计算机视觉是人工智能的一个领域,它训练计算机解释和理解视觉世界。利用来自相机和视频的字图像以及深度学习模型,机器可以准确地识别和分类物体,然后对它们“看到的”做出反应。
本文总结了20个常用的开源计算机视觉数据集,数据集很多如果放网址会被认定广告,所以请自行通过名字搜索,数据集按照字母顺序排序。
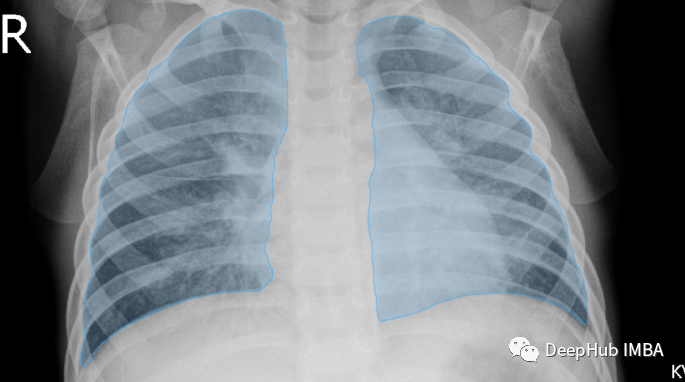
1、COVID-19 X-Ray Dataset (V7)
这是COVID-19的V7版本的数据集,包含6500张AP/PA胸部x光片图像,像素级的多边形肺分割。其中有517例COVID-19病例。
每个图像都包含:
两个“肺”分割掩码
类型标签(病毒性、细菌性、真菌性、健康/无)
如果患者患有COVID-19,则会附加标签说明年龄、性别、体温、位置、插管状态、ICU住院情况和患者预后。
肺部注释是遵循像素级边界的多边形。可以将它们导出为COCO、VOC或Darwin JSON格式。每个注释文件都包含到原始全分辨率图像和缩小大小的缩略图。
2、CIFAR-10 & CIFAR-100
CIFAR-10和CIFAR-100是Alex Krizhevsky、Vinod Nair和Geoffrey Hinton收集的8000万张小图像数据集的标记子集。
CIFAR-10包含60000张32x32彩色图像,包含10个类(动物和真实物体)。每个类有6000张图片。这个数据集有50000张训练图片和10000张测试图片。
CIFAR-100包含100个类,每个类包含600个图像。每个类有500张训练图片和100张测试图片。

3、ImageNet
ImageNet是最受欢迎的图像数据集之一,拥有超过1400万张手工注释的图像。这个数据集就不用多介绍了

4、Kinetics-700
这是是一个大型视频数据集,包含650,000个剪辑,涵盖700个人类动作类。
这些视频包括演奏乐器等人与物之间的互动,以及拥抱等人与人之间的互动。每个动作类至少有700个视频剪辑,每个剪辑都标注了一个持续约10秒的动作类。

5、MNIST
这是一个手写数据的数据集,包含6万张训练图片和1万张测试图片。它发布于1999年,可以说时CV中的Hello World。

6、LSUN
LSUN(大尺度场景理解)包含近100万的标记图像,分别对应10个场景类别和20个对象类别。
对于训练数据,每一类包含12万到3亿张图像。验证数据包括300张图片,测试数据每类有1000张图片。

7、IMDB-Wiki
它是包含性别、年龄和姓名的最大的公开人脸数据集之一。总共包含523,051张图片,其中460,723张人脸图片来自IMDb的20,284位名人,62,328张来自维基百科。

8、MS COCO
MS COCO (Microsoft Common Objects in Context)数据集由328K张图像组成。它包含了目标检测、关键点检测、全景分割、素材图像分割、字幕和密集人体姿态估计的注释。

9、Labeled Faces in the Wild
它是一个拥有13000张人脸照片的大型数据集,专门用于人脸识别任务。每张脸都标上了这个人的名字。

10、Cityscapes
Cityscapes包含50个不同城市街道场景中录制的各种立体视频的序列。这些图像是在不同的光线条件和天气条件下拍摄的。
Cityscapes包括语义的,实例的像素注释,包含了8个类别的30分类。提供了5000帧的像素级注释和20,000帧的粗略注释。

11、LabelMe-12–50k
该数据集包含50,000张JPEG图像(40,000张用于训练,10,000张用于测试),包含12个类。这些图像是从LabelMe中提取的。
分类包括诸如汽车、人、树或键盘等对象。训练和测试集中50%的图像为居中对象,而其余50%的图像显示随机选择的图像的随机选择区域。该数据集可用于对象识别。

12、Places
Places数据集由250万张图片(带有类别标签)和205个场景类别组成。每个类别有超过5000张图片。它可以用于场景识别任务。

13、Places2 (365-Standard)
这里另一个由MIT贡献的场景数据集。有180万张图片来自365个场景类别。该数据集在验证集中每个类别包含50张图像,在测试集中包含900张图像。Places2数据库可用于场景识别,通用的深场景特征可用于视觉识别。

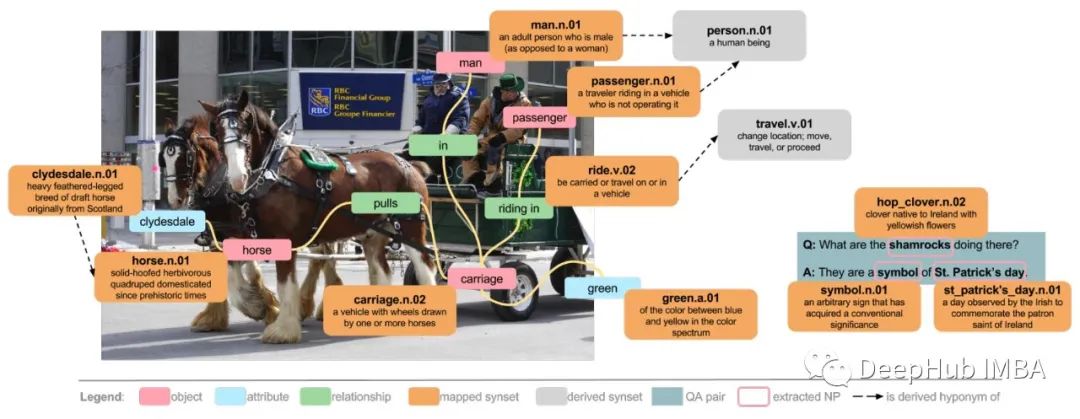
14、VisualGenome
它是一个庞大的数据集和知识库,它包含108,077张带有注释的对象、属性及其关系的图像。
15、Stanford Dogs
这个数据集使用ImageNet中的图像和注释(类标签、边界框)构建的。包含来自世界各地的120种狗的图像。共有20.580张图片,120个类别。

16、Stanford Cars
这个数据集包含16,185张图片和196类的汽车。数据被分成8144张训练图像和8041张测试图像,其中每个类别大致按50-50的比例划分。数据集还包含了分类标签和边界框。

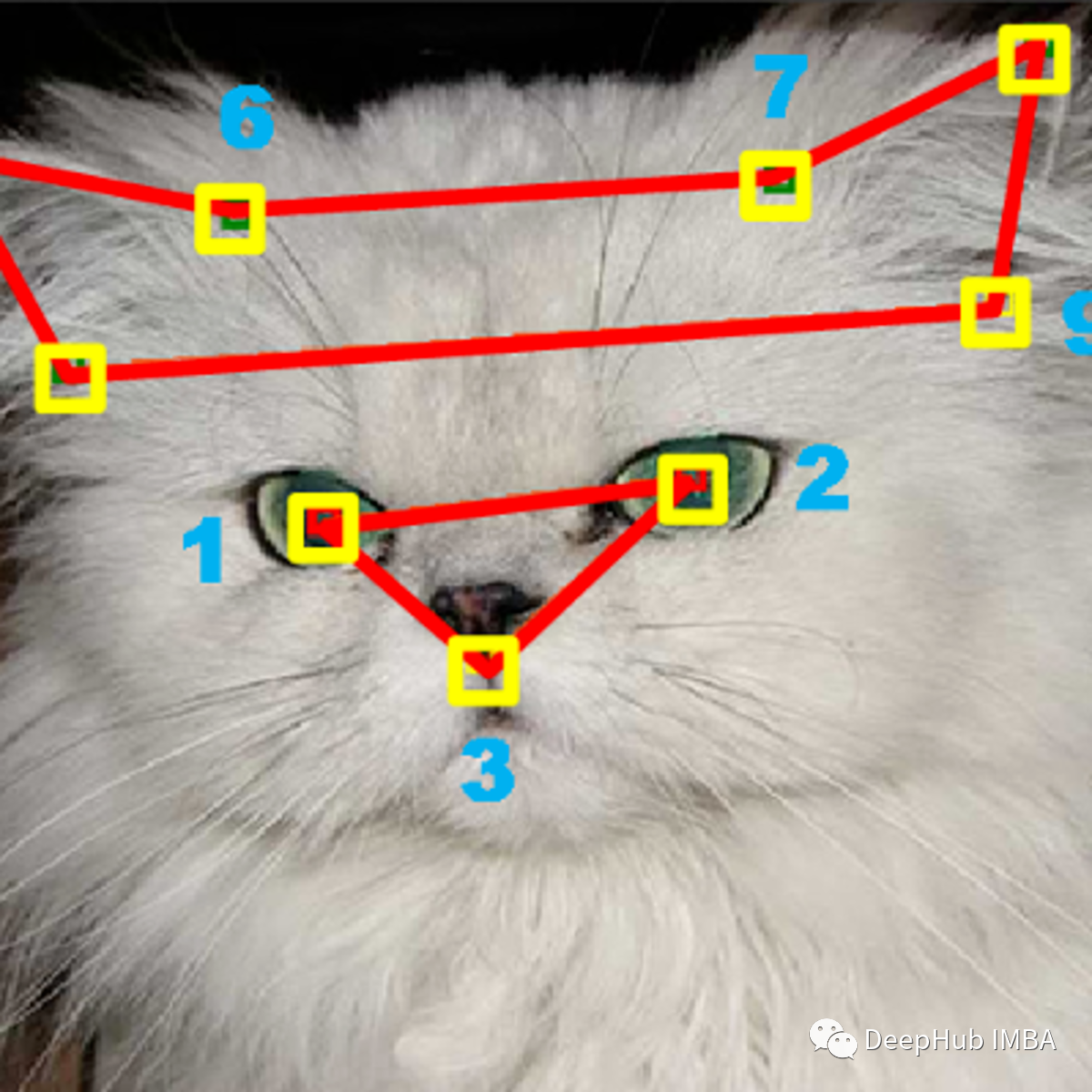
17、Cat Dataset
CAT数据集包括9000多张带有注释的猫的头像图。每张猫的头像上都有9个点:两个点代表眼睛,一个点代表嘴巴,还有6个点代表耳朵。
18、CelebFaces
名人人脸数据集(CelebA)是一个大型的人脸属性数据集,拥有超过200.000张名人图片,每张图片有40个属性注释。每张图片的注释包括10177个独特的身份和5个地标位置。
该数据集可用于人脸检测、人脸属性识别、定位和地标(或面部部分)定位的训练和测试集。

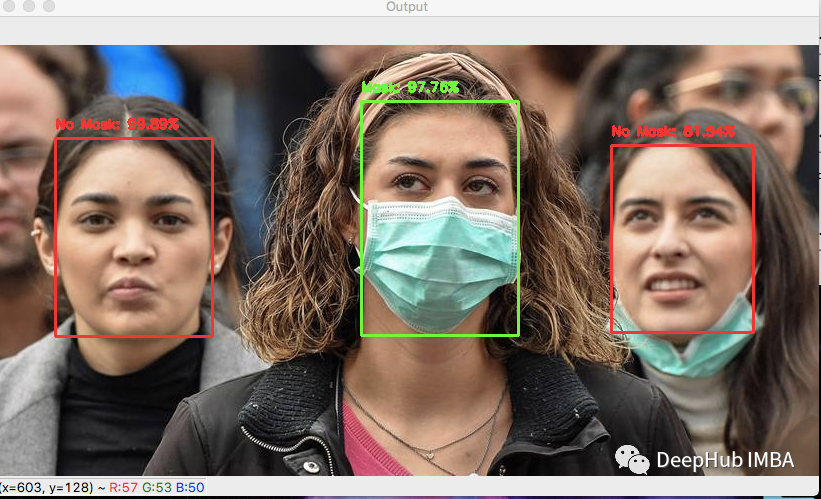
19、Face Mask Detection
此数据集包含853个属于PASCAL VOC格式的3个类及其边界框的图像。泪飙包括“戴口罩”、“不戴口罩”和“戴口罩不正确”。
20、Fire and Smoke Dataset
这是一个拥有7000多张高清图像的数据集。它由在现实场景中使用手机捕捉到的早期火灾和烟雾图像组成。这些照片在各种各样的光照条件和天气下拍摄。该数据集可用于火灾和烟雾识别、检测,以及异常检测。
它还包含了各种家庭场景,包括垃圾和田间作物燃烧,以及家庭烹饪等。

21、FloodNet Dataset
该数据集由高分辨率的无人机图像组成,带有关于飓风造成的破坏的详细语义注释。数据是在飓风哈维之后用小型无人机平台DJI Mavic Pro四轴飞行器收集的。整个数据集有2343张图像,分为训练集(~60%)、验证集(~20%)和测试集(~20%)。

本文转自:DeepHub IMBA,转载此文目的在于传递更多信息,版权归原作者所有。如不支持转载,请联系小编demi@eetrend.com删除。





