在设计一个复杂的处理器内核时,可能会出现1000到2000个不等的bug,经验告诉我们这是事实,尽管这个数字听上去难以置信。而且并不是所有的bug都是一样的:它们的重要性和带来的后果有很大的不同。这期博文让我们来看看4种不同类型的CPU漏洞,如何找到它们?以及如果我们没有及时找到并击中它们,对用户来说会有着怎么样的后果?
类型一:验证工程师很容易发现的处理器漏洞!
类似在设计过程中忘记写入一个分号的漏洞类型非常容易发现,它通常是在编译时直接发现的。对于此类bug,除了睁大你的眼睛之外,没有其他办法来避免!
可能你会经常听到同事说"哦,这个规范的一部分没有被实现"。这其实是另一种极其容易发现的CPU漏洞,只要有一个明确的测试存在,你就可以用任何像样的测试平台找到它。在这种情况下,行使该功能的第一个简单测试将失败。那么此时处理器验证团队需要做什么?确保详尽健全的测试方式方法是一方面。另一方面,设计团队需要努力仔细阅读规范,并在开发过程中随时关注规范的任何变化。
换句话说,简单的bug是指仅仅通过运行该功能的测试就能发现。它的(坏)行为是系统性的,而不是一个时间条件。详尽的验证是找到这种CPU bug的关键。代码覆盖率可以帮助你,但绝对不够。如果一个功能没有在RTL中编码,覆盖率也就不可能报告它的缺失?此时需要在规范明确的情况下执行代码审查。
类型二:验证团队钟爱的极端案例
极端案例下的CPU漏洞找起来比较复杂,需要一个强大的测试平台。行使该功能的简单测试用例在有随机延迟的情况下也可以通过。很多时候,当异步事件加入时,就可以发现这些bug。例如,一个中断正好在两条指令之间到达,时间很精确。或者当存储缓冲区想要合并的时候,缓存中的一行被驱逐时。为了解决这些问题,我们需要一个测试平台来处理指令、参数和延迟,从而使所有可能的指令和事件的交错都得到锻炼。很明显,一个好的检查器应该发现任何与预期不同的偏差项。
在这种情况下,不幸的是代码覆盖率完全没用。仅仅是因为bug的条件是几个事件的组合,而这些事件已经被单独覆盖。在这里,条件覆盖或分支覆盖可能会有帮助。但分析起来很痛苦,而且最终也不会有有效的结果。
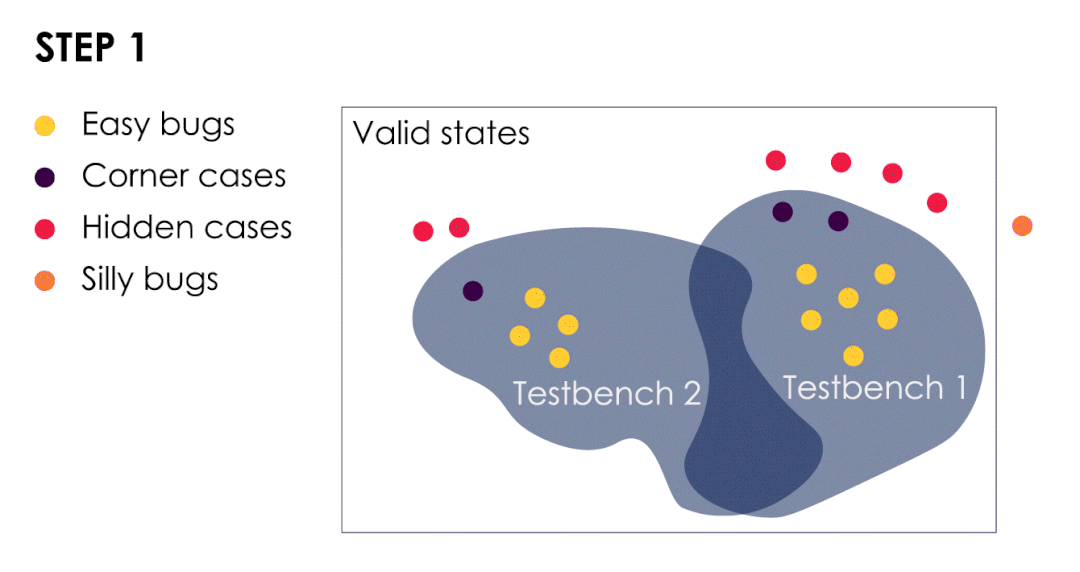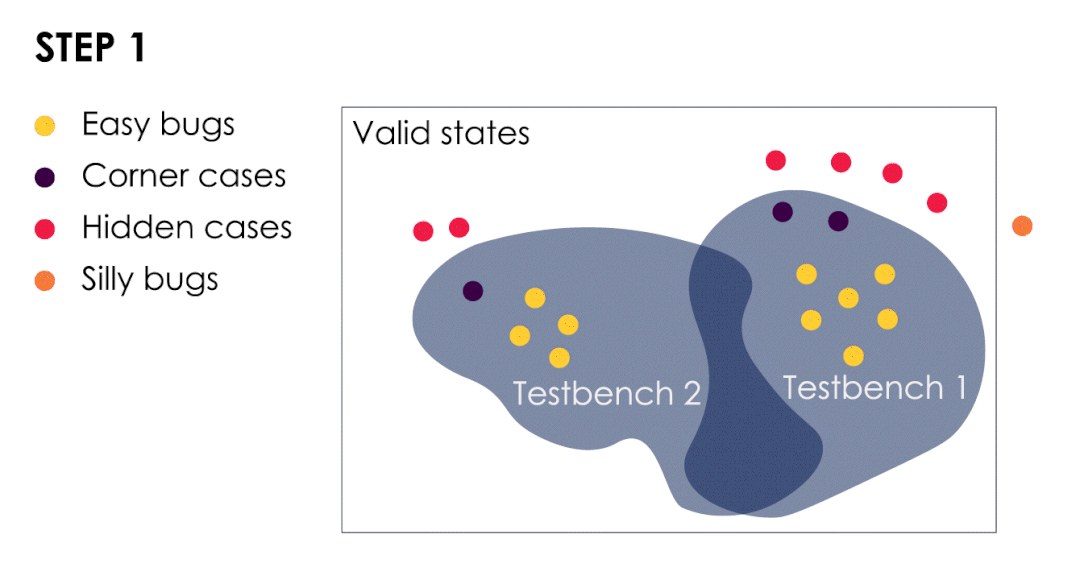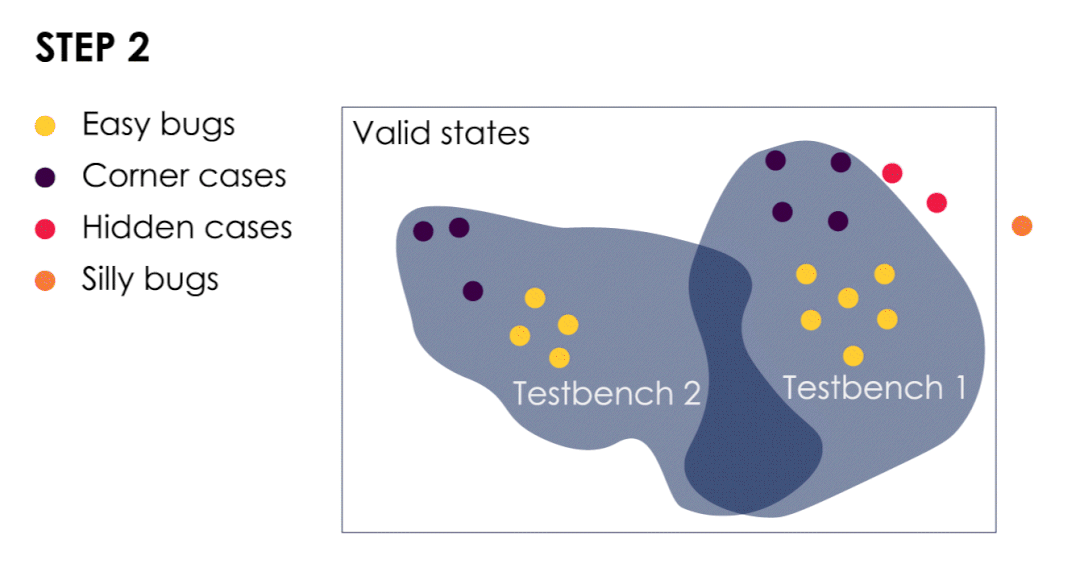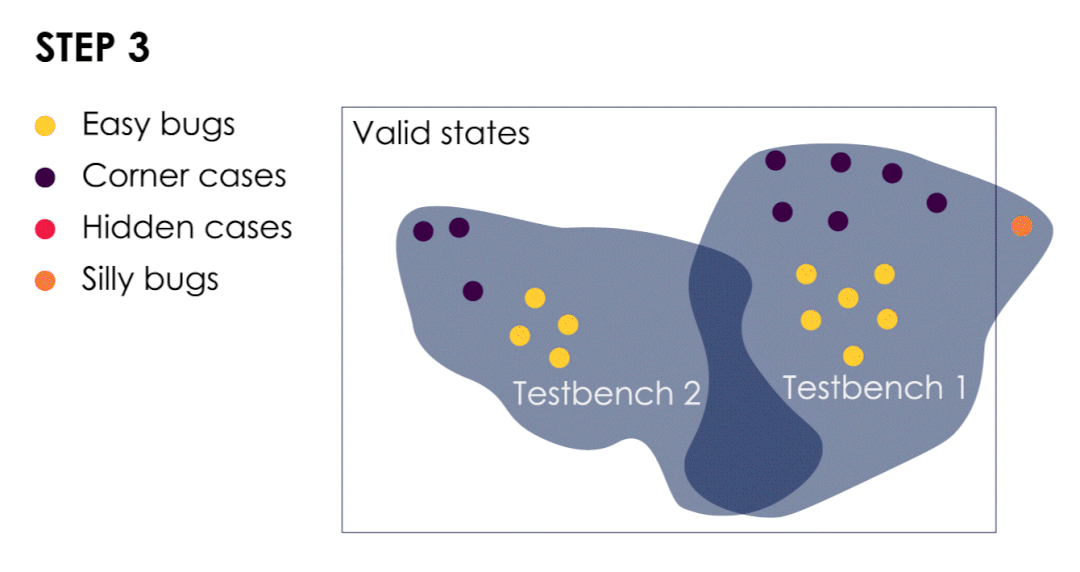
- 测试平台已经发现了简单的bug和几个极端案例。
- 我们从这些极端案例中汲取经验,以改进测试平台并扩大验证范围。这样做可以使我们发现隐藏漏洞,此时隐藏bug转变为极端bug(或较容易的bug)。
- 随着bug成群结队的出现,我们可以根据最后发现的bug进一步扩大验证范围。
- 当我们遇到一个“愚蠢”的bug时,就意味着我们的验证测试已经足够有效了。
类型三:偶然发现的隐匿式CPU 漏洞--或由客户发现的漏洞!
最坏的情况是如果这种隐藏的bug是由客户发现的,或者是偶然发现的(团队内部或在发布之前)。出现这两种情况,这意味着目前的验证方法不足以击中它们。
如果使用不同的测试平台或环境,因为刺激的不同可以找到其他的漏洞。那么我们所说的 "偶然发现 "是什么意思?这里涉及到随机测试平台方法的限制。
在随机刺激下,测试平台通常会产生 "相同 "的东西。如果你掷骰子得到一个随机数,连续10次得到数字6的机会非常少。准确地说,是六千万分之一的机会。对于有100条不同指令的RISC-V CPU来说,一个(可等价的)随机指令发生器每10⁰次只有1次机会产生连续10次相同的指令,这种机率是魔方不同位置数量的两倍...... 在一个10级流水线处理器上,用所有流水线阶段的相同指令来测试它也不是不合理的。如果此时还不调整随机约束,那么只能祝你好运...
类型四:在现实生活中不会出现的“silly bugs”!
如果我们把极端漏洞和隐藏漏洞看得太重,那么最终创建的测试或许有点徒劳。
在连接调试器时,每个周期来回改变字节数,这可能是永远不会出现在消费者产品上的案例,如果一个CPU漏洞的后果对客户来说是不可见的,那么它就不是一个真正的漏洞。如果你在复制文件时故意拔掉U盘,而导致文件被损坏,我认为这不是一个bug。如果某些操作导致USB控制器挂起,那么此时这是一个不容无视bug。
当我们试图扩大验证的范围时,如果出现“silly bugs”,那么我们可能是在错误的地方投入了太多的努力。
本文转自: Codasip 科达希普,转载此文目的在于传递更多信息,版权归原作者所有。如不支持转载,请联系小编demi@eetrend.com删除。





