【摘要】AI大模型的训练、推理及应用落地都需要大量的数据,其数据具有参数和数据量大、质量要求高、行业垂直属性强、资源消耗大等特点,由此带来的个人隐私泄露、数据中毒、数据篡改等数据安全风险已成为业界必须应对的重要议题。目前大模型的规模化应用还存在成本、性能、安全和商业变现等问题,其中的数据要素价值有待进一步挖掘。
AI技术发展如火如荼,以GPT、Bert、文心等为代表的大模型正引领全球新一轮科技发展潮流。大模型是基于海量数据训练、通过微调等方式适配各类下游任务,并根据用户指令生成各类内容的AI模型,具有极为宽广的应用前景。数据则是大模型发展的必备要素,也是赋能新质生产力的关键要素,大模型的数据安全风险已进入快速迭代、全面覆盖和智能化的新阶段。前文《数据安全八大发展趋势》中曾提到:“大模型应用面临着传统数据安全之外的多重安全风险,包括AI算法模型被攻击、训练数据中毒、敏感数据泄露等等”。那么,大模型中的数据有哪些特点,落地应用又存在哪些问题?以及进一步如何挖掘大模型中的数据要素价值,发展负责任、可信任、受控的人工智能?希望数篷的系列文章能给出有价值的启示和参考。
一、背景
截至2023年底,我国公开的AI大模型数量已接近240个,较2023年中翻了3倍,号称“百模大战”;根据共研产业的相关预测:预计到2024年底,我国大模型的市场规模将接近1500亿元(如图1所示)。
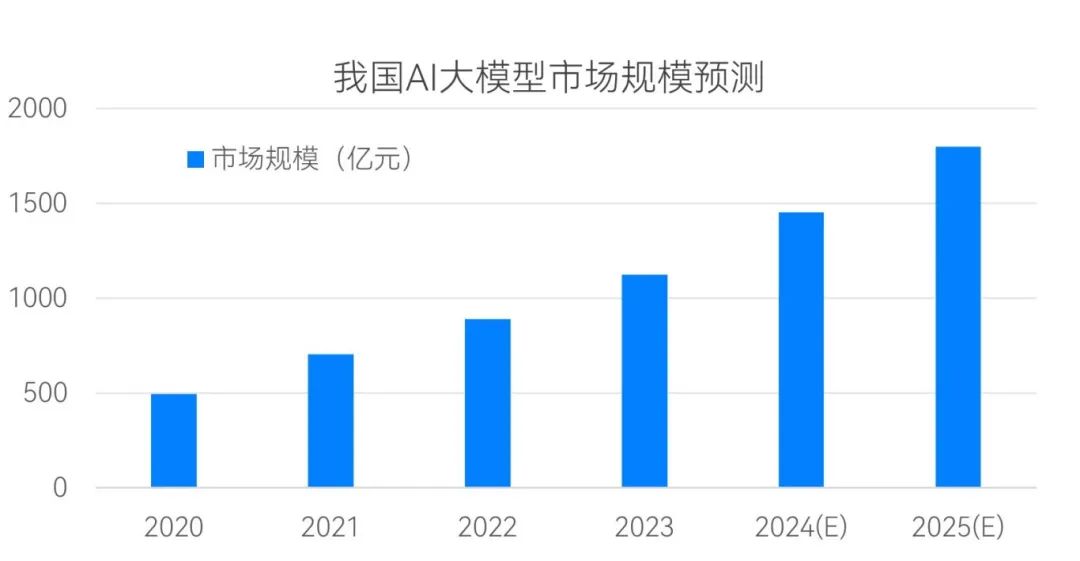
从全球来看,我国已上线和在研的大模型数量仅次于美国,中美两国之和已占到全球的80%以上,妥妥的“二八法则”。大模型在疯狂扩张的同时,数据安全和网络犯罪也达到了空前规模:2023年10月,Palo Alto Networks的事件响应团队接到的需求数量达到历史最高水平,网络犯罪分子不仅使用勒索软件攻击关键基础设施,而且还掌握了利用生成式AI等新兴技术实施攻击的新手段。
二、AI大模型的数据特点
AI大模型训练、推理及应用落地都需要大量的数据作为支撑,其数据具有参数和数据量大、质量要求高、行业垂直属性强、资源消耗大等特点,由此带来的诸如个人隐私泄露、数据中毒、数据篡改等数据安全风险已成为业界必须应对的重要议题。
大模型的“大”体现在:参数数量庞大、训练数据量大、多模态数据类型丰富。大模型拥有巨大的参数规模和深层的网络结构,通常包含数十亿到数百亿个参数,能够捕捉数据中的复杂关系,具有强大的数据表示和学习能力。大模型基于深度学习,利用“没有最大、只有更大”规模的训练数据集,不断调整参数获取更全面信息,提高模型的泛化能力,可以在未见过的新任务上也有不错的性能表现。此外,训练大模型需要多模态的数据集,包括文本、图像、语音、视频等结构化和非结构化的多种形式,数据集规模正呈爆发式增长,2018年GPT-1数据集约为4.6GB,2020年GPT-3数据集达到了753GB,ChatGPT的多模态数据集则达到45TB,相当于超万亿单词的人类语言数据集。
数据质量正成为千亿参数大模型的巨大短板。有专家曾指出:AI发展正在从“以模型为中心”加速转向“以数据为中心”。随着各种开源大模型的涌现,数据质量的重要性进一步凸显,高质量的行业数据往往决定着模型的精度与表现。仍以ChatGPT为例,从多个数据源采集到大量原始数据后,利用NLP技术对原始数据进行清洗,使用特定的过滤器去除噪声数据和无用信息,再使用数据增强技术对数据集进行扩充,增加语料库的规模和多样性,从而提高ChatGPT的泛化能力和鲁棒性。未来,通过增加书籍和科学论文等专业数据集比例、有效利用公共政务数据、对互联网数据进行开放融合等手段,可以进一步提升训练数据的质量,而这些高质量的训练数据也有望成为数据要素交易的重点对象。
通用大模型的部署重、通用能力强,但行业适配性略差、较难支撑细分行业领域和企业内部场景应用,垂直化或成未来大模型发展的必然趋势。行业垂直大模型在通用大模型的基础上,加入企业自身数据对模型精细化调整,经过大量行业数据的“投喂改造”,具有轻量化、快速部署的特点,可以应用在端侧和边缘侧。将通用大模型和垂直大模型比喻为“通才”和“专才”,前者用一个模型解决通用性的各种问题,而后者使用专用数据库对模型进行训练改造,解决特定领域的问题,改善一些模型“一本正经地胡说八道”的问题,更加精准地匹配产业链中的供给与需求。
大模型的数据对计算资源和电力资源消耗巨大。大模型具有更大的参数量和更复杂的架构,训练和推理时需要更高的计算资源,不管在本地部署还是云上分布式部署,都需要高性能GPU集群或其他专用硬件。此外,大模型算力日新月异的背后,还有对电力资源的巨大消耗:ChatGPT每天可能会消耗超过50万千瓦时的电力,来响应用户的约2亿个请求;如果生成式人工智能被广泛应用,耗电量可能会更多,Uptime Institute预测到2025年,人工智能业务在全球数据中心用电量中的占比将从2%猛增到10%,名副其实的“电老虎”!
三、AI大模型规模化应用的瓶颈问题
2023年,我国提出“重视通用人工智能发展,营造创新生态,重视防范风险”,高度重视人工智能大模型安全。随后,国家网信办等部门联合发布《生成式人工智能服务管理暂行办法》,确立了人工智能产品的安全评估规定及管理办法;配套支撑的《生成式人工智能服务安全基本要求》、《信息安全技术生成式人工智能预训练和优化训练数据安全规范》、《信息安全技术生成式人工智能人工标注安全规范》等相关标准也相继发布,维护人工智能大模型的规范应用和健康发展。2024年,国家数据局等17部门联合发布《“数据要素×”三年行动计划(2024—2026年)》,明确指出“以科学数据支持大模型开发,深入挖掘各类科学数据和科技文献,建设高质量语料库和基础科学数据集,支持开展人工智能大模型开发和训练”。
大模型要求高性能、低成本、安全可信,目前大模型在行业的规模化应用还存在以下几个问题:
1、成本问题
私有化部署的大模型,需要专用的AI芯片及GPU集群,对于数据、计算、能源资源消耗巨大,成本昂贵。面向中小企业,基于共享资源的云计算模式可能更加适合,弹性计算资源适合多租户访问、随用随训随训随取的场景,成本相对可控。此外,大模型研发需要长期投入,构建完备的训练框架、算子库和模型库,搭建生态体系、云边端推广部署和常态化运营,企业的生态成本也不容小觑。
2、性能问题
据AI Index报告称,2023年全球发布的新大型语言模型数量比上一年翻了一番,其中三分之二的模型是开源的,但性能最高的模型来自拥有封闭系统的行业参与者。因此,大模型需要持续优化算法以缩小与封闭大模型的性能差距,提升大模型“军备竞赛”中的竞争力。此外,大模型还需要结合高质量的行业数据和优化算法,解决内容质量、内容可信的问题,同时考虑大模型的可解释性和公平性等问题。
3、安全问题
大模型数据来源除了公开数据、自有数据、合成数据外,用户在与大模型的交互过程中产生的数据也成为了模型训练的语料基础,在数据的输出过程中必须确保数据安全。中小企业对于云上大模型的数据开发利用存在后顾之忧,担心大模型内部类似“黑盒”的处理过程违规收集数据,担心计算过程中的托管数据和产生的高价值敏感数据可能被平台方获取,同时也担心平台采用的多租户隔离技术存在数据泄露风险,因此不愿意分享高质量的训练数据和开发潜在的数据价值。
另一方面,企业还需警惕“模型中毒”问题,大模型数据易遭到恶意数据的“污染”,模型训练已经不再是简单的比拼数据规模和算法架构,纠错和抗干扰能力也相当重要。一些大模型的训练语料库可能包含大量虚假、色情、暴力等有害信息,存在较大的安全隐患。
基于上述安全问题,可信计算、隐私计算在大模型时代迎来全新机遇,包括可信执行环境(TEE)、多方安全计算(MPC)、联邦学习(FELE)等技术都有与大模型结合的探索机会。
4、商业变现问题
大模型的能源成本、数据成本和芯片采购成本不断攀升,在一定程度上也制约阻碍大模型的升级迭代。目前,大模型的B端应用已经出现各种定价方法,包括按时间段计费、按token计费、按查询次数计费以及包含硬件的一站式解决方案;针对C端客户,一些大模型也已开始尝试收取月费。未来,随着数据要素产业的成熟,面向大模型的高质量训练数据集有望加入数据交易的行列,多次流转进一步释放数据要素价值,降低数据拥有方和大模型平台的经营成本。各地政府鼓励的大模型产业园,旨在拉通并匹配上下游产业链的市场需求,解决大模型数据产品化、商业变现和生态构建的问题。
四、结语
综上所述,目前大模型规模化应用存在的成本、性能、安全和商业变现等问题,制约着其中数据要素价值的进一步发挥。如何将大模型中的价值数据转化为可量化、可交易、可持续增值的资产,并推动大模型产业和数据要素市场的高质量健康发展,是当前大模型平台方、数据持有方、数据使用方和数据监管方等多元主体共同关心的话题。
本文转自:安在,转载此文目的在于传递更多信息,版权归原作者所有。如不支持转载,请联系小编demi@eetrend.com删除。





