本文来源:深度学习初学者
报告者:姜思君,编辑:邓宏宇
摘要:
机器学习和深度学习通常需要从海量的数据中学习到其中的知识,从而应用于各种任务之中。在学习的过程中,GPU是强大而有效的计算单元,能够大幅缩减训练时间。今天的paper reading将深入这种关键设备的内部,了解其在深度学习中的运作原理。
正文:
GPU是深度学习使用的关键计算单元,大多数任务都在上面执行。虽然使用GPU实现深度学习已经成为目前的一种通用做法,但广大研究人员实际上对GPU的认知仍处于一种浅薄的层次。然而,对GPU的工作机理进行了解实际对深度学习的研究是具有促进的作用的。例如,能够提高程序运行的速度、提高程序使用GPU的利用率、帮助程序debug、在搭建网络和调参时提供硬件层面的帮助、提高研究人员的市场竞争力等。
在深入学习GPU的工作机理前,我们需要先对计算机内部程序的运行过程进行简单的了解。首先,python程序在运行前需要执行动态库的链接,将需要运行的函数导入主存中;其次计算机根据程序内部的声明,为这个程序分配一块内存空间;接着,CPU将为该进程创建相关的线程,以此逐步推进运算。
我们能够针对程序的运行过程提出几个加速的建议。首先,编写程序时可充分利用时间与空间局部性,将需要反复使用的数据尽量分配在同一内存中,尽量减少指令的变更次数,从而降低寻址耗费的时间;其次,优化程序的内存管理,提高内存的使用率,减少频繁的内存申请与释放操作,减少内存碎片的生成;再次,减少不必要的死循环,控制一些进程主动释放计算资源。
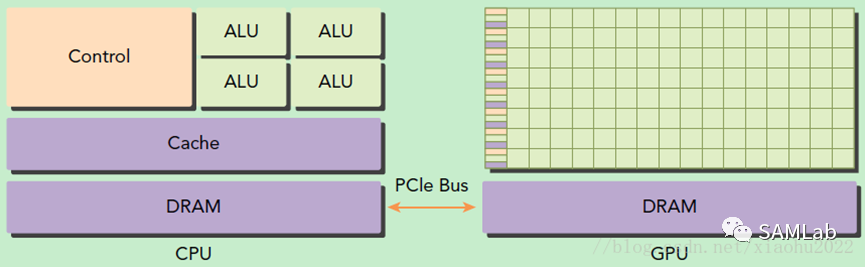
GPU和CPU是同属于计算机的计算单元,但各自的结构和强项都不相同。实际上GPU的结构相较于CPU更加简单。GPU并不是一个独立运行的计算平台,而需要与CPU协同工作,可以看成是CPU的协处理器。GPU包括更多的运算核心,但没有逻辑处理核心,因此特别适合数据并行的计算密集型任务,如大型矩阵运算。
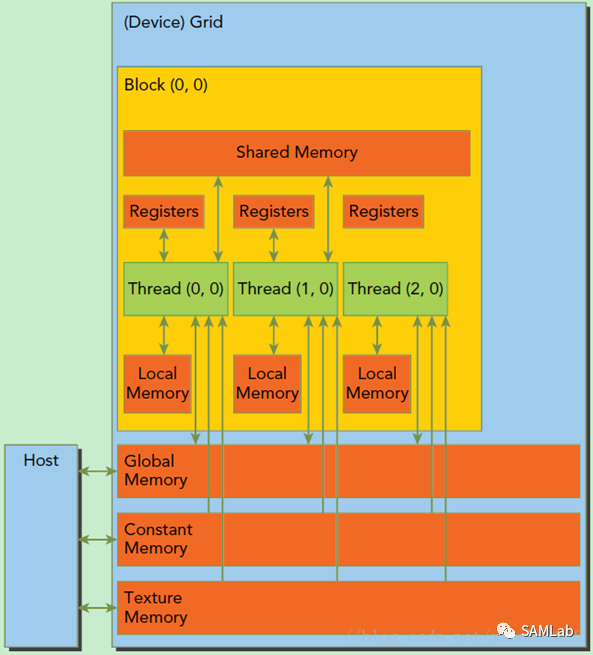
实际上,GPU在运行程序时的操作单元是一组线程,这组线程以Grid为单位,同一个Grid上的所有线程共享相同的Global Memory,用于显卡计算过程中与CPU发生的数据交换。由于GPU的操作大多是流操作,一组线程计算同一指令的设计降低了时间局部性对于GPU计算的影响。
一个Grid由多个Block构成,每个Block内包含了多个线程。具体示意图如下:

在GPU中,一个Grid将被赋予一个全局内存,允许GPU与CPU进行内存交换。而对于每个Block而言,还具有一个共享内存,允许同一Block的各个线程进行访问和写入。每个Grid还具有只读性质的固定内存和纹理内存,仅在GPU不执行指令时可由CPU导入数据,只读性质的存储能够最大限度地提高GPU的计算效率。
此外,对GPU性能影响最大的部分是信息传输的部分。该部分发生了主存与GPU显存的信息交换,从计算机组成原理来看属于主存到辅存的传输,该环节所耗费的时间从计算机层次结构来看是最长的一段时间。为提高传输效率,应用内存对齐的原理,按每个传输单元128bit的容量来规划信息传输细节,能够尽量降低信息传输对于任务执行效率的影响。
总而言之,GPU精简的指令集降低了其寻址时间;其内部每个线程单元都有对应的内存空间,减少了不同线程单元之间的读写冲突;GPU内部精准的内存划分,提高了空间的利用率,降低了内存交换的时间消耗;GPU使用多个线程资源响应同一指令,从而降低了计算延时。
但使用GPU执行程序不一定能提高程序的运算效率,由于GPU的调用需要经过主存-辅存的过程,在传输过程可能会消耗大量的时间。只有计算密集型的任务能够充分发挥GPU的告诉运算优势,而需要大量数据交换的任务并不适合在GPU上运行。
声明:本文为转载文章,转载此文目的在于传递更多信息,版权归原作者所有,如不支持转载,请联系小编demi@eetrend.com删除。





