作者: 梁达成,于颂,许铮
来源:壁仞科技研究院
摘要
随着深度学习的概念深入人心,相比于传统方法,机器学习(ML, Machine learning)的方法对于处理NP-complete问题提供了一整套新的解决方案。芯片设计过程可以看成不断的伴随着从一个step到另外一个step的抽象化任务模型建模的过程,其方法论在半导体发展的过程中不断的完善,汇集了种类繁多的各种抽象化模型任务,几乎可以包含所有ML适应的任务目标,包括分类,回归,决策选择,设计空间探索,模式生成等。
机器学习方法分类和简要介绍
机器学习的方法种类繁多,分类方法有多种,下面主要按照训练的方式中对数据集标签依赖特征进行划分,分别是监督学习(依赖数据标签),半监督学习(部分依赖数据标签),非监督学习(不依赖数据标签),强化学习(依赖奖励标签)四个类别。由于很多算法有其它类别的拓展,以下仅以一般经验做简单归类。
1. 监督学习(Supervised Learning)
- 支持向量机 (Support Vector Machine,SVM)
利用超平面对数据进行划分归类。 - 决策树(Decision Tree)
利用树形结构进行分类或者回归任务,基本的决策树包括CART/ID3/C4.5等,比较经典的算法例如随机森林,GBDT,Xgboost等。 - 贝叶斯方法(Bayes)
该类方法大多基于Bayes公式的基本概率原理进行衍生,包括朴素贝叶斯,贝叶斯网络,隐马尔可夫模型HMM等。 - 启发式算法(Heuristic algorithm)
基于直觉或者经验构造的算法,启发式算法以仿自然体算法为主,有模拟退火算法SA,遗传算法GA,蚁群算法ACA等。 - 人工神经网络(ANN,Artificial Neural Network)
CNN,卷积神经网络
利用卷积操作进行数据处理,常见的网络例如ResNet,EfficientNet等。
RNN,循环神经网络
利用数据的时间维度的连续性构造循环网络,常见的网络例如LSTM,GRU等。
DNN,深度神经网络
大多数基于矩阵乘法运算,常见的网络例如MLP多层感知机, Transformer,Bert衍生系列等。
GNN,图神经网络
利用节点信息间的拓扑结构进行Massage Passing信息聚合等操作,常见的网络例如GCN,Graph-sage,GAT及其衍生系列等。
GAN,生成对抗网络
利用生成模型合成图片或者其它人造数据。
2. 半监督学习(Semi-supervised learning)
半监督学习的方法是利用类似数据增强的手段从一部分少量标签进行学习,基本算法和前面的监督方法类似。
3. 非监督学习(Unsupervised learning)
- 聚类算法(Clustering)
最著名的例如K-Means,进行邻居等聚类运算,无需标签,只需要人为设置类别的数量即可进行分类。 - 主成分分析方法(PCA,Principal Component Analysis)
通过主成分分析的正交变换方法将高维数据降到低维数据,从而方便下游任务进行分类或者回归。
4. 强化学习(Reinforcement learning)
强化学习将问题建模为智能体与环境交互过程,从而使得对数据标签的使用方式与上述方法略有不同。通过利用数据标签中的奖惩信息,使得智能体的高价值行为得到奖赏,低价值行为受到惩罚,最终驱动智能体能够以累计奖励最大化来实现任务目标。目前强化学习的热点研究主要集中在深度强化学习上。这些算法按照有无模型可分为基于模型(model-based)算法,例如AlphaZero,无模型(model-free)算法,例如DDPG。而无模型方法中又可分为基于Q函数方法如DQN(Deep Qlearning),基于策略梯度方法,如PG(Policy gradient),以及综合两种方法而提出的Actor-Critic方法,如目前常用的算法PPO,TD3等。
限制强化学习的因素主要分为算法的训练过程,以及智能体与环境的交互效率。在实际应用中,相对于算法的训练过程(可以利用Tensor core进行加速的矩阵乘法运算),环境交互效率往往成为性能的瓶颈,例如复杂的仿真器设计或是数字孪生环境反而容易成为强化学习的性能瓶颈,因此强化学习多用于游戏(围棋,星际争霸,DOTA)等易于仿真的领域,这些场景的环境较为纯净。而其它例如机器人,自动驾驶等真实场景的领域场景较为复杂,相关应用还处于探索阶段。芯片设计中仿真环境大多数为数学算法模型,因此强化学习将有很大的发挥空间。另外,强化学习在大空间范围内的设计空间探索任务(DSE, design space exploration)也有比较好的效果[2]。
数字芯片设计流程介绍
数字芯片一直按照摩尔定律的规律在发展。在工艺发展的过程中,不断衍生出新的方法和新的问题,芯片设计的方法论也一直在不断的更新。
我们总结了一个典型的芯片开发流程图,主要包括4个大部分,分别是架构开发,软件开发,芯片开发,系统开发。

芯片开发首先从目标算法和应用出发,根据经验或者系统建模的方法得到相关架构指标和结构,即系统定义,系统定义给我们一个芯片的整体模块框架的粗颗粒度的解决方案,根据这个方案我们可以继续后续细化的架构设计,包括指令集定义(ISA),模块的微架构设计(Micro Architecture),编程模型(Programming Model),Chiplet和SiP(System in Package)设计,机柜和板级(Rack/Board)方案等。
在主要架构部分设计决定后,接下来就是在传统开发流程中需要开始大量消耗人力资源和计算机资源的软硬件研发步骤,主要包括逻辑设计/验证(Logic design/verification),逻辑综合(Logic level synthesis),系统级仿真平台(FPGA/Emulation),Design for test(DFT),形式验证(Formal verification),布局规划(Floorplan),布局(Placement),时钟树综合(Clock tree synthesis),布线(Routing),工程修改命令(ECO),静态时序分析(static timing analysis),物理验证(Physical verification),制造(Fabrication),封装(Packaging)和测试(Testing),驱动和编译器设计(driver/compiler),其中每一个步骤都包含了大量的测试迭代和反复设计的过程,很大程度上影响了芯片设计的周期,因此,这些领域也是可以让机器学习方法极大提升生产效率的领域。
ML方法在芯片设计领域的应用
在芯片开发过程中,ML方法在整体解决或者辅助芯片工程人员解决各类问题有大量的尝试,有一些取得了很好的效果。下面,我们以上述介绍的数字芯片设计整体流程为脉络,结合开篇介绍的机器学习方法类型,简单的梳理一下,到目前为止的ML方法在芯片研发领域采用的实用和实验性的方法[1][3]。
1. 架构开发
架构开发是整个项目开发的前序关键步骤,在确定好架构定义后,后续的软件/硬件/系统部分开发才能很好的细化和执行。
架构开发分为算法和应用定义,系统架构开发,ISA设计,微架构设计几个方面。
- 系统架构开发
系统架构开发作为整个芯片设计的起点,是影响芯片总体性能,开发成本,开发周期的关键步骤。
系统架构开发的最主要工作就是根据当前的算法和应用,分析工作负载,进行系统建模,最后给出符合性能设计要求的方案。机器学习方面的相关工作主要集中在GPU,CPU,多核异构等系统中。
主要的任务包括:
- 如何选择合适的任务从CPU offload到GPU
- 不同应用程序的性能预测
- 使用当前的GPU设计预测架构改进后的GPU性能
- 使用CISC处理器的运行结果预测RISC处理器的性能
这些工作如果使用传统的方法将会耗费大量的时间和人力实际运行或者模拟,而采用机器学习的方法后能快速获得一个高准确度的结果。这里可以用到几乎所有的机器学习算法类型,这里就不一一列举了。>
- ISA设计
即指令集的定义,目前业界的主要方法是依据传统领域处理器指令集的经验进行设计。随着RISC-V的出现,如何对DSA相关功能进行指令设计以及和原有指令集很好的融合是一个比较有意思的问题,对这一部分内容的探索可能出现在未来系统架构开发的过程中。
- 微架构设计
微架构是设计工程师对系统架构理解后,对具体模块进行详细工作模式,结构,步骤,接口的详细描述。微架构设计直接影响到整体架构的能效能否落实。
微架构设计的范围非常广泛,这里我们有很多经典性能子模块应用ML的例子,这些热点领域包括branch prediction, cache, memory controller, NoC(Network on chip), power management, resource分配和task管理等设计问题。
Branch prediction分两类任务,一个是预测是否发生跳转,一个是预测跳转的地址。传统的predictor只能记录有限的历史长度。在predictor的训练方面,我们可以利用静态程序库和离线的时候进行训练,在编译阶段使用MLP等方法引入预测结果的hint,从而辅助硬件在线预测。另一种方法是在线动态的对branch地址进行hash,从而选择合适的感知器,预测是否进行跳转。基于感知器和MLP的predictor可以用合理的硬件资源处理超长时间预测问题,并且达到SOTA性能。论文[4]分享了一种利用感知器预测indirect branch跳转地址的方法。
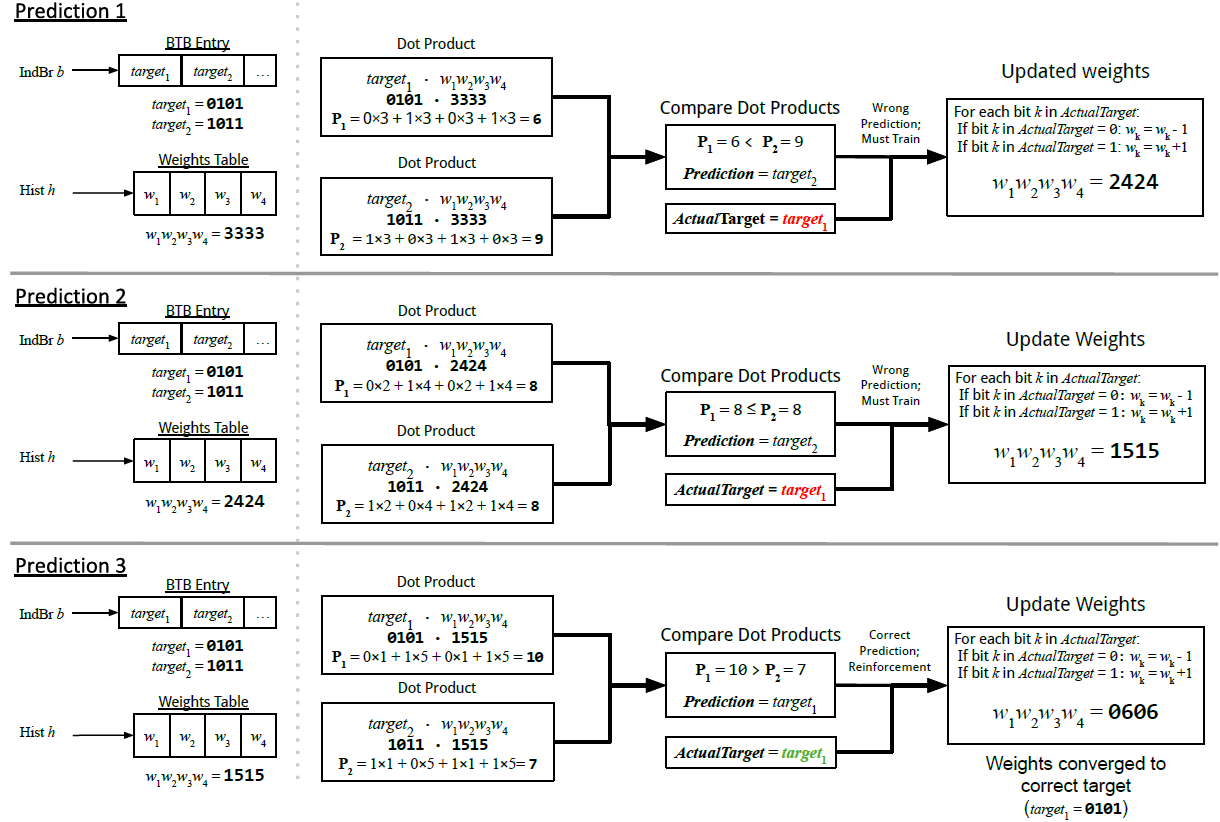
Cache性能设计的难点和重点主要集中在replace policy和pre-fetch policy,对于replace policy,我们可以利用感知器模型,马尔可夫决策过程,SVM等方法来提升cache block的复用率, 训练的时候也可以使用线上线下相结合的方法,综合的提高hit rate。传统pre-fetch问题也可以看成是一个预测memory access pattern的问题,可以使用LSTM方法将问题建模成语句序列的预测问题。
Memory controller设计方面,不同的工作负载下的MC可能有多个优化目标,例如能耗,吞吐率等,使用强化学习table-based Q-learning构建调用DRAM命令策略和学习当前MC的状态表征是一个比较典型的方案。
NoC的微架构设计热点主要集中在功耗管理,routing和traffic control,reliability等方面。Routing问题可以看成是连续决策过程,特殊的地方是NoC在引入ML方法时可以引入NoC拓扑结构信息辅助决策,Q-learning/ANN的相关方法可以用于非规则的拓扑网络,预测并绕开congested region,从而提高packet的传输效率。
在使用先进工艺制造的芯片中,功耗管理策略的好坏直接影响到系统真实性能的表现。我们可以使用ANN在线或者离线学习方法来动态的调整不同模块的电压和频率,例如L2和CPU, 以最小的功耗满足性能需求。
Resource分配和task管理的一个热点问题是在异构系统中,如何合理分配workload给不同的device。我们可以使用RL-based方法,结合seq2seq model进行任务分配,提升系统的整体效率。同时我们还可以结合计算图的特征,将整个计算图的信息encode到策略函数里面,提升输入信息的表征的完整性,取得更好的效果。
2. 软件开发
在芯片设计中,和硬件结合比较紧密的软件开发部分包括API/libraries的定义,芯片架构的programming model定义,complier/driver/固件设计等。
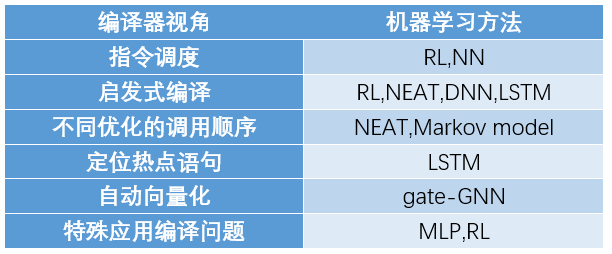
其中complier/driver处于芯片软件栈的底层区域,ML方法在软件栈的应用主要集中在该领域。其中,主要的应用的任务有code generation和complier design两大领域。Code generation从NLP的角度看可以看成是两种不同的任务,一种是语句生成任务,一种是语言翻译任务(例如从CUDA转换成OpenCL)。因此,有很多方法中使用了RNN,NMT, encoder-decoder等模型和框架解决问题。Complier设计中有很多经典问题,很多都可以利用ML方法进行相关优化,详见下表:
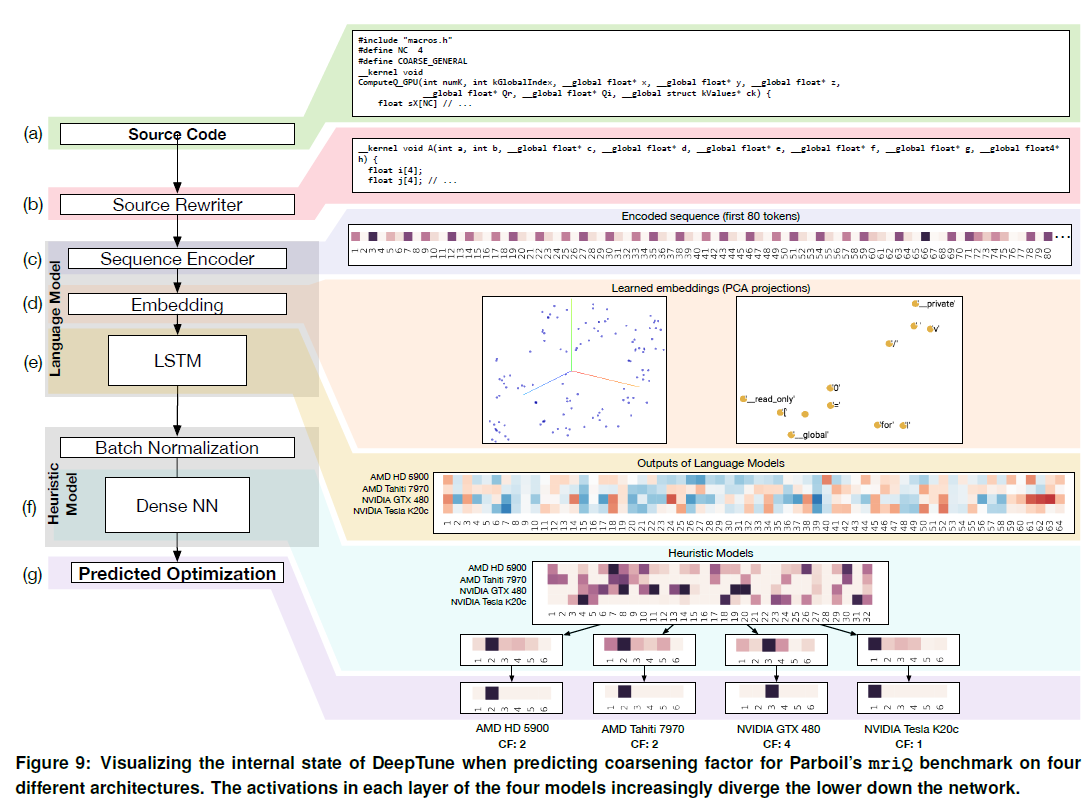
同时,我们也看到了类似deep tune[5]这样的端到端优化方案。将程序语句encoder到向量空间,利用embedding和LSTM构建语言模型,然后在启发式模型中对不同target device进行CF线程颗粒度的选择。
3. 硬件开发
- 逻辑设计/验证 (Logic design/Verification)
随着芯片规模的不断增长,相对于手工设计代码和模块级别重用,越来越多的高层次自动化设计方法HLS (High level synthesis)被引入到逻辑开发中。
机器学习在HLS领域的应用主要有3个方面,第一类是结果预测,例如timing,resource usage,operation delay等指标。第二类是跨平台性能预测,第三类是对现有方案的改进。第一二类的任务其实都可以用到回归的解决方法,可以使用几乎所有的机器学习回归任务方法。第三类任务主要用到决策树的相关方法。
验证是几乎是整个硬件开发中最耗费人力成本的一个阶段,保证验证质量的关键指标是测试的覆盖率coverage,如何合理的构建测试集,用最少的时间完成更多的状态机FSM和输入状态的覆盖,是验证的核心问题。
大多数情况下,我们会根据design的功能描述定义test plan。最近,出现另一种CDG(coverage-directed test generation)技术,该技术产生的random generator生成的test覆盖率更高。这种技术使用了多种ML技术,包括贝叶斯网络,马尔可夫模型,遗传算法,支持向量机,神经网络等。
另外,验证过程中另一类问题是大量重复的debug工作,例如不同逻辑的改动可能引起同一个错误,我们可以利用机器学习的方法将bug进行预分类处理,使用的方法有决策树,随机森林,支持向量机,或者神经网络等。
- 逻辑综合 (Logic level synthesis)
逻辑综合是将RTL寄存器描述转换成门级网表的过程。我们可以将电路看成是一个DAG(Directed Acyclic Graph)图的表达形式,使用DNN方法根据不同的QoR(Quality of Results)需求将电路优化成AIG(And-Inverter Graph)的形式或者是MIG(Majority Inverter Graph)的形式。另外,我们也可以利用CNN的方法来预测一个RTL设计的QoR,其中包括timing/area/power等指标。在强化学习中,也有一些针对逻辑综合任务的建模技巧,例如,我们可以将同一个IO行为的电路的不同的DAG实现看成一个强化学习中的action;使用GCN方法作为策略函数来获得每一个action的概率等。
- Design for test (DFT)
DFT是电路设计的重要步骤,在数字电路中我们通过插入寄存器扫描链能发现芯片中各种由于制造过程引起的电路缺陷,包括电路连线断路短接甚至timing问题等。如何减少observation-point并最大化fault coverage是一个点可以优化的方向,减少observation-point可以减少测试时间,有方法使用GCN网络,将电路网表转换成图的表达形式,将模块表示为点,将连线表示为边,从而将模块分为容易观测和难于观测的不同类型,在容易观测的模块上插入更少的观测点,从而减少观测点的数量。
- 布局规划 (Floorplan)
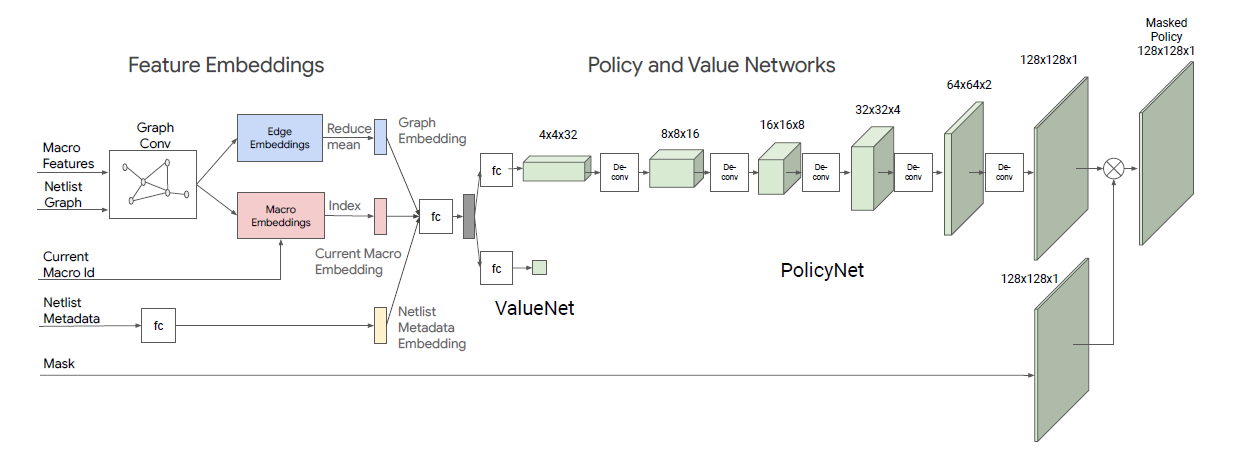
Floorplan是placement的前序步骤,在这个阶段我们需要根据一定的原则将所有的模块在区域内摆放位置确定好,同时满足时序和走线基本需求。对此,Google设计了一个强化学习策略,将macro的摆放过程看成是连续的决策过程[6]。下图展示了具体网络设计流程,其使用GCN,将所有macro的信息和网表的连接信息做embedding,拿到graph embedding当前macro的embedding和网表元数据的embedding后,通过一个FC层分别送给策略网络和价值网络。其价值网络是一个FC层,策略网络是一个反卷积网络,策略网络会根据概率输出一个128x128x1的网格mask,作为当前macro的摆放位置。另外还会输出一个当前placement的预期reward,其奖励是整个方案预估的走线长度和congestion的线性加权值。
- 布局 (Placement)
布局的任务是将所有的standcell的位置确定好,同时满足时序和走线需求。在这个阶段,所有的standcell都是同等对待的,相对于一般logic,data-path对功耗和timing更敏感,这里为了更好的优化data-path相关逻辑,有方法了使用支持向量机和神经网络等手段提取data-path的相关pattern,进行分类,从而针对其逻辑进行特殊优化。
- 时钟树综合 (Clock tree synthesis)
在CTS阶段生成时钟树,满足transition,max cap,maxfan-out等DRC(design rule constraints),同时满足skew和latency等需求。这里可以用到对抗生成网络来优化,使用conditional GAN, 其中的生成模型通过一个回归模型采用监督学习的方式训练获得。
- 布线 (Routing)
在Routing阶段,我们会将所有的net连接起来,使用最佳的SI(Signal integrity)/timing方案,同时满足DRC。
Routing的一个重点工作是如何更早的发现预测congestion。有工作在routing之前对网表进行分析,利用CNN网络,预测DRC violation。另外有工作将placement后的网表抽象为图像数据,使用pixel-wise的loss function优化出一个encoder-decoder模型,从而得到routing后的congestion的热点图。
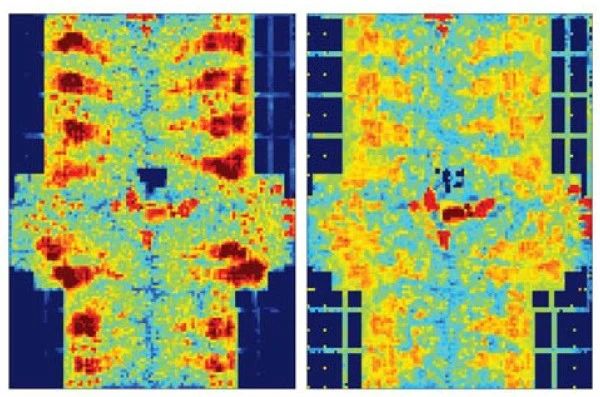
Routing的另外一个工作重点是得到总的连线长度,timing,面积,功耗等指标,这是一个典型的回归问题,可以使用SVM, 回归树等方法。
- 静态时序分析 (Static timing analysis)
在3D integration中,die-to-die之间的数据和时钟通过TSV(Through-Silicon Via)相连接,die-to-die之间也有timing variation,传统的OCV(on-chip variation)/AOCV/POCV不能准确的对path delay建模,我们可以利用Multivariate Adaptive Regression Splines (MARS)这种回归的方法对die-to-die variation进行建模。
在sign-off timing analysis方面,有很多ML方法用于降低timing分析的时间成本,减少误差。我们可以使用SI-free的timing结果,采用归回模型来预测SI的timing结果,其中,带SI的时序分析是十分耗时的。
- 物理验证 (Physical verification)
Physical verification包括DRC/LVS/STA等部分。其中也包括timing sign off(详见static timing analysis部分)。
在ParaGraph[7]这篇工作中,作者使用了一个异构的GNN模型来预测版图的寄生效应和物理器件参数,并使用一个ensemble模型来提高预测的准确度。

4. 系统开发
- 系统级仿真平台 (FPGA/Emulation)
系统级仿真平台在大型芯片开发中有着重要作用,其可以在早期开发阶段调试并发现系统级问题,避免在开发后期造成无法弥补的损失。在FPGA实现方面,这里的方法可以借鉴前述高层次综合和布局布线问题的一些相关经验和思路。
以上分别介绍了架构,软件,硬件,系统开发中的一些应用的机器学习的方法和实例,这里使用机器学习可以解决跨流程多目标联合优化问题,不单单局限于某一个流程或者问题,而这在传统的芯片设计方法学中可能是无法很好实现的。
前景总结
目前机器学习方法在芯片设计工作中有越来越多的应用实例,其中既有传统的机器学习技术也有最近流行的深度学习技术,使用两种技术融合来解决实际问题也取得了很好的效果,绝大多数的ML方法都能够在GPU或者其它具备并行加速功能的芯片上进行硬件加速,因此在性能上比传统指令运算更加快速,虽然在可解释性方面略有不足,但是很多实验结果证明,机器学习方法经过算法学习和调优能给我们带来比传统方法论更全面和更优的结果。机器学习方法在半导体行业正实践着一个正反馈的循环,它的出现加速了芯片的迭代过程,而反过来芯片的迭代促进了机器学习方法在性能方面的提升,一步一步,在实现“用摩尔定律来加速摩尔定律”的这个愿景。
参考文献
[1] A Survey of Machine Learning for computer Architecture and Systems,NAN WU and YUAN XIE, University of California, Santa Barbara
[2] Apollo: Transferable ArchitectureExploration,Amir Yazdanbakhsh Christof AngermuellerBerkin Akin Yanqi Zhou Albin Jones Milad Hashemi Kevin Swersky SatrajitChatterjee Ravi Narayanaswami James Laudon
[3] Machine Learning for Electronic DesignAutomation: A Survey,GUYUEHUANG, JINGBOHU, YIFAN HE, JIALONG LIU, MINGYUAN MA, ZHAOYANG SHEN, JUEJIAN WU, YUANFAN XU, HENGRUI ZHANG, KAI ZHONG, and XUEFEI NING, YUZHE MA, HAOYU YANG, and BEI YU, HUAZHONG YANG and YU WANG
[4] Bit-level Perceptron Prediction for Indirect Branches,Elba Garza, Samira Mirbagher-AjorpazTahsin Ahmad Khan, Daniel A. Jimenez
[5] End-to-end Deep Learning of Optimization Heuristics,Cummins, C, Petoumenos, P, Wang, Z & Leather, H
[6] Chip Placement with Deep ReinforcementLearning,Azalia Mirhoseini Anna Goldie Mustafa YazganJoe Jiang Ebrahim Songhori Shen Wang Young-Joon Lee Eric Johnson Omkar PathakSungmin Bae Azade Nazi Jiwoo Pak Andy Tong Kavya Srinivasa William Hang EmreTuncer Anand Babu Quoc Le James Laudon Richard Ho Roger Carpenter Jeff Dean
[7] Haoxing Ren, George F Kokai, Walker J Turner, and Ting-Sheng Ku. 2020. ParaGraph: Layout parasitics and device parameter prediction using graph neural networks. In 2020 57th ACM/IEEE DesignAutomation Conference (DAC).





