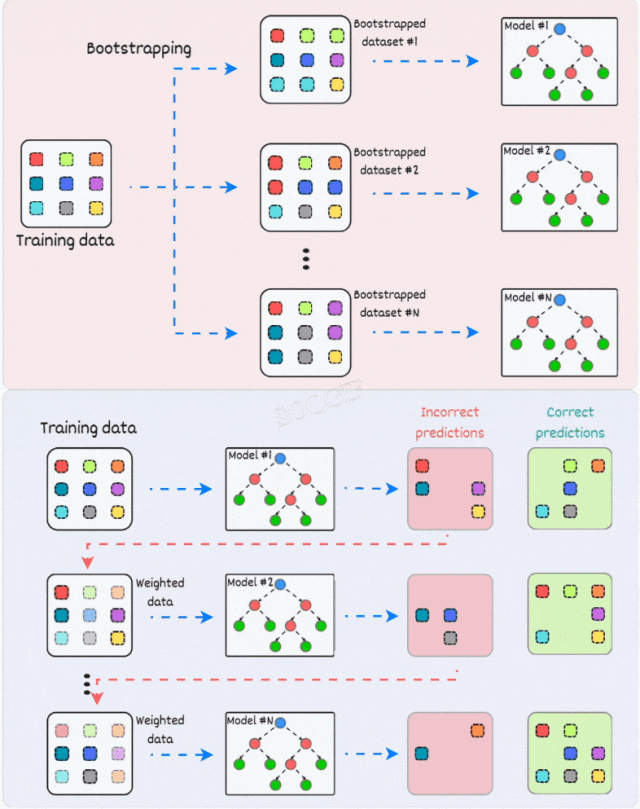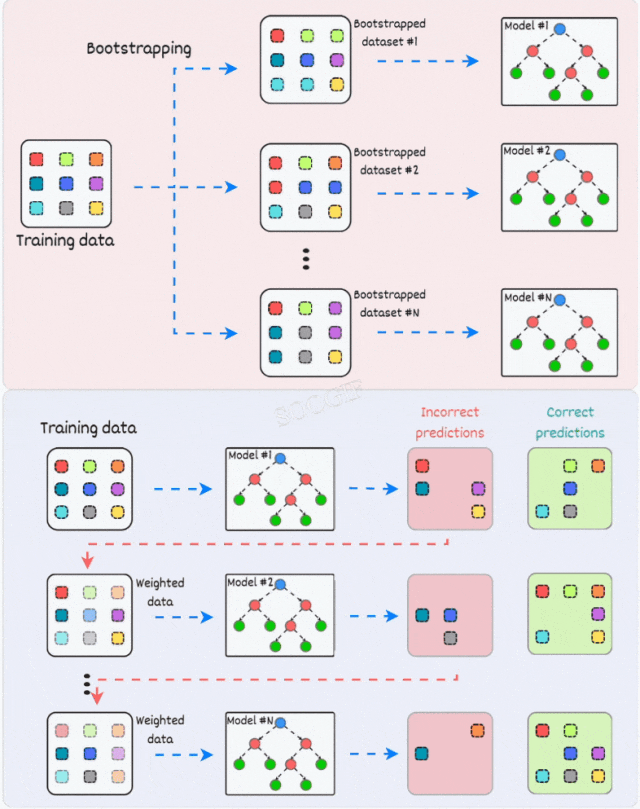
1)Bagging
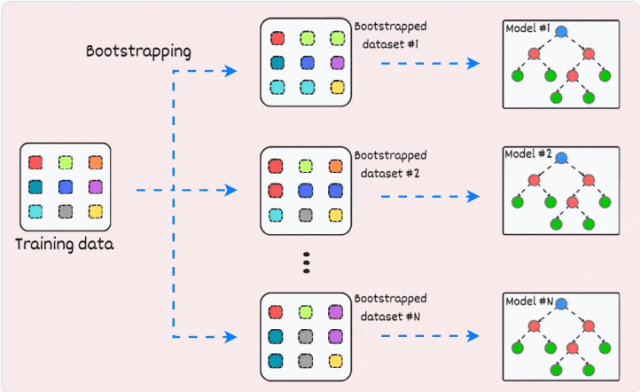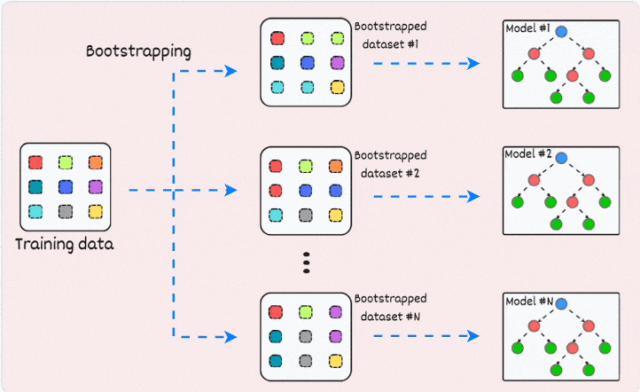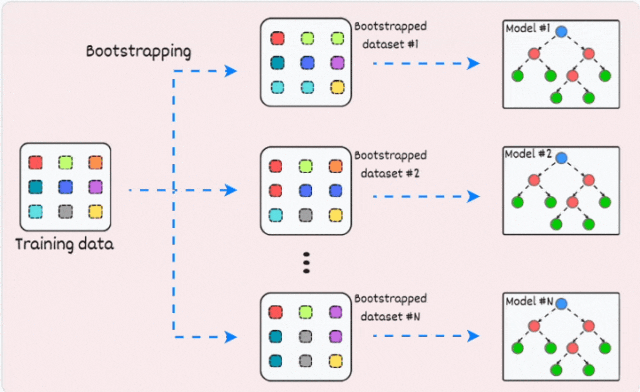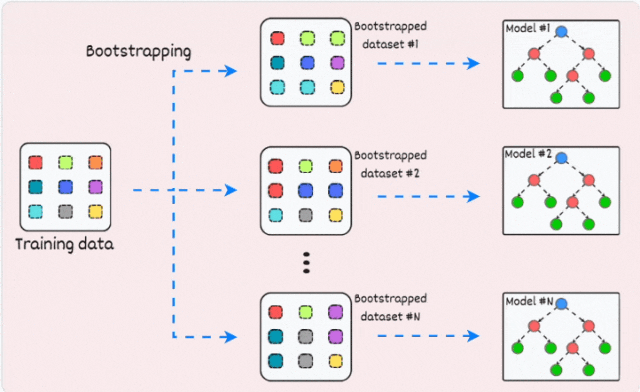
Bagging通过以下步骤实现:
- 用有放回地抽样数据创建不同的数据子集(这被称为自助法,bootstrapping)。
- 针对每个子集训练一个模型。
- 聚合所有模型的预测结果以获取最终的预测。
一些常用的利用装袋策略的模型包括:
- Random Forests
- Extra Trees
2)Boosting:
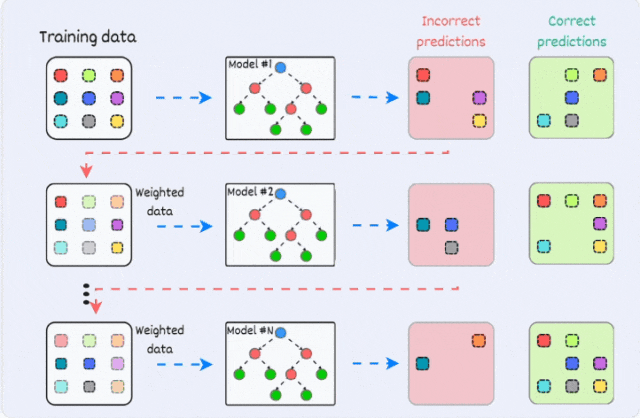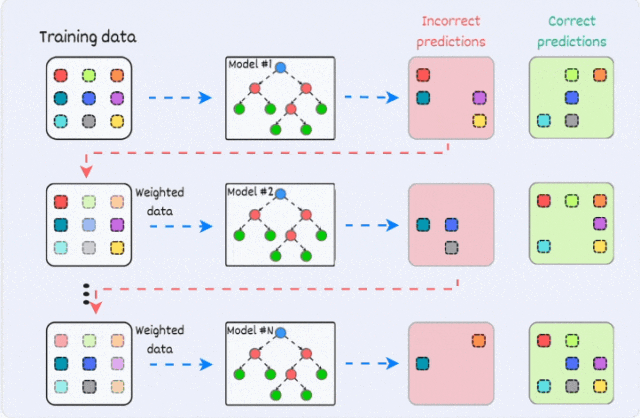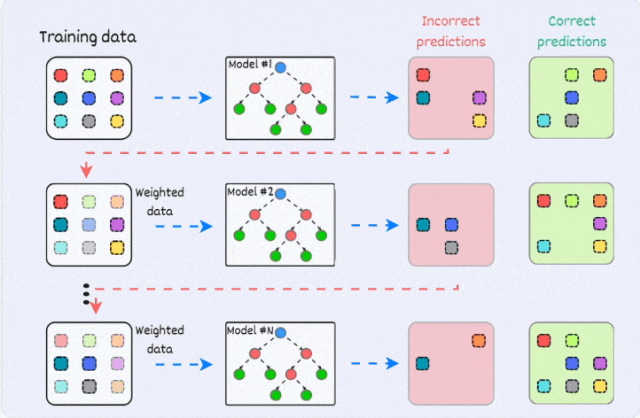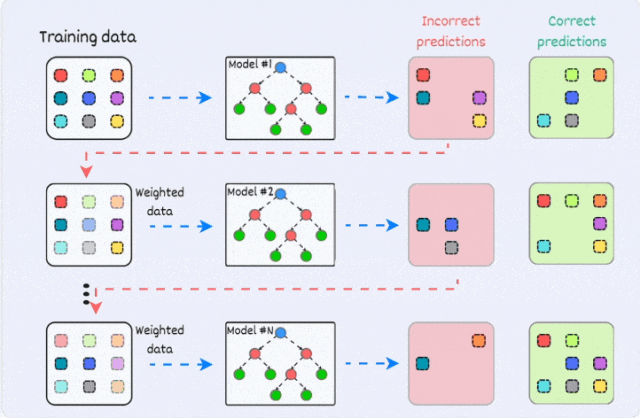
Boosting通过以下步骤实现:
- Boosting是一个迭代训练过程。
- 后续模型更加关注前一个模型中被错误分类的样本。
- 最终的预测是所有模型预测的加权组合。
一些常用的利用提升策略的模型包括:
- XGBoost
- AdaBoost等
总的来说,集成模型相较于单个模型显著提升了预测性能。
它们通常更加健壮,对未见数据泛化能力更好,并且更不容易过拟合。
本文转自:小Z的科研日常,转载此文目的在于传递更多信息,版权归原作者所有。





