来源:CSDN - 独孤呆博
本篇博客主要内容参考图书《神经网络与深度学习》,李航博士的《统计学习方法》National Taiwan University (NTU)李宏毅老师的《Machine Learning》的课程,在下文中如果不正确的地方请积极指出。
1. 为什么要使用卷积神经网络
使用全连接层的网络来分类图像是很奇怪的,因为这样的一个网络架构不考虑图像的空间结构。所以一个很直接的考虑就是引入图像的一种空间关系来构建神经网络,也就是这里要介绍的卷积神经网络(CNN)。
正是由于考虑了空间结构,所以卷积神经网络可以更快的训练,从而获得一个深度的、多层的神经网络,并可以在图像分类上获得较好的结果。
2. CNN 中的基本概念
在这里我们将介绍 CNN 中的主要的三个概念,即:局部感受野(local receptive fields),共享权重(shared weights),和池化(pooling)。
2.1 局部感受野
对于输入的图像,在这里并不会像之前的全连接神经网络一样按行排列成一个长的向量,而是仍然保持其原有的样子,如下所示

如图1所示为卷积神经网络的输入神经元排列方式,实际上因为输入神经元与像素是一一对应的关系,所以也可以看作是输入的图像。在这里我们不会把每个输入像素连接到每个隐藏神经元。相反,我们只是把输入图像进行小的、局部区域的连接。说的确切一点,第一个隐藏层中的每个神经元会连接到一个输入神经元的一个小区域(例如一5×5个的区域,对应于25个输入像素)。所以对于一个特定的隐藏神经元,我们可能有看起来像图2的连接:

这个输入图像的区域被称为隐藏神经元的局部感受野,它是输入像素上的一个小窗口。每个连接学习一个权重。而隐藏神经元同时也学习一个总的偏置。你可以把这个特定的隐藏神经元看作是在学习分析它的局部感受野。
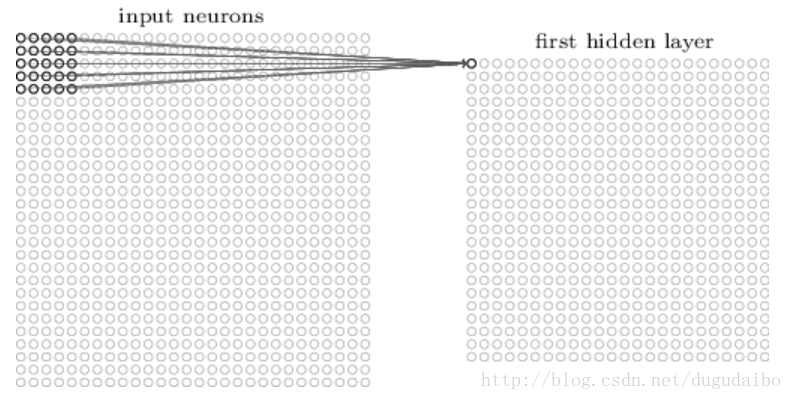
我们然后在整个输入图像上交叉移动局部感受野。对于每个局部感受野,在第一个隐藏层中有一个不同的隐藏层神经元。为了正确说明,让我们从左上角开始一个局部感受野:
然后我们往右一个像素(即一个神经元)移动局部感受野,连接到第二个隐藏神经元:
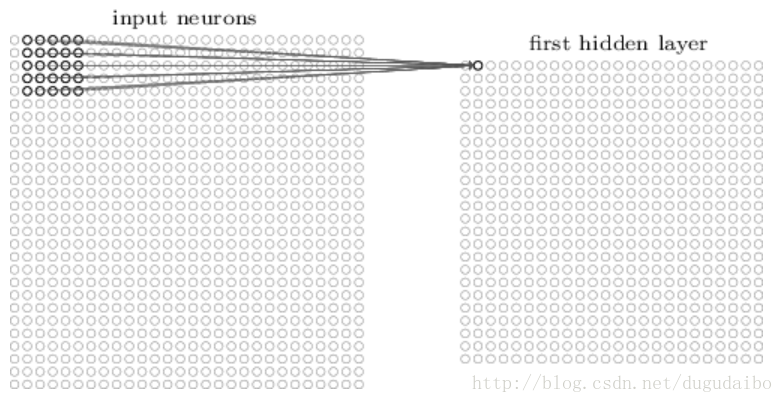
如此重复,构建起第一个隐藏层。注意如果我们有一个 28×28 的输入图像,5×5 的局部感受野,那么隐藏层中就会有 24×24 个神经元。在这里每次移动的过程是一个像素,即步长为1,有的时候步长也可以是2。
2.2 共享权重和偏置
按照上面的说明过程,对于每一个给定的局部感受野有一个对应的隐层的神经元,比如一个5×5的感受野所对应的隐层的神经元应该具有25个权值和1个偏置。而通过上面的分析可以知道,隐层中共有 24×24 个神经元,所以共有25×24×24 个权值和 24×24 个偏置,但是在卷积神经网络中却不是这样的,因为这样的计算量过大。在这里,对 24×24 个隐藏神经元中的每一个使用相同的权重和偏置,也就是说共用一个 5×5 的权值和 1 个偏置。
这意味着第一个隐藏层的所有神经元检测完全相同的特征,只是在输入图像的不同位置,这一点与图像处理中的卷积的概念是一致的,我猜测这就它叫卷积神经网络的原因吧。把权重和偏置设想成隐藏神经元可以挑选的东西,例如,在一个特定的局部感受野的垂直边缘。这种能力在图像的其它位置也很可能是有用的。因此,在图像中应用相同的特征检测器是非常有用的。用稍微更抽象的术语,卷积网络能很好地适应图像的平移不变性:例如稍稍移动一幅猫的图像,它仍然是一幅猫的图像。
因为这个原因,我们有时候把从输入层到隐藏层的映射称为一个特征映射。我们把定义特征映射的权重称为共享权重。我们把以这种方式定义特征映射的偏置称为共享偏置。共享权重和偏置经常被称为一个卷积核或者滤波器。
目前我描述的网络结构只能检测一种局部特征的类型。为了完成图像识别我们需要超过一个的特征映射,所以一个完整的卷积层由几个不同的特征映射组成,如下图所示
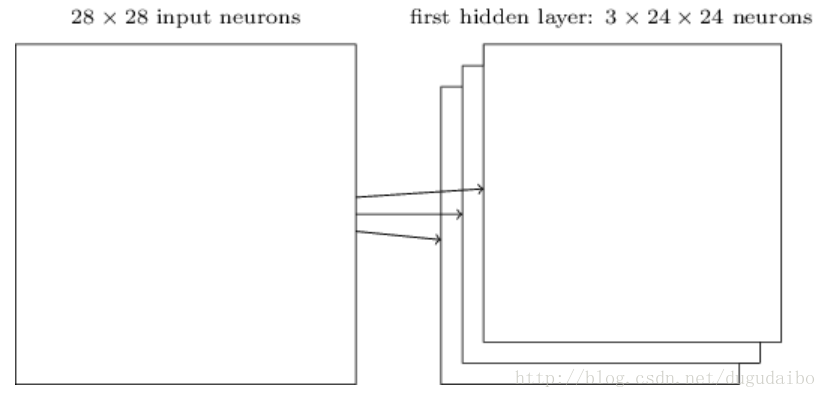
在这个例子中,每个特征映射定义为一个 5×5 共享权重和单个共享偏置的集合。其结果是网络能够检测3种不同的特征,每个特征都在整个图像中可检测。在实际使用的过程中可以使用更过的卷积核。
共享权重和偏置的一个很大的优点是,它大大减少了参与的卷积网络的参数。
2.3 池化层
池化层通常紧接着在卷积层之后使用,简化从卷积层输出的信息。一种常见的池化方法为最大池化方法,它简单地输出其 2×2 输入区域的最大激活值,具体如图6所示
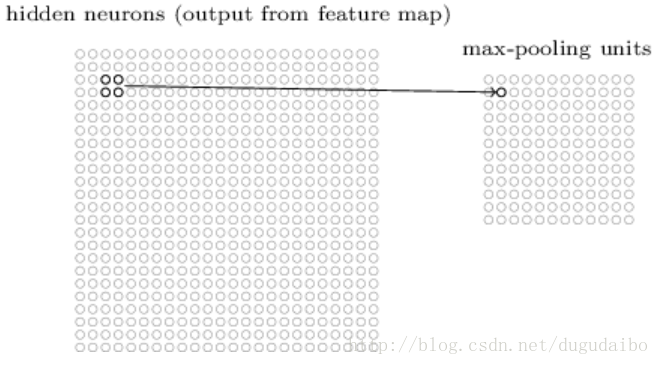
注意既然从卷积层有 24×24 个神经元输出,池化后我们得到 12×12 个神经元。同样的对于每一个卷积层的输出都可以进行池化。我们可以把最大值池化看作一种网络询问是否有一个给定的特征在一个图像区域中的哪个地方被发现的方式。然后它扔掉确切的位置信息。直观上,一旦一个特征被发现,它的确切位置并不如它相对于其它特征的大概位置重要。一个很大的好处是,这样可以有很多被更少地混合的特征,所以这有助于减少在以后的层所需的参数的数目。最大值混合并不是用于混合的仅有的技术,另一个常用的方法是L2 混合(L2 pooling)。
3. 卷积神经网络的总体过程
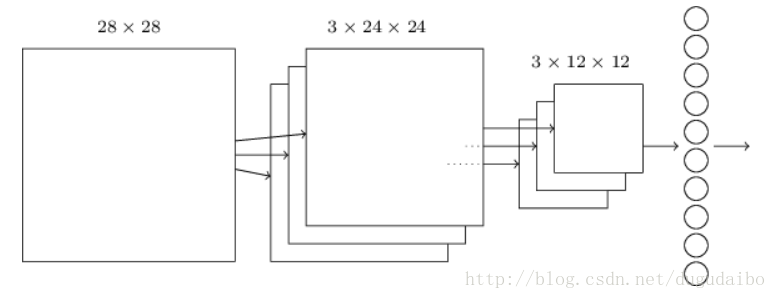
这个网络从 28×28 个输入神经元开始,这些神经元用于对 MNIST 图像的像素强度进行编码。接着的是一个卷积层,使用一个 5× 5局部感受野和 3 个特征映射。其结果是一个3×24×24 隐藏特征神经元层。下一步是一个最大值池化层,应用于 2×2 区域,遍及3个特征映射,结果是一个 3×12×12 隐藏特征神经元层。网络中最后连接的层是一个全连接层。更确切地说,这一层将最大值池化层的每一个神经元连接到每一个输出神经元,和我们之前章节中使用的相同。
4. 卷积神经网络的反向传播过程
我们确实需要对反向传播程序做些修改。原因是我们之前的反向传播的推导是针对全连接层的网络。幸运的是,针对卷积和最大值混合层的推导是简单的。在一个具有全连接层的网络中,反向传播的核心方程是(BP1)–(BP4)。假设我们有这样一个网络,它包含有一个卷积层,一个最大值混合层,和一个全连接的输出层,正如上面讨论的那样。
具体过程留一个坑,日后来填。
版权声明:本文为CSDN博主「独孤呆博」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/dugudaibo/article/details/78141566





