drawcall,也就是CPU通过调用图形接口,向GPU请求绘制数据的过程。
CPU发出的请求会被封装成一个命令,并加入到命令队列。GPU执行完当前命令后,就会从命令队列再取一个命令执行。命令队列中,除了drawcall请求,还有状态切换的请求等。
drawcall优化对性能的影响主要体现在以下两个方面:
① 分批多次请求drawcall相比起一次请求drawcall,会多出一些接口调用的开销;
② 每次drawcall请求,会传输绘制网格数据和状态数据等,因此每次提交是比较耗时的。这种耗时主要体现在,CPU需要处理的事情太多,因此跟不上GPU的处理速度;
为了提升性能,我们应该尽可能减少drawcall的次数,或者加快渲染数据的准备。一般来说,我们有如下的优化思路:
减少绘制物体数量
视锥体剔除
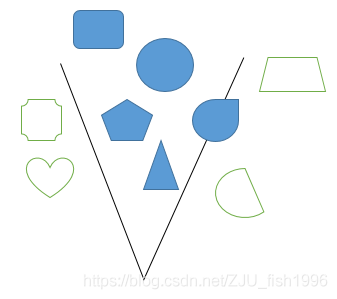
CPU中,每帧在准备渲染所需数据之前,我们会对所有物体做一个遍历,判断它是否落在视锥体内,并剔除那些不在视锥体内的物体。减少最终提交到GPU的物体数量。
小物体视距剔除
对于一些距离较远的小物体,是否进行绘制对画面影响不大,比如远处某个角色身上的一颗扣子。
我们通常使用屏幕大小(screen size)来衡量是否为小物件,物体到相机的距离和物体原本大小都会影响物体最终的屏幕大小。
因此,我们通常会制定一套规则,即当视距达到特定距离时,将不绘制小于特定大小的物体,这一规则可以表达为一条曲线。
遮挡剔除
若一个物体完全遮挡了另一物体,被遮挡的物体应该被剔除。
pass合并
场景中的物体一般都是多pass的,每多一个pass意味着多一次drawcall调用。
因此,除非无法合并,我们会尽可能将计算放在一个pass中,而不是分开。比如阴影写深度需要不同的相机视图,因此无法合并。
其它
还有一些宏观上的策略,比如AOI,Streaming等一些策略,主要是对场景中对象的管理,它们对drawcall优化也有一定帮助。
合并drawcall
接下来,我们考虑通过合并等方式减少drawcall的方式。
批处理
批处理也就是把相同材质/贴图/shader,仅顶点数据不同的物体合并到一起,仅进行一次drawcall。
为了能够通过批处理进行优化,首先在美术设计层面就要尽可能提升材质的复用性,否则即使引擎底层做了批处理的优化也是不起效果的。
批处理一般分为静态合并和动态合并。其中静态合并针对场景中静态物体,它会在编辑状态下预合并;而动态合并针对场景中的动态物体,它会在运行时动态检测引用相同材质的物体并合并,会带来一定的运行时性能消耗。
由于一次提交的数据是有上限的,所以合并也不是无限制的,对于无法一次合并的物体,会被拆分到多个drawcall中。
实例化
当我们需要绘制大量相同的顶点时,我们通常需要大量的drawcall请求,并且会传输大量重复数据。
对于大量重复物体,我们可以考虑使用图形接口提供的实例化渲染支持。绘制n个相同的物体,原本需要n次drawcall,使用实例化渲染后,只需一次drawcall。
顶点等数据只需有一份拷贝,每个物体各自的数据(如平移、旋转数据)按序存储在instancebuffer中。
远景代理
最后,我们考虑对远景物体做一些简化,来达到减少drawcall的目的。
合并和简化网格体
对于远处的静态物体,我们可以把多个物体合并到一起,同时进行减面操作。合并和简化后,多个物体的结合体的顶点数理想中应该比原本单个物体还要少。
更进一步的,我们做LOD优化,考虑对不同视距的物体生成不同的合并网格体。
这一技术不仅可以减少drawcall,也可以降低带宽压力。
公告牌/烘焙
对于一些物体,我们可以把它LOD的最后一级直接替换为公告牌,再结合第一点合并的优化,带来的优化是非常显著的。
绘制到公告牌上相当于把3D物体2D化,这需要我们使用至少两个三角形来绘制。如果绘制的物体较小,我们还可以更进一步,把这两个三角形也省略了,直接把物体烘焙到地表。
多线程生成drawcall
为了加速CPU和GPU之间的交互,使CPU能够更快地准备渲染数据,引擎通常都会支持多线程渲染。具体而言,体现在以下几个方面:
① 包含多个线程。主线程负责调度和逻辑更新,渲染线程负责准备渲染数据,发起渲染请求;有些引擎还会给图形API设置新的线程;
② 多线程或异步发起drawcall,配合多个命令队列,在图形API层面实现多线程渲染;
GPUDriven
目前渲染比较传统的做法是,CPU控制整个渲染流程,GPU负责执行CPU指令,概括而言,就是CPUDriven的意思。
这样的做法一是带来CPU和GPU通信的开销;二是由于CPU和GPU同步引起开销。因此,有一个想法是,可以直接由GPU来驱动整个渲染流程,这样就可以省去很多不必要的开销。
相关的网格体、纹理数据还是需要从CPU传往GPU,不过,此时,渲染命令主要通过GPU中的计算着色器控制。
本文摘自:CSDN博主「ZJU_fish1996」的原创文章《[引擎开发] 深入GPU和渲染优化(基础篇)》,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/ZJU_fish1996/article/details/109269448





