一、概览
神经网络的参数学习是一个非凸优化问题。 当使用梯度下降法来进行优化网络参数时, 参数初始值的选取十分关键 , 关系到网络的优化效率和泛化能力。 参数初始化的方式通常有以下三种:
( 1 ) 预训练初始化 : 不同的参数初始值会收敛到不同的局部最优解。 虽然这些局部最优解在训练集上的损失比较接近, 但是它们的泛化能力差异很大。 一 个好的初始值会使得网络收敛到一个泛化能力高的局部最优解 。
通常情况下 , 一个已经在大规模数据上训练过的模型可以提供一个好的参数初始值, 这种初始化方法称为 预训练初始化 ( Pre-trained Initialization )。预训练任务可以为监督学习或无监督学习任务。 由于无监督学习任务更容易获取大规模的训练数据, 因此被广泛采用。 预训练模型在目标任务上的学习过程也称为 微调 ( Fine-Tuning )。
( 2 ) 随机初始化 : 在线性模型的训练 ( 比如感知器和 Logistic 回归 ) 中 , 我们一般将参数全部初始化为 0。 但是这在神经网络的训练中会存在一些问题 . 因为如果参数都为 0 , 在第一遍前向计算时 , 所有的隐藏层神经元的激活值都相同; 在反向传播时 , 所有权重的更新也都相同 , 这样会导致隐藏层神经元没有区分性 。 这种现象也称为 对称权重 现象。 为了打破这个平衡 , 比较好的方式是对每个参数都 随机初始化 ( Random Initialization ), 使得不同神经元之间的区分性更好。
( 3 ) 固定值初始化 : 对于一些特殊的参数 , 我们可以根据经验用一个特殊的固定值来进行初始化。 比如偏置 ( Bias ) 通常用 0 来初始化 , 但是有时可以设置某些经验值以提高优化效率。
例如在 LSTM 网络的遗忘门中 , 偏置通常初始化为 1 或 2 , 使得时序上的梯度变大 . 对于使用 ReLU 的神经元 , 有时也可以将偏置设为0.01, 使得 ReLU 神经元在训练初期更容易激活 , 从而获得一定的梯度来进行误差反向传播。
虽然预训练初始化通常具有更好的收敛性和泛化性 , 但是灵活性不够 , 不能在目标任务上任意地调整网络结构。 因此 , 好的随机初始化方法对训练神经网络模型来说依然十分重要。
这里我们介绍三类常用的随机初始化方法 : 基于固定方差的参数初始化、 基于方差缩放的参数初始化和正交初始化方法。
二、基于固定方差的初始化
一种最简单的随机初始化方法是从一个固定均值 ( 通常为 0 ) 和方差 σ2 的分布中采样来生成参数的初始值。这里的“ 固定 ” 的含义是方差 σ2 为一个预设值,和神经元的输入 、 激活函数以及所在层数无关。
基于固定方差的参数初始化方法主要有以下两种:
( 1 ) 高斯分布初始化 : 使用一个高斯分布 N(0, σ2 ) 对每个参数进行随机初始化。
( 2 ) 均匀分布初始化 : 在一个给定的区间 [−r, r]内采用均匀分布来初始化参数。
在基于固定方差的随机初始化方法中 , 比较关键的是如何设置方差 σ2。 如果参数范围取的太小, 一是会导致神经元的输出过小 , 经过多层之后信号就慢慢消失了; 二是还会使得 Sigmoid 型激活函数丢失非线性的能力。 以 Sigmoid 型函数为例, 在 0 附近基本上是近似线性的 。 这样多层神经网络的优势也就不存在了。 如果参数范围取的太大, 会导致输入状态过大。 对于 Sigmoid 型激活函数来说 , 激活值变得饱和, 梯度接近于 0 , 从而导致梯度消失问题。
为了降低固定方差对网络性能以及优化效率的影响 , 基于固定方差的随机初始化方法一般需要配合 逐层归一化 来使用。
2.1 Xavier初始化
假设在一个神经网络中,第 l 层的一个神经元 a(l) , 其接收前一层的 M l−1 个神经元的输出 ai(l−1) , 1 ≤ i ≤ Ml−1:
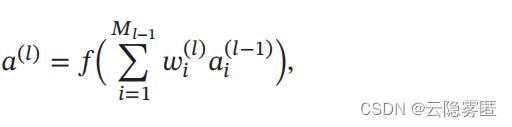
其中 f(⋅) 为激活函数,wi (l) 为参数,Ml−1 是第 l− 1 层神经元个数。 为简单起见 ,这里令激活函数f(⋅) 为恒等函数,即f(x) = x。
假设 wi (l) 和 ai (l−1) 的均值都为 0 , 并且互相独立 , 则 a (l) 的均值为:
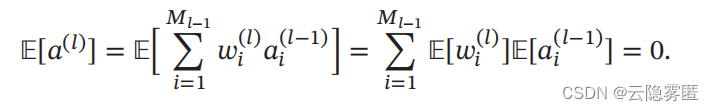
a (l) 的方差为:
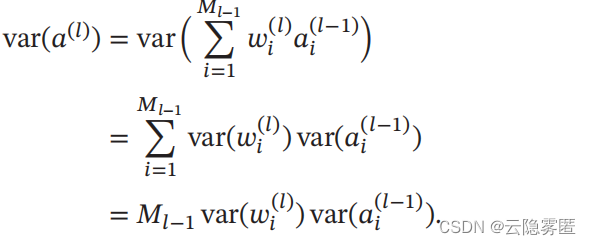
也就是说 , 输入信号的方差在经过该神经元后被放大或缩小了 M Ν−1 var (wi (Ν) ) 倍。 为了使得在经过多层网络后, 信号不被过分放大或过分减弱 , 我们尽可能保持每个神经元的输入和输出的方差一致。 这样 Ml−1 var (wi(l) ) 设为 1 比较合理 , 即:
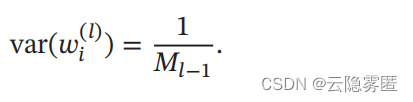
同理 , 为了使得在反向传播中 , 误差信号也不被放大或缩小 , 需要将 wi (Ν) 的方差保持为:
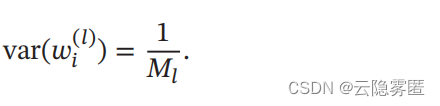
作为折中,同时考虑信号在前向和反向传播中都不被放大或缩小,可以设置:
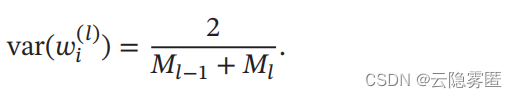
在计算出参数的理想方差后 , 可以通过高斯分布或均匀分布来随机初始化参数。 若采用高斯分布来随机初始化参数 , 连接权重 wi (l) 可以按 Ν(0, 2/Μl−1+Ml ) 的高斯分布进行初始化。若采用区间为 [−r, r] 的均匀分布来初始化 wi (l) , 则 r 的取值为√ (6 /Ml−1+Ml) 。
这种根据每层的神经元数量来自动计算初始化参数方差的方法称为 Xavier初始化 。
虽然在 Xavier 初始化中我们假设激活函数为恒等函数 , 但是 Xavier 初始化也适用于 Logistic 函数和 Tanh 函数。 这是因为神经元的参数和输入的绝对值通常比较小, 处于激活函数的线性区间。 这时 Logistic 函数和 Tanh 函数可以近似为线性函数。 由于 Logistic 函数在线性区间的斜率约为 0.25, 因此其参数初始化的方差约为16 × (2 / Ml−1+Ml) 。 在实际应用中,使用 Logistic函数或 Tanh函数的神经层通常将方差 2 / (Ml−1+Ml) 乘以一个缩放因子ρ。
2.2 He初始化
当第 l 层神经元使用 ReLU激活函数时 , 通常有一半的神经元输出为 0 , 因此其分布的方差也近似为使用恒等函数时的一半。这样 , 只考虑前向传播时 , 参数 wi (l) 的理想方差为:
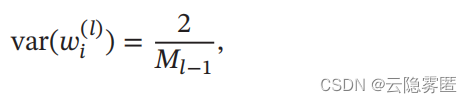
其中 M l−1 是第 l − 1 层神经元个数。 因此当使用 ReLU 激活函数时,若采用高斯分布来初始化参数
wi (l),其方差 为 2 / Ml−1 ; 若采用区间为 [−r, r] 的均匀分布来初始化参数 wi (l) , 则 r =√ (6 / Ml−1) 。 这种初始化方法称为 He初始化 。
下表 给出了 Xavier 初始化和 He 初始化的具体设置情况。

三、正交初始化
上面介绍的两种基于方差的初始化方法都是对权重矩阵中的每个参数进行独立采样。 由于采样的随机性 , 采样出来的权重矩阵依然可能存在梯度消失或梯度爆炸问题。
假设一个 L 层的等宽线性网络 ( 激活函数为恒等函数 ) 为:
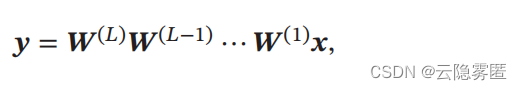
其中 W (l) ∈ RM×M (1 ≤ l ≤ L) 为神经网络的第 l 层权重矩阵。在反向传播中, 误差项δ 的反向传播公式为 δ (l−1) = (W(l) ) T δ (l)。 为了避免梯度消失或梯度爆炸问题, 我们希望误差项在反向传播中具有 范数保持性 (Norm-Preserving),即 ‖δ(l−1)‖ 2 = ‖δ (l) ‖ 2 = ‖(W (l)) T δ (l) ‖ 2。 如果我们以均值为 0、方差为 1 / M 的高斯分布来随机生成权重矩阵W (l) 中每个元素的初始值,那么当 M → ∞ 时,范数保持性成立。 但是当 M 不足够大时 , 这种对每个参数进行独立采样的初始化方式难以保证范数保持性。
因此 , 一种更加直接的方式是将 W(l) 初始化为正交矩阵,即 W (l)(W(l)) T = I, 这种方法称为 正交初始化 ( Orthogonal Initialization)。正交初始化的具体实现过程可以分为两步:
(1) 用均值为 0 、 方差为 1 的高斯分布初始化一个矩阵;
(2) 将这个矩阵用奇异值分解得到两个正交矩阵 , 并使用其中之一作为权重矩阵。
根据正交矩阵的性质 , 这个线性网络在信息的前向传播过程和误差的反向传播过程中都具有范数保持性, 从而可以避免在训练开始时就出现梯度消失或梯度爆炸现象。
当在非线性神经网络中应用正交初始化时,通常需要将正交矩阵乘以一个缩放系数ρ 。 比如当激活函数为 ReLU 时,激活函数在 0 附近的平均梯度可以近似为 0.5。 为了保持范数不变,缩放系数 ρ可以设置为 √2。
版权声明:本文为CSDN博主「云隐雾匿」的原创文章,
遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_45684362/article/details/129922676





