引言
在深度学习领域,被称为“目标检测”的子学科是包括通过图片、视频或网络摄像头来识别对象的过程。
如今,目标检测几乎无处不在。使用案例是无穷无尽的,无论是跟踪对象,视频监控,行人检测,异常检测,人数统计,自动驾驶汽车或脸部检测,而且应用范围还在继续增加。

当一个初学者来到目标检测领域都会对如此多的算法感到茫然,他们需要在如此多的算法中找到合适的,每个算法都有其固有的优缺点。本文我们将主要介绍几种常用的目标检测算法。
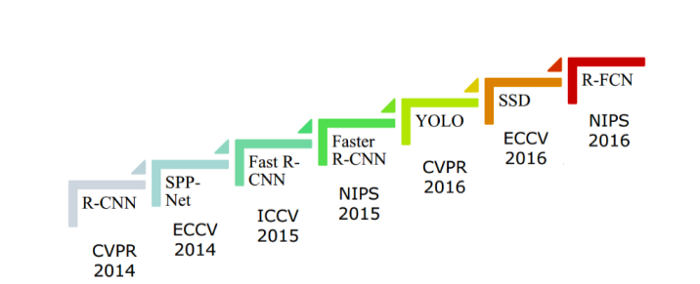
R-CNN
Region-CNN (R-CNN) 是最先进的基于 CNN 的深度学习对象检测方法之一。基于此,有fast R-CNN和faster R-CNN用于更快速对象检测。
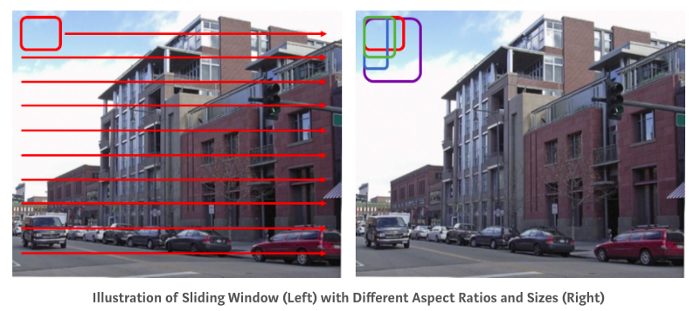
通常,对于每个图像,都有一个滑动窗口来搜索图像中的每个位置,如下所示。这是一个简单的解决方案。然而,不同的物体甚至同一种物体可能有不同的纵横比和尺寸,这取决于物体的大小和与相机的距离。并且不同的图像大小也会影响有效窗口大小。如果我们在每个位置使用深度学习 CNN 进行图像分类,这个过程将非常缓慢。
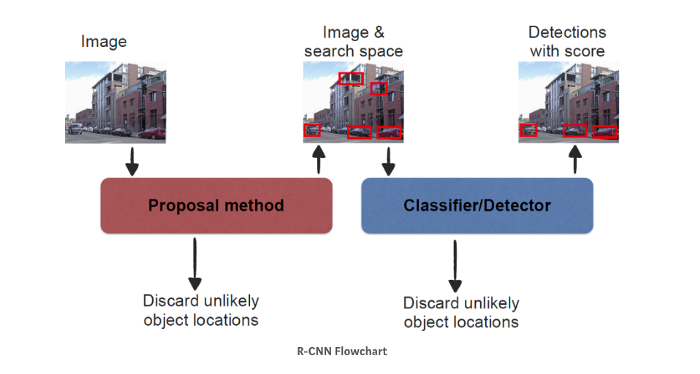
1. 首先,R-CNN 使用选择性搜索生成大约 2000 个区域提议,即用于图像分类的边界框。
2. 然后,对于每个边界框,通过 CNN 完成图像分类。
3. 最后,可以使用回归细化每个边界框。
R-CNN 的问题
- 训练网络需要大量时间,因为你必须对每张图像 2000 个区域建议进行分类。
- 它无法实时实现,因为每个测试图像需要大约 47 秒。
- 选择性搜索算法是一种固定算法。因此,在那个阶段可能会生成糟糕的候选区域提议。
Fast R-CNN
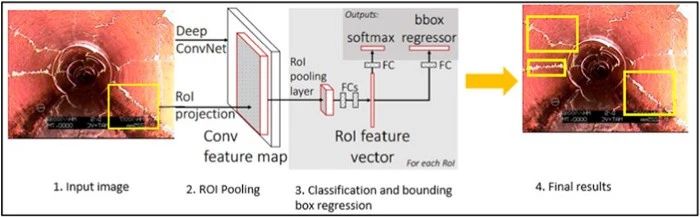
Fast R-CNN 的方法类似于 R-CNN 算法。但是,我们不是将区域建议提供给 CNN,而是将输入图像提供给 CNN 以生成卷积特征图。从卷积特征图中,我们识别出提议的区域并将它们变形为正方形,并通过使用 RoI 池化层将它们重塑为固定大小,以便可以将其馈送到全连接层。从 RoI 特征向量,我们使用 softmax 层来预测提议区域的类别以及边界框的偏移值。
Fast R-CNN的优点
- 比 R-CNN 更快,因为你不必每次都向卷积神经网络提供 2000 个区域建议。
- 每个图像只进行一次卷积操作,并从中生成一个特征图。
Faster R-CNN
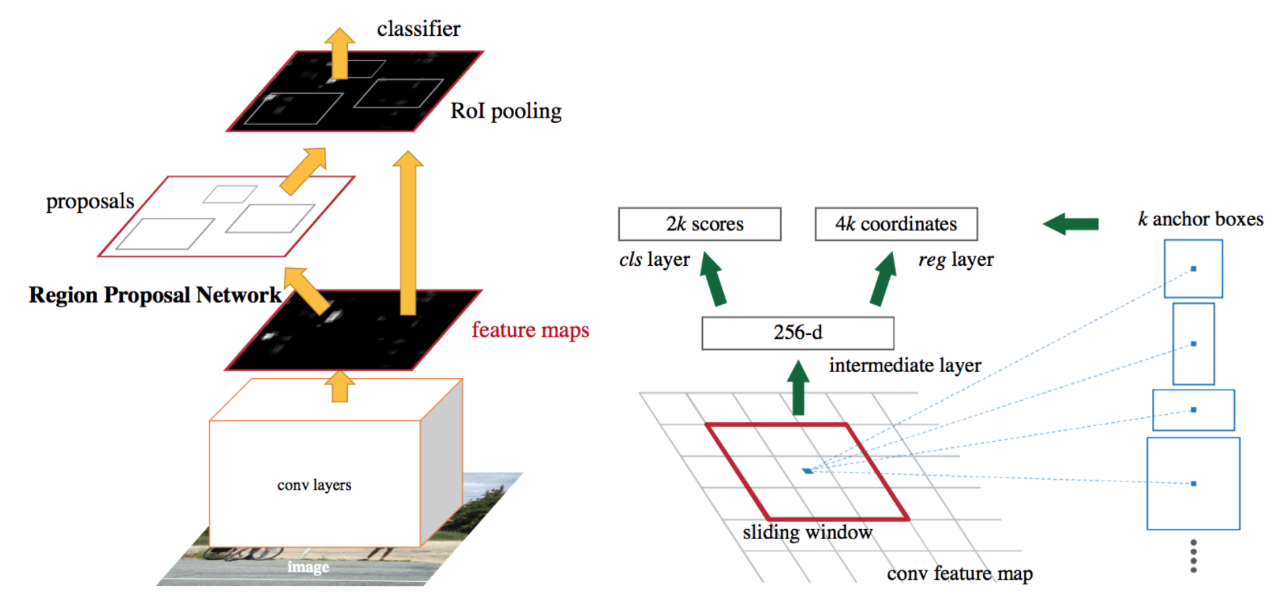
与 Fast R-CNN 类似,图像作为输入提供给提供卷积特征图的卷积网络。不是在特征图上使用选择性搜索算法来识别区域提议,而是使用单独的网络来预测区域提议。然后使用 RoI 池化层对预测的区域建议进行重塑,然后使用 RoI 池化层对建议区域内的图像进行分类并预测边界框的偏移值。
Anchors 在 Faster R-CNN 中扮演着重要的角色。锚点是一个包围盒。在 Faster R-CNN 的默认配置中,图像的一个位置有 9 个锚点。下图显示了大小为 (600, 800) 的图像在位置 (320, 320) 处的 9 个锚点。

让我们仔细看看:
1. 三种颜色代表三种比例或尺寸:128x128、256x256、512x512
2. 让我们挑出红色框/锚点。三个盒子的高宽比分别为 1:1、1:2 和 2:1。
如果我们每 16 步选择一个位置,就会有 1989 (39x51) 个位置。这导致要考虑 17901 (1989 x 9) 个包围盒。尺寸几乎不小于滑动窗口和金字塔的组合。或者这可以解释为什么它的覆盖范围与其他最先进的方法一样好。这里的优点是,我们可以使用区域建议网络(Fast RCNN 中的方法)来显着减少数量。
YOLO — You Only Look Once
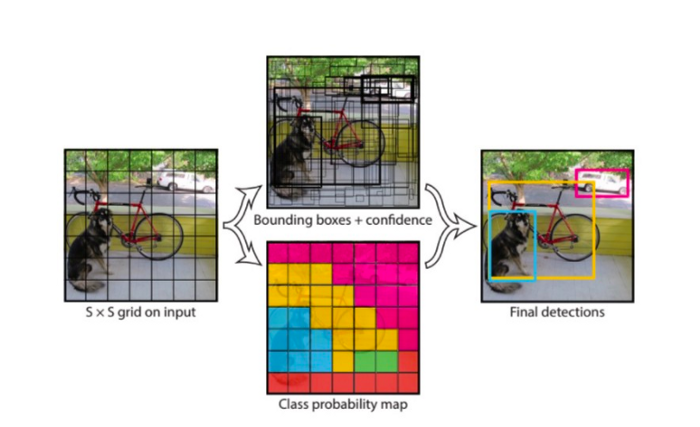
之前的所有对象检测算法都使用区域来定位图像内的对象。网络不会查看完整的图像。相反,图像中包含对象的概率很高的部分。YOLO 或 You Only Look Once 是一种对象检测算法,与上面看到的基于区域的算法大不相同。一个卷积网络就可以预测这些框的边界框和类概率。
YOLO 的工作原理是我们将图像分割成一个 SxS 网格,在每个网格中我们取 m 个边界框。对于每个边界框,网络输出边界框的类概率和偏移值。选择具有高于阈值的类概率的边界框并用于定位图像内的对象。
YOLO的优缺点
- YOLO 比其他物体检测算法快几个数量级(每秒 45 帧)。
- YOLO 算法的局限性在于它在处理图像中的小物体时会遇到困难,例如,它可能难以检测到一群鸟。这是由于算法的空间限制。
SSD- Single Shot MultiBox Detector
对象定位和分类的任务在网络的单次前向传递中完成。MultiBox 是一种边界框回归技术的名称。该网络是一个对象检测器,它也对那些检测到的对象进行分类。
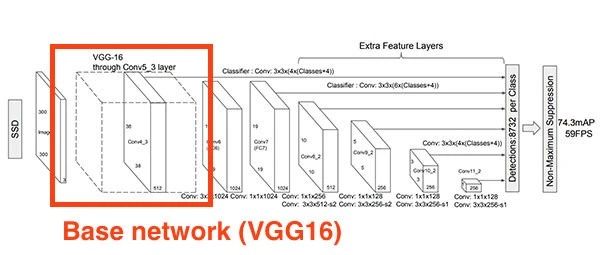
当使用时,你有以下组件和子组件:
- MultiBox
- Priors
- Fixed priors
基本网络只是适合于整个深度学习对象检测框架的众多组件之一—本节顶部的图描述了SSD框架内的VGG16基本网络。
通常,“网络手术”是在基础网络上进行的。本次修改有:
“网络手术科”这个术语是一种通俗的说法,即我们移除基础网络架构的一些原始层并用新层取代它们。网络手术也是非常战术性的——我们移除了我们不需要的网络部分,并用一组新的组件替换它。然后,当我们去训练我们的框架来执行对象检测时,新层/模块和基础网络的权重都会被修改。
SSD的优点
- 在快速性和精确性之间达到了一个更好的平衡,SSD 只对输入图像运行一次卷积网络。
- SSD 还使用了各种长宽比的锚点,SSD 在多个卷积层之后预测边界框,由于每个卷积层都在不同的尺度上运行,因此它能够检测混合尺度的对象。
R-FCN
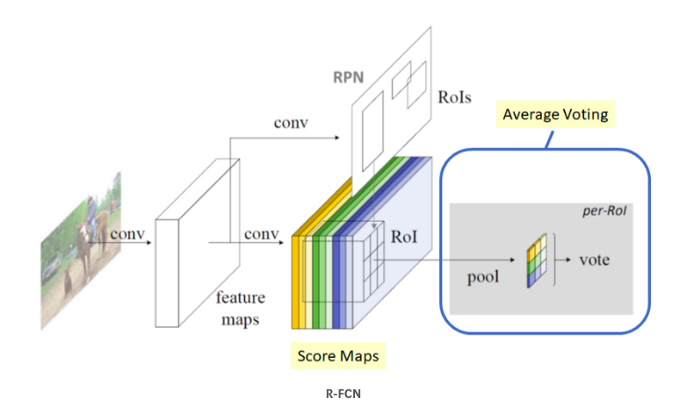
对于传统的区域建议网络(RPN)方法,如 R-CNN、 Fast R-CNN 和 Faster R-CNN,RPN 首先生成区域建议。然后完成 ROI 汇集,并通过完全连接(FC)层进行分类和包围盒回归。
ROI 池化之后的过程(FC 层)在 ROI 之间不共享并且需要时间,这使得 RPN 方法变慢。FC 层增加了连接(参数)的数量,这也增加了复杂性。
R-FCN 的优点
- 在R-FCN中,我们仍然有RPN来获得区域建议,但是与R-CNN系列不 同,ROI池之后的FC层被移除。取而代之的是,所有主要复杂性都在 ROI 池化之前移动以生成分数图。
- 所有的区域建议,经过ROI 池化后,都会使用同一套分数图进行平均投票,计算很简单。因此,在 ROI 层之后没有可学习的层,几乎不耗费时间。因此,R-FCN 甚至比 Faster R-CNN 还要快。
总结
现在我们对目标检测算法有了一个大致的了解,我们可以根据项目实际需求进行选择了~





