作者:Ed Shee ]
来源:企业网D1Net
当孩子逐渐成长时,他们会通过听觉、视觉和触觉等感官向周围的世界学习。他们对世界的理解、形成的观点以及最终做出的决定都会受到成长环境的影响。例如,一个在性别歧视社区生活和成长的孩子可能不会意识到他们看待不同性别的方式存在偏见。
机器学习模也是如此。他们并不使用感官来感知,而是使用数据来学习——是人类提供的数据。这就是用于训练机器学习模型的数据尽量避免偏见变得至关重要的原因。以下内容介绍了机器学习中一些最常见的偏见形式:
(1)历史偏见
在收集用于训练机器学习算法的数据时,获取历史数据通常是最容易开始的地方。但是,如果不小心的话,很容易将历史数据中存在的偏见包括在内。
以亚马逊公司为例。该公司在2014年着手构建一个自动筛选求职者的系统。这个想法是为这个系统提供数百个简历,并自动挑选出最优秀的候选人。该系统接受了该公司10年来的工作申请及其录取结果的训练。那么出现了什么问题?因为亚马逊公司大多数员工都是男性(尤其是技术岗位)。人工智能算法了解到,由于亚马逊公司的男性员工多于女性,男性则是更合适的候选人,因此对女性求职者产生了歧视。到2015年,这个项目由于产生偏见不得不取消。
(2)样本偏见
当训练数据不能准确反映模型的实际使用情况时,就会出现样本偏见。通常情况下,一个群体的代表性或者过高,或者偏低。
例如,在美国训练将语音转换成文本的一个项目中,需要大量音频剪辑及其相应的转录。那么有声读物将获得大量此类数据,这种方法有什么问题?
事实证明,绝大多数有声读物都是由受过良好教育的白人男性讲述的。不出所料,当用户来自不同的社会经济或种族背景时,使用这种方法训练的语音识别软件表现不佳。
(3)标记偏见
训练机器学习算法所需的大量数据需要标记才能有用。当人们登录网站时,实际上自己也经常这样做。例如要求识别包含红绿灯的方块?实际上是在确认该图像的一组标记,以帮助训练视觉识别模型。然而,人们标记数据的方式千差万别,标记的不一致会给系统带来偏见。
(4)聚合偏见
有时,人们聚合数据以简化数据或以特定方式呈现数据。无论是在创建模型之前还是之后,这都可能导致偏见。
例如下面这个图表:
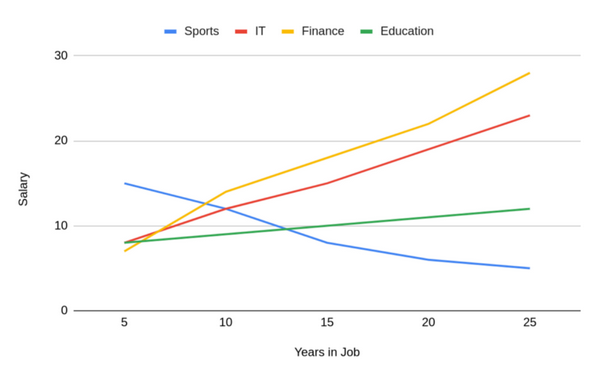
它显示了人们的薪酬将如何随着工作年限增加。这具有非常强的相关性,工作的时间越长,得到的报酬就越多。
下图可以了解用于创建这一聚合的数据:
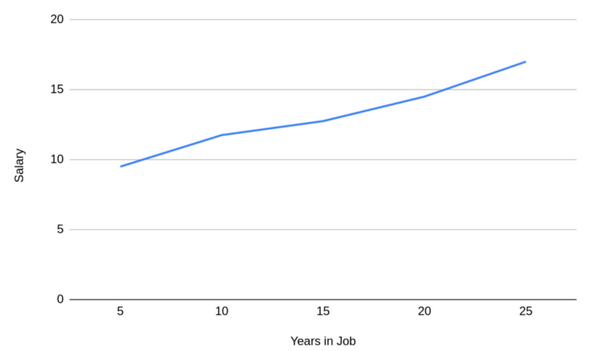
(5)确认偏见
简而言之,确认偏见是人们倾向于相信能证实其现有信念的信息,或者丢弃不符合现有信念的信息。从理论上来说,可以构建有史以来最准确的机器学习系统,无论是数据还是建模都没有偏见。
在机器学习的应用中,确认偏见尤其普遍,在采取任何行动之前,都需要进行人工审查。人工智能在医疗保健行业中的应用已经让医生们对算法诊断不屑一顾,因为它与他们自己的经验或理解不符。通常情况下,很多医生并没有阅读过最新的研究文献,这些文献中的症状、技术或诊断结果可能和他们的知识和经验有所不同。实际上,医生阅读的期刊数量有限,但机器学习系统可以将它们全部收录。
(6)评价偏见
假设一个团队正在构建一个机器学习模型来预测美国大选期间的投票率,并希望通过采用年龄、职业、收入和政治立场等一系列特征可以准确预测某人是否会投票。于是构建了一个模型,通过当地选举活动对其进行了测试,并且对结果非常满意。在95%的情况下,似乎可以正确预测某人是否会投票。
随着在美国大选活动中的应用,该团队对这个模型感到非常失望。因为花费很长时间设计和测试的模型正确率只有55%——这只比随机猜测的表现好一点点。其糟糕的结果是评估偏见的一个例子。通过当地选举活动评估其模型,无意中设计了一个只对该地区有效的系统。而美国其他地区的投票模式完全不同,即使它们包含在其初始训练数据中,也没有得到全面的考虑。
结论
以上是偏见影响机器学习的六种不同方式。虽然这不是一个详尽的列表,但它应该能让人们很好地理解机器学习系统最终具有偏见的最常见方式。
版权声明:本文为企业网D1Net编译,转载需注明出处为:企业网D1Net,如果不注明出处,企业网D1Net将保留追究其法律责任的权利。





