来源:新智元
编辑:LRS
导读:强化学习的AI在对抗游戏中表现十分强力,但被虐的只有人类玩家。如果这么强的AI做了队友又该怎么样?MIT最近研究表明,AI和人类玩家之间的配合可以说是没有配合了,根本看不懂队友给的各种暗示信息!
强化学习的AI在围棋、星际争霸、王者荣耀等游戏以绝对的优势碾压了人类玩家,也证明了思维能力可以通过模拟来得到。
但如果这么强的AI成为了你的队友,能被带飞吗?
MIT林肯实验室的研究人员最近的在纸牌游戏Hanabi(花火)中人类和AI agenet之间的合作研究结果表明,尽管RL agent的个人表现能力十分出色,但当跟人类玩家一起匹配的时候,却只会让人直呼太坑。

Hanabi是一个需要玩家之间互相沟通合作取胜的游戏,在这个游戏中,人类玩家更喜欢可预测的基于规则的AI系统,而非黑盒的神经网络模型。
一般来说,最先进的游戏机器人使用的算法都是深度强化学习(deep reinforcement learning)。首先通过在游戏中提供一个agent和一组可能的候选action集合,通过来自环境的反馈机制来进行学习。在训练过程中,还会采用随机的探索action来最大化目标,从而获得最优的action序列。
深增强学习的早期研究依靠人类玩家提供的游戏数据进行学习。最近研究人员已经能够在没有人类数据的情况下,纯粹依靠自我博弈来开发RL agent。
MIT 林肯实验室的研究人员更关注让如此强大的AI 如何成为队友,这项工作也能让我们进一步了解是什么阻碍了强化学习的应用只能局限于电子游戏,而无法扩大到现实应用中。

最近的强化学习研究大多应用于单人游戏(Atari Breakout 打砖块)或者对抗性游戏(星际争霸,围棋),其中AI 主要的对手是人类玩家或者是其他的AI 机器人。
在这些对抗中,强化学习取得了空前的成功,因为机器人对这些游戏并没有一些先入为主的偏见和假设,而是从零开始学习打游戏,并以最好的玩家数据进行训练。
事实上,AI学会打游戏以后,甚至还会自己创造一些技巧。一个有名的例子是DeepMind的alphago在它的比赛中下了一步棋,但分析师当时认为这一步棋是一个错误,因为它违背了人类专家的直觉。
但同样的举动却带来了不一样的结果,AI最后凭借这手成功击败了人类。所以当RL agent与人类合作时,研究人员认为同样的聪明才智也可以发挥作用。
在MIT研究人员的实验中选择了纸牌游戏Hanabi,其中包括两到五名玩家,他们必须合作以特定的顺序出牌。Hanabi 很简单,但它也是一个需要合作和有限的信息的游戏。
Hanabi游戏发明于2010年,由二到五个玩家参与,玩家需以正确的顺序一起打出五种不同颜色的牌。游戏特点:所有玩家都可以看到对方的牌,但却看不到自己的牌。
根据游戏规则,玩家可以互相提示自己手里的牌(但仅限于牌的颜色或数字),让其他玩家可以推断他们应该出什么牌,但提示的次数是有限制的。
正是这种高效沟通的行为使Hanabi具备了一种科学魅力。例如,人类可以很自然地理解其他玩家的提示,哪张卡片是可出的,但是机器本质上无法理解这些提示。
到目前为止人工智能程序已经可以在玩Hanabi花火游戏时赢得很高分数,但只限于与其他类似的智能机器人一起玩。在不熟悉其他玩家的游戏风格或者有「临时」(从未一起玩过的)玩家的情况下,对程序的挑战最大,也更接近真实情况。
近年来,几个研究团队探讨了可以玩Hanabi的AI机器人的发展,其中一些强化学习agent使用符号AI。
AI的评估主要采用他们的性能,包括self-play(和自己玩),cross-play(和其他类型的agent一起玩),Human-play(和人类合作)。
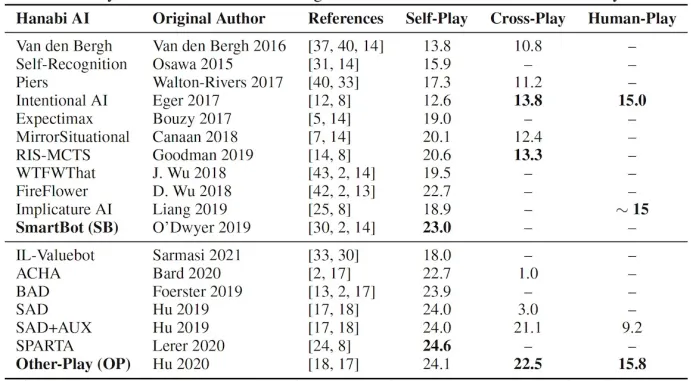
和人类玩家之间的cross-play,对于衡量人与机器之间的合作尤为重要,也是论文实验的基础。
为了检验人工智能协作的有效性,研究人员使用了SmartBot,这是一种基于规则的self-play人工智能系统,还有一种在跨游戏和RL算法中排名最高的模型Hanabi机器人Other-Play。
在实验中,人类参与者与AI agent一起玩了几次Hanabi游戏,每次队友的AI都不相同,实验人员并不知道在和哪个模型一起玩。
研究人员根据客观和主观指标评估了人类AI合作的水平。客观指标包括分数、错误率等。主观指标包括人类玩家的经验,包括他们对AI团队成员的信任和舒适程度,以及他们理解AI动机和预测其行为的能力。
两种人工智能模型的客观表现无显著差异。但研究人员预计,人类玩家对Other-Play有更积极的主观体验,因为他们接受过与其他玩家合作的训练。
根据对参与者的调查,与基于规则的SmartBot Agent相比,经验丰富的Hanabi玩家在其他游戏RL算法方面的经验较少,成功的一个关键点是为其他玩家提供伪装线索的技能。
例如,说「一个方块」卡放在桌子上,你的队友手里拿着两个方块。当你指着卡片说「这是两张」或「这是一个正方形」时,你暗地里告诉你的队友玩这张卡片,而不告诉他关于卡片的全部信息。一个经验丰富的玩家会立刻就能够领会这个提示。但向AI 队友提供相同类型的信息证明要困难得多。
一个参与者表示,我已经给了队友很明显的提示了,但他根本就没用,我不知道为什么。
一个有趣的现实是,Other-play一直在避免创建「秘密」的约定,他们只是在执行self-play时开发的这些预定规则。这使得Other-play成为其他AI算法的最佳队友,尽管AI算法并不是其训练计划的一部分。但研究人员认为,这是他在训练过程中已经假设了会遇到哪些类型的队友。
值得注意的是,Other-play假设队友也针对zero-shot 协调进行了优化。相比之下,人类Hanabi玩家通常不会使用这种假设进行学习。
游戏前常规设置和游戏后复盘是人类Hanabi玩家的常见做法,使人类学习更容易获得few-shot协调的能力。
研究人员表示,目前的研究结果表明,人工智能的客观任务表现(self-play和cross-play)在与其他AI模型合作时,可能与人类的信任和偏好无关。
这就产生了一个问题:哪些客观指标与主观的人类偏好相关?
鉴于训练基于RL的agent所需的数据量巨大,训练环中的人是不可行的。因此,如果我们想训练被人类合作者接受和评估的AI agent,我们需要找到可训练的,可以替代或与人类偏好密切相关的目标函数。
同时,研究人员也说明,不要将Hanabi实验的结果外推到他们无法测试的其他环境、游戏或领域。
论文还承认了实验中的一些局限性,研究人员正在努力解决这些局限性。例如,受试者群体很小(只有29名参与者),并且偏向于精通Hanabi的人,这意味着他们已经预先定义了AI团队成员的行为期望,并且更有可能对RL agent有负面体验。
然而,研究结果对未来加强学习研究具有重要意义。
如果最先进的RL agent甚至不能在一个限制性和窄范围的游戏中成为一个可以接受的合作者,那么我们真的应该期待同样的RL技术在应用于更复杂、更微妙、更具后果性的游戏和现实世界的情况时只是可以用。
在技术和学术领域,关于强化学习的争论很多,而且确实如此,研究结果也表明不应将RL系统的显著性能视为在所有可能的应用中都能获得相同的高性能。
在学习型智能体在复杂的人类机器人交互等情况下成为有效的合作者之前,需要更多的理论和应用工作。





