在模型部署时,模型的性能和耗时都非常重要。但是我们在构建模型时,往往没有考虑模型的预测速度。虽然性能优化会损害预测准确性,但更简单的模型通常运行得更快,也不容易过拟合。
预测延迟被测量为进行预测所需的经过时间。延迟通常被视为一个分布,而运维工程师通常关注此分布的给定百分位数的延迟,如50%或99%情况下的耗时。
要点1:影响延迟的因素
对于机器学习模型,影响预测延迟的主要因素是:
- 特征个数
- 数据的稀疏性
- 模型复杂度
- 特征提取耗时
其中特征是否能够并行提取 & 模型能够批量预测,对预测耗时影响非常大。
要点2:关注模型本身
由于不同的模型原理上存在区别,本质由多种原因(分支可预测性、CPU 缓存、线性代数库优化等)导致模型速度存在差异。
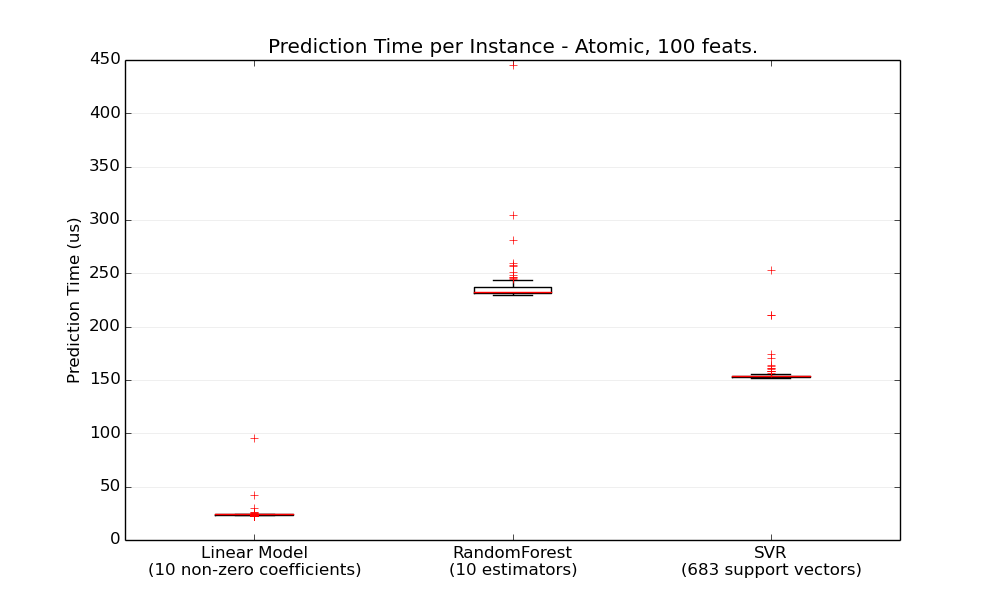
模型速度存在以下规律:
- 树模型速度比线性模型的速度慢
- SVM速度比线性模型慢
- 线性模型和贝叶斯模型速度相当
- KNN速度会受到训练数据量影响
要点3:保留有效的特征
当特征数量增加时每个示例的内存消耗也会增加,此外也会影响运算速度。当特征数量增加时,模型计算速度增加的速度不同。一般情况下,模型预测速度与特征个数成正比。
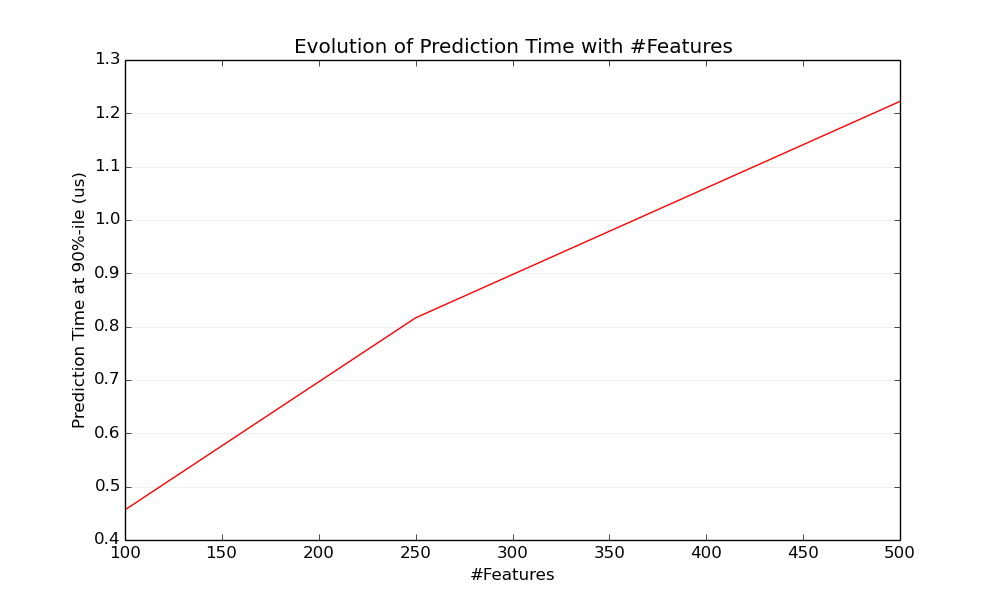
要点4:存储稀疏数据
Scipy中包含稀疏矩阵结构,只会存储非0的数据,这样占用的内存会少很少。在线性模型上使用稀疏输入可以大大加快预测速度,因为只有非零值特征会影响点积,从而影响模型预测。
使用如下代码可以统计数据的稀疏比例:
def sparsity_ratio(X):
return 1.0 - np.count_nonzero(X) / float(X.shape[0] * X.shape[1])
print("input sparsity ratio:", sparsity_ratio(X))
但对于非稀疏的数据,如果强行存储为的稀疏矩阵,反而会增加模型的预测速度。因此需要稀疏度通常非常高(非零数据只占比10%),这样才会有速度的增益。
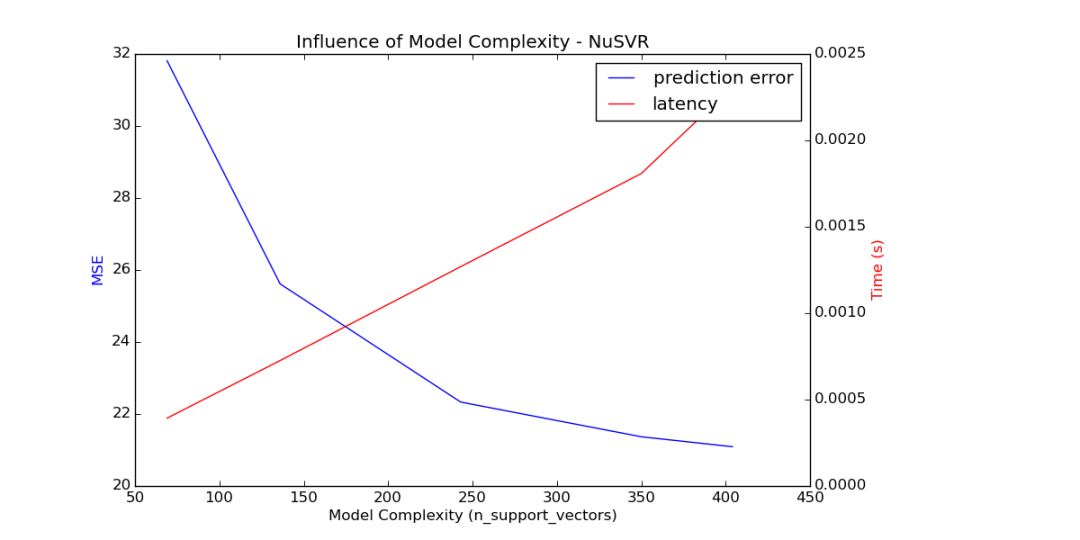
要点5:限制模型复杂度
当模型复杂性增加时,模型精度和预测延迟应该会增加。对于sklearn.linear_model中很多模型,例如Lasso、ElasticNet、SGDClassifier/Regressor、Ridge & RidgeClassifier、PassiveAgressiveClassifier/Regressor、LinearSVC和LogisticRegression在预测时应用的决策函数是相同的,因此预测延迟应该差不多。
但在线性模型中我们可以调节模型的惩罚因子,然后控制模型的稀疏性,然后进一步可以减少模型的复杂度。这里我们需要在精度和预测延迟之间进行一个折中,可以参考下面的统计逻辑。
要点6:注意底层实现
scikit-learn 依赖 Numpy/Scipy 底层函数,因此明确关注这些库的版本是有意义的。首先需要确保 Numpy 是使用优化的 BLAS / LAPACK库构建的。
可以使用以下命令显示 NumPy/SciPy/scikit-learn底层的 BLAS/LAPACK支持:
from numpy.distutils.system_info import get_info
print(get_info('blas_opt'))
print(get_info('lapack_opt'))
BLAS / LAPACK实现包括:
- Atlas
- OpenBLAS
- MKL
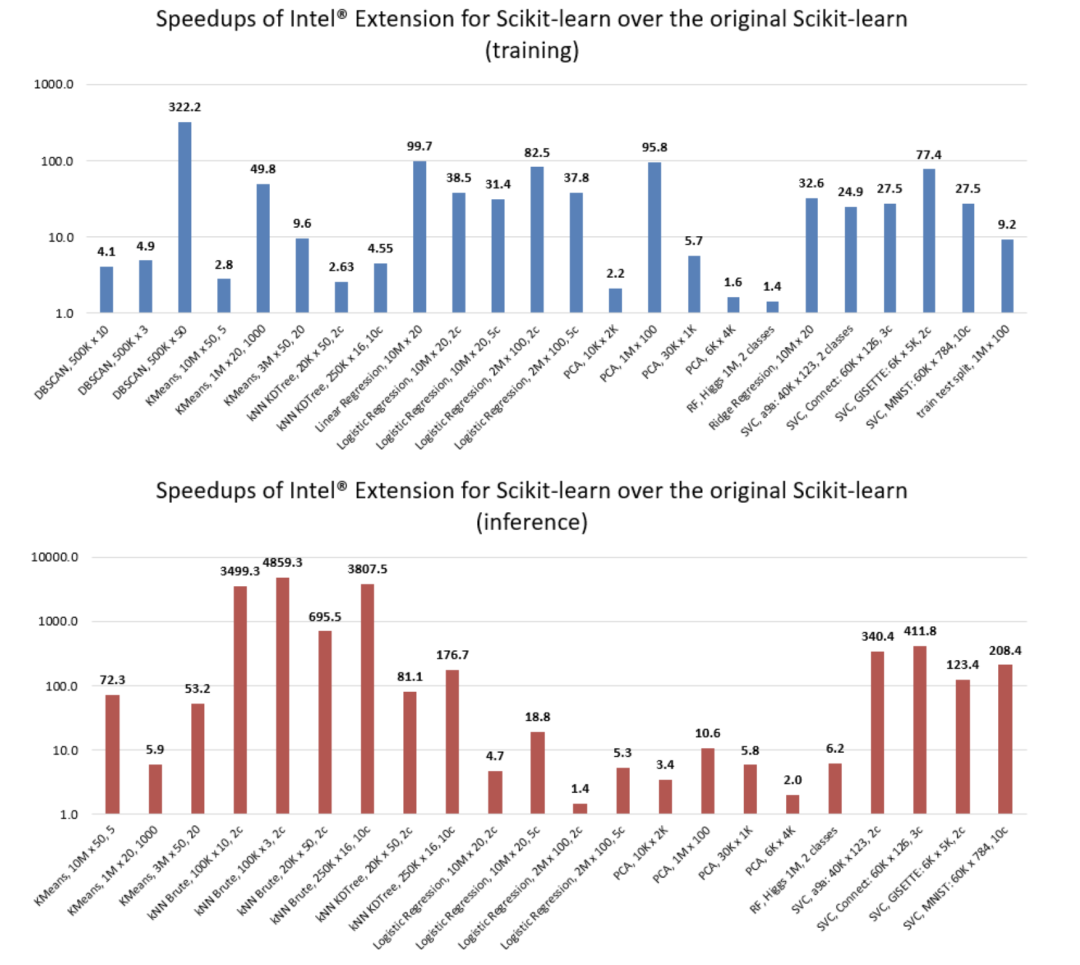
当然如果你的CPU支持scikit-learn-intelex,你也可以获得更多的加速比:
要点7:线性模型稀疏转换
scikit-learn中的线性模型支持将系数矩阵转换为稀疏格式,其内存和存储效率比Numpy高得多。
clf = SGDRegressor(penalty='elasticnet', l1_ratio=0.25)
clf.fit(X_train, y_train).sparsify()
clf.predict(X_test)
当模型和输入都是稀疏的,上述操作可以加速30%的速度,还可以对内容更加友好。
支持sparsify的模型包括:
- LogisticRegression
- LogisticRegressionCV
- PassiveAggressiveClassifier
- Perceptron
- SGDClassifier
- SGDOneClassSVM
- SGDRegressor
- LinearSVC
参考文献
https://scikit-learn.org/0.15/modules/computational_performance.html
https://scikit-learn.org/0.15/developers/performance.html
https://github.com/scikit-learn/scikit-learn/blob/main/benchmarks/bench_sparsify.py
本文转自:Coggle数据科学,转载此文目的在于传递更多信息,版权归原作者所有。如不支持转载,请联系小编demi@eetrend.com删除。





