在过去的几年中,时间序列预测领域的经典参数化(自回归)方法在很大程度上被复杂的深度学习框架所取代,例如DeepGlo或LSTNet。这些新颖的基于深度学习的方法不仅被认为优于传统方法,如ARIMA,以及简单的机器学习模型,如GBRT,同时也提高了人们对机器学习领域时间序列预测模型的期望,认为需要依靠深度学习才能提供最先进的预测结果。
然而,我们需要将机器学习的各个研究领域,深度学习方法的成就需要定期与简单但有效的模型进行比较,以保持各自研究领域进展的真实性。除了时间序列预测模型的日益复杂化,另一个动机是目前的研究对基于深度学习的方法过于偏重,限制了针对实际应用中高度多样化问题的解决方案的多样性。
https://arxiv.org/pdf/2101.02118
本文围绕以下两个研究问题进行:
1. 在时间序列预测的基于窗口的学习框架中,仔细配置GBRT模型(决策树回归模型)的输入和输出结构有何效果?
2. 一个简单但配置良好的GBRT模型与最先进的深度学习时间序列预测框架相比表现如何?
评测数据集
| 数据集 | 时间序列数量 (n) | 时间序列长度 (T) | 采样率 (s) | 目标通道数量 (L) | 辅助通道数量 (M) | 预测窗口大小 (h) | 训练时间点数量 (t0) | 测试时间点数量 (τ) |
|---|---|---|---|---|---|---|---|---|
| Electricity | 70 | 26,136 | 每小时 | 1 | 0 | 24 | 25,968 | 168 |
| Traffic | 90 | 10,560 | 每小时 | 1 | 0 | 24 | 10,392 | 168 |
| ElectricityV2 | 370 | 6,000 | 每小时 | 1 | 0 | 24 | 5,832 | 168 |
| TrafficV2 | 963 | 4,151 | 每小时 | 1 | 0 | 24 | 3,983 | 168 |
| PeMSD7(M) | 228 | 12,672 | 每5分钟 | 1 | 0 | 9 | 11,232 | 1,440 |
| Exchange-Rate | 8 | 7,536 | 每天 | 1 | 0 | 24 | 6,048 | 1,488 |
| Solar-Energy | 137 | 52,600 | 每10分钟 | 1 | 0 | 24 | 42,048 | 10,512 |
| Beijing PM2.5 | 1 | 43,824 | 每小时 | 1 | 16 | 1, 3, 6 | 35,064 | 8,760 |
| Urban Air Quality | 1 | 2,891,387 | 每小时 | 1 | 16 | 6 | 1,816,285 | 1,075,102 |
| SML 2010 | 1 | 4,137 | 每分钟 | 1 | 26 | 1 | 3,600 | 537 |
| NASDAQ 100 | 1 | 40,560 | 每分钟 | 1 | 81 | 1 | 37,830 | 2,730 |
基准模型GBRT
将梯度提升回归树(GBRT)转化为基于窗口的回归框架,其次对模型的输入和输出结构进行特征工程提升,使其能够最大限度地从额外的上下文信息中受益,将这种简单的机器学习方法提升到竞争性DNN时间序列预测模型的标准。
基于窗口的输入设置
为了提高GBRT模型的预测性能,我们采用了一种基于窗口的输入设置。这个方法可以更好地利用时间序列数据的特性。

数据转换步骤
1. 创建窗口:
- 将原始的时间序列数据分割成多个小的时间窗口。每个窗口包含连续的时间点数据。
- 比如说,如果我们有一年的每日气温数据,我们可以把它分成每个包含30天的窗口。
2. 扁平化窗口:
- 每个窗口包含多个时间点的数据,我们需要把这些多维的数据转换为一维向量。
- 具体来说,我们把每个时间点的目标值(例如气温)和协变量(例如日期、湿度等)拼接在一起形成一个长向量。
- 比如,一个包含5天数据的窗口,每天有温度和湿度两个值,这个窗口的数据可以转换为一个包含10个数的一维向量。
3. 处理协变量:
- 在每个窗口中,我们选择最后一天的协变量(如湿度)作为整个窗口的代表。
- 这样我们可以减少输入数据的复杂性,同时保持对当前时间点的上下文信息。
4. 多输出预测:
- 对于未来的预测,我们希望预测多个未来的时间点,而不是单独预测每一个时间点。
- 为了实现这一点,我们使用多输出的GBRT模型,这样模型可以同时预测多个时间点的值。
- 例如,如果我们希望预测未来5天的温度,模型会同时输出这5天的预测值。
深度时间序列预测方法
*Temporal Regularized Matrix Factorization (TRMF)*
模型基于矩阵分解,具有高度可扩展性,因为它能够对数据中的全局结构进行建模。虽然是本研究中较早的模型之一,但它只能捕捉时间序列数据中的线性依赖关系,尽管如此,它仍然显示出很有竞争力的结果。
*Long- and Short-term Time-series Network (LSTNet)*
模型强调了局部多变量模式(通过卷积层建模)和长期依赖关系(通过递归网络结构捕捉)。LSTNet原本有两个版本:“LSTNet-Skip”和“LSTNet-Attn”。由于“LSTNet-Attn”不可重现,我们在后续实验中评估了“LSTNet-Skip”。
Dual-Stage Attention-Based RNN (DARNN)
首先通过输入注意机制传递模型输入,然后采用带有额外时间注意机制的编码器-解码器模型。该模型最初在两个多变量数据集上进行了评估,但由于其对单变量数据集的直接适用性,后续也有部分应用。
*Deep Global Local Forecaster (DeepGlo)*
模型基于全局矩阵分解结构,由时间卷积网络正则化。该模型包含从日期和时间戳派生的额外通道,最初在单变量数据集上进行评估。
Temporal Fusion Transformer (TFT)
结合了用于局部处理的递归层和捕捉数据长期依赖关系的自注意层。模型不仅能够在学习过程中动态关注相关特征,还能够通过门控机制抑制那些被认为不相关的特征。
*DeepAR*
自回归概率RNN模型,通过时间和分类协变量来估计时间序列的参数分布。由于DeepAR的开源实现(GluonTS )。
*Deep State Space Model (DeepState)*
概率生成模型,学习使用RNN参数化线性状态空间模型。与DeepAR类似,开源实现技术上可以通过GluonTS 获得。
Deep Air Quality Forecasting Framework (DAQFF)
由两个阶段的特征表示组成:数据首先通过三个1D卷积层,然后是两个双向LSTM层,最后通过线性层进行预测。正如模型名称所表明的,这个框架是专门为预测空气质量而构建的,因此在表1中列出的相应多变量数据集上进行了评估。
模型性能对比
单变量时间序列预测实验结果
单变量时间序列预测的目标是基于目标变量的历史数据预测未来的单个目标变量。
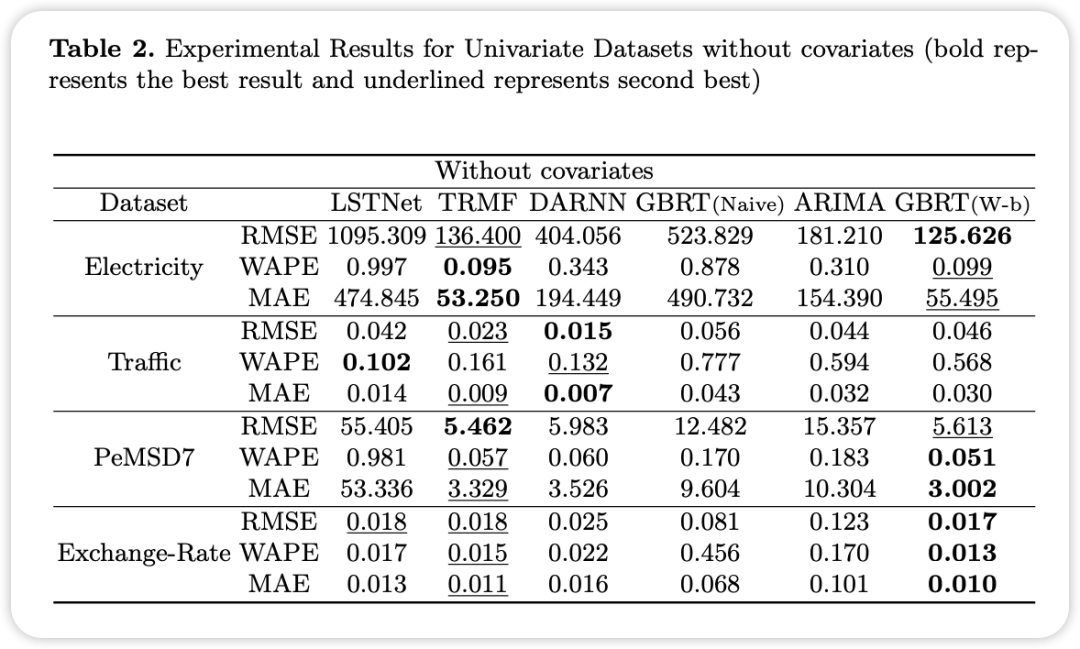
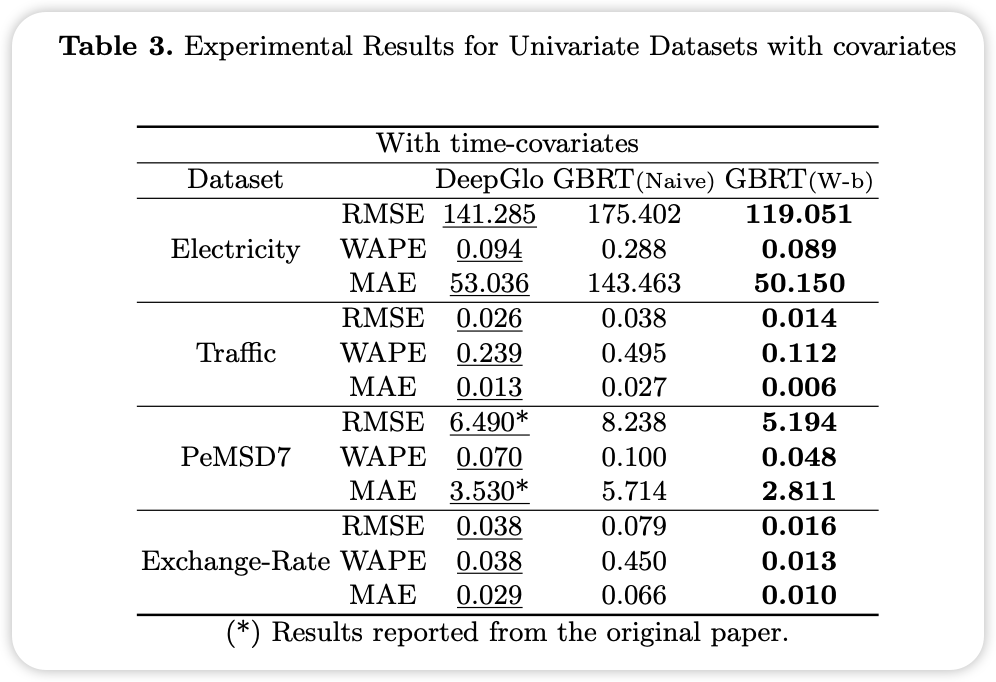
整体结果显示,基于窗口的GBRT在所有模型中表现出强劲的竞争力。
多变量时间序列预测实验结果
在多变量时间序列预测设置中,数据集原生提供了多个特征,但只需预测一个单一的目标变量。
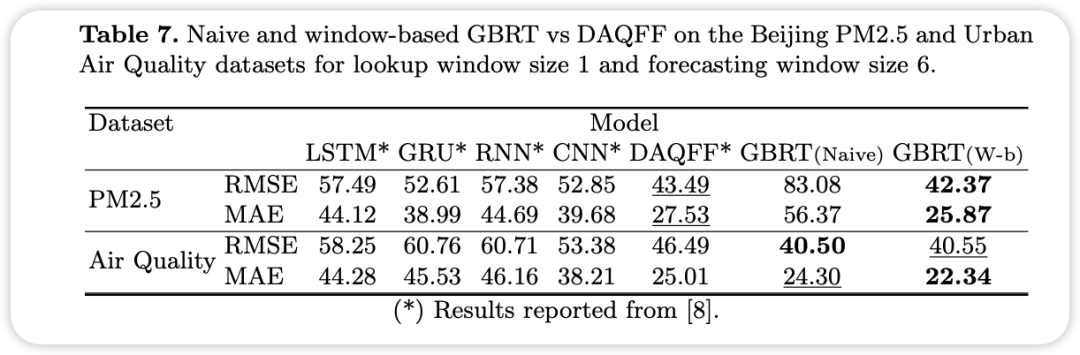
结果表明,即使是专为多变量预测设计的深度学习框架,如DARNN,也可能被配置良好的简单GBRT基线模型超越。
实验结果总结
1. 简化模型的有效性:
尽管GBRT模型在概念上较为简单,但通过适当的特征工程和窗口化输入设置,它能够在多个时间序列预测任务中取得与复杂的DNN模型相媲美的性能,甚至在某些情况下表现更优。
2. 机器学习基线的重要性:
简化的机器学习基线不应被轻视。相反,这些模型在精心配置后能够提供有竞争力的预测性能。因此,确保时间序列预测领域的进展的真实性需要对这些基础模型进行更细致的配置和优化。
3. 未来工作方向:
未来的工作可以进一步探索将这种基于窗口的输入设置应用于其他简单的机器学习模型,如多层感知器(MLP)和支持向量机(SVM)。这些模型的潜力在时间序列预测中的表现尚未完全挖掘。
本文转自:数据STUDIO,转载此文目的在于传递更多信息,版权归原作者所有。如不支持转载,请联系小编demi@eetrend.com删除。





