作者:Sergey Nikolenko
编译:ronghuaiyang
导读
本文讨论使用生成数据集来做目标检测的一些基础概念。
今天,我们开始一系列专门讨论一个特定的机器学习问题,这个问题通常由合成数据来补充:物体检测。在这个系列的第一篇文章中,我们将讨论什么是目标检测,以及数据从哪里来,以及如何让你的网络来检测物体的边界框下面。

问题设定:什么是物体检测
如果你有过计算机视觉方面的经验,或者听过许多关于现代深度学习的神奇之处的介绍,你可能知道图像分类问题:如何区分猫和狗?
尽管这只是一个二元分类(一个回答是/否的问题),但这已经是一个非常复杂的问题了。真实世界的图像“生活”在一个非常高维的空间中,以数百万计的特征为数量级:例如,从数学上讲,一张一百万像素的彩色照片是一个超过三百万数字的向量!因此,图像分类的重点不在于实际学习决策面(分离类),而在于特征提取:我们如何将这个巨大的空间投射到更易于管理的东西上,而分割平面可以相对简单?
这正是深度学习取得如此成功的原因:它不依赖于人们以前用于计算机视觉的手工功能SIFT,而是从零开始学习自己的特征。分类器本身仍然非常简单和经典:几乎所有用于分类的深度神经网络都带有一个softmax层,即基本的逻辑回归。关键是如何将图像空间转换为逻辑回归足够的表示,而这正是网络的其他部分的切入点。如果你看一些早期文章你可以找到例子,人们学习深度神经网络提取特征,然后应用其他分类器,如支持向量机:
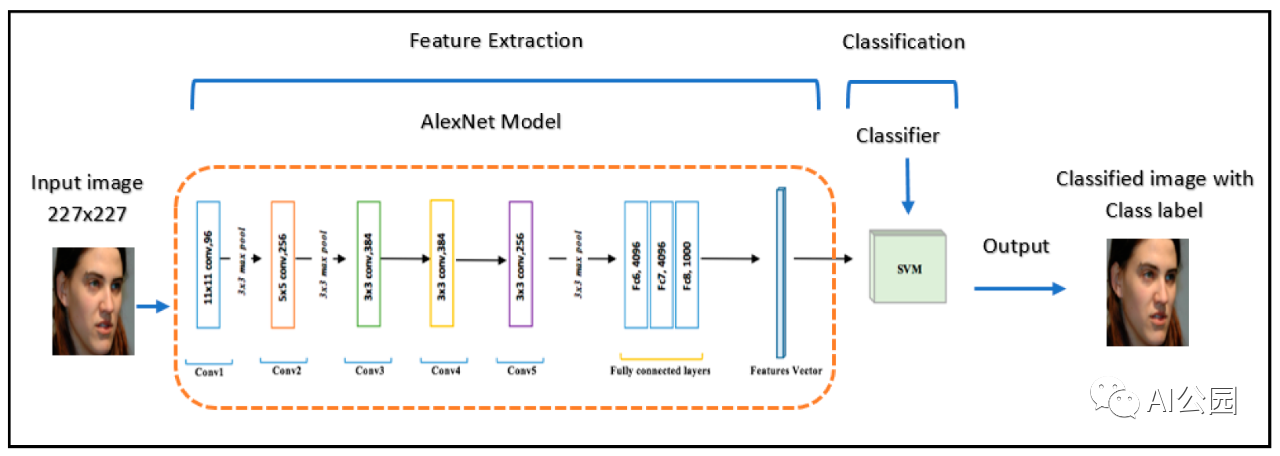
但到目前为止,这是很少见的:一旦我们有足够的数据来训练最先进的特征提取器,在最后进行简单的逻辑回归就容易得多,也足够了。在过去的十年里,人们已经开发了大量的图像特征提取器:AlexNet, VGG, Inception, ResNet, DenseNet, EfficientNet……
要把它们全部解释清楚,光靠一篇博客文章是远远不够的,但常见的思路是,你有一个特征提取主干,后面跟着一个简单的分类层,然后你在一个大型图像分类数据集中从头到尾地训练整个东西,通常是ImageNet,这是一个巨大的人工标记和管理的数据集,有超过1400万张图片,标记了近22000个类别,以语义层次组织:

一旦你完成了这些,网络已经学会了为真实世界的摄影图像提取信息丰富的、有用的特征,所以即使你的类不是来自ImageNet,它也通常是一个调整以适应这个新信息的问题。当然,你仍然需要新的数据,但通常不是数以百万计的图像。当然,除非这是一个完全新颖的图像领域,如x射线或显微镜,在那里ImageNet不会有太大帮助。
但视觉并不是这样工作的。当我环顾四周,我在脑海中看到的不仅仅是单一的标签。我在我的视野中区分不同目标:现在我看到了键盘,我自己的手,一个监视器,一个咖啡杯,一个网络摄像头等等,基本上是在同一时间。我能够从一个单一的静止图像中同样区分所有这些物体。
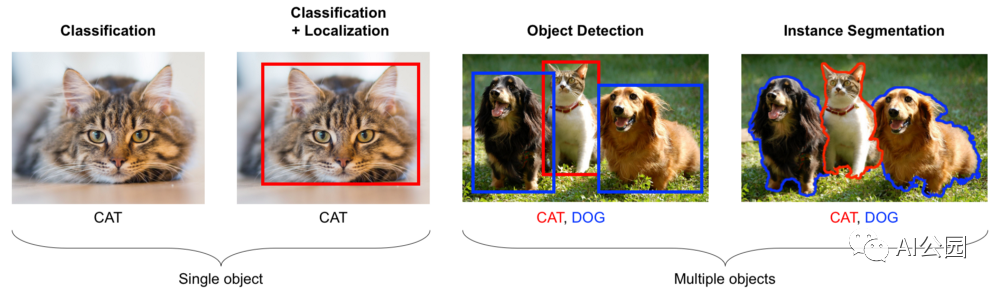
这意味着我们需要从分类开始继续下去、分类时为整个图像分配一个标签(你可以分配多个multilabel分类模型,但是他们仍然是整个图像打标签),其他问题,需要更细粒度的分析图像中的目标。
人们通常会区分几种不同的问题:
- 分类,就像我们上面讨论的那样。
- 分类 + 定位,你假设图像中只有一个中心目标,你需要去定位这个目标,画一个包围框出来。
- 物体检测,我们今天的主题,需要在一张图像中找到多个目标,并框出来。
- 最后,分割是更加复杂的问题,你需要找到物体的实际轮廓,即,基本上把图像上的每一个像素划分为一个物体或背景,分割也有几种不同的方式(语义分割、边界分割和实例分割)。
用猫和狗解释如下:
从数学上讲,这意味着网络的输出不再仅仅是一个类标签。它现在是几个不同的类标签,每个都有相关联的矩形。矩形由四个数字定义(两个相对角的坐标,或一个角的坐标,宽度和高度),所以现在每个输出在数学上是四个数字和一个类标签。
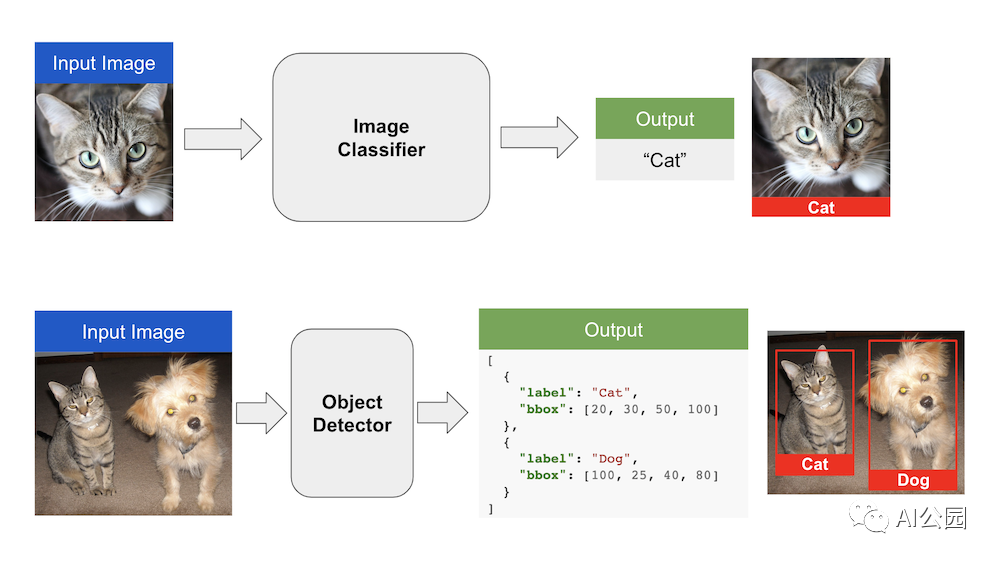
从机器学习的角度来看,在我们开始思考如何解决问题之前,我们需要找到数据。基本的ImageNet数据集没有什么用:它是一个分类数据集,所以它有像“Cat”这样的标签,但是它没有边界框!手动标注现在是一个更困难的问题:你必须为每个目标提供一个边界框,而不仅仅是点击正确的类标签,而且在一张照片上可能有许多目标。
下面是一个用于通用目标检测问题的标注的例子。

你可以想象,为目标检测而手动标注一幅图像需要整整几分钟,而不是像用于分类那样需要几秒钟。那么像这样的大型数据集从何而来呢?
目标检测数据集:真实
让我们首先看看我们有什么样的使用真实目标和人工标注的目标检测数据集。首先,让我们快速回顾最流行的数据集。
ImageNet数据集作为ImageNet大规模视觉识别挑战(ILSVRC)的关键部分而受到欢迎,这是2010年至2017年举办的一系列比赛。ILSVRC系列见证了一些卷积神经网络中最有趣的进展:AlexNet、VGG、GoogLeNet、ResNet和其他著名的架构都在这里首次亮相。
一个不太为人所知的事实是ILSVRC也一直有一个物体检测竞赛,而ILSVRC系列实际上是与另一个著名的竞赛合作发展起来的,2005年至2012年举办的PASCAL Visual Object Classes (VOC) Challenge。这些挑战也从一开始就体现了目标检测,这就是第一个著名的数据集的由来,通常被称为PASCAL VOC数据集。
以下是“飞机”和“自行车”类别的一些示例图片:


按照今天的标准,PASCAL VOC是相当小的:20个类,只有11530张图片,27450个目标标注,这意味着PASCAL VOC每幅图片只有不到2.5个目标。目标通常是相当大的和突出的照片,所以PASCAL VOC是一个“容易”的数据集。尽管如此,在很长一段时间里,它仍然是最大的手动标注的目标检测数据集之一,并在数百篇关于目标检测的论文中默认使用。
在规模和复杂性方面的下一步是Microsoft Common Objects in Context (Microsoft COCO)数据集。到目前为止,它已经超过200K带有150万个目标实例的标记图像,它不仅提供了边界框,而且还提供了(相当粗糙的)分割轮廓。
以下是一些示例图片:

正如你所看到的,现在的目标更加多样化,它们可以有非常不同的大小。这实际上是一个物体检测的大问题:很难让一个单一的网络同时检测大大小小的物体,这也是为什么MS COCO被证明是一个比PASCAL VOC更难的数据集的主要原因。数据集仍然是非常相关的,在目标检测,实例分割和其他赛道每年举行比赛。
我想谈论的最后一个通用目标检测数据集是目前最大的可用数据集:谷歌的Open Images Dataset。到目前为止,他们到了Open Images V6,它有大约190万张图片和1600万个边界框600个目标类。这相当于每幅图像有8.4个边界框,所以场景相当复杂,物体的数量也更加均匀分布:

这些例子看起来有趣、多样,有时非常复杂:


实际上,Open Images之所以成为可能,是因为目标检测本身的进步。如上所述,手工绘制边界框非常耗时。幸运的是,在某种程度上,现有的目标检测器变得非常好,以至于我们可以将边界框委托给机器学习模型,而只用人类来验证结果。也就是说,你可以将模型设置为一个相对较低的灵敏度阈值,这样你就不会错过任何重要的信息,但结果可能会有很多误报。然后请人工标注确认正确的边界框并拒绝误报。
据我所知,这一范式的转变发生在2016年前后Papadopoulos等人的一篇论文之后。它更易于管理,这就是Open Images成为可能的原因,但是对于人类标注者来说,它仍然有很多工作要做,所以只有像谷歌这样的巨人才能提供如此规模的目标检测数据集。
当然,还有更多的对象检测数据集,通常用于更专门的应用程序:这三个是覆盖通用目标检测的主要数据集。但等等,这是一个关于合成数据的博客,我们还没有说过一个字!让我们解决这个问题。
目标检测数据集:为什么要合成数据?
有了像Open Images这样的数据集,主要的问题就变成了:我们到底为什么需要合成数据来进行目标检测?Open Images看起来几乎和ImageNet一样大,我们还没有听说过很多关于图像分类的合成数据。
对于目标检测,答案在于细节和具体的用例。是的,Open Images很大,但它并不能覆盖你可能需要的所有内容。举个恰当的例子:假设你正在为一辆自动驾驶汽车构建一个计算机视觉系统。当然,Open Images有“Car”类别,但你需要更多的细节:不同交通情况下的不同类型的汽车、路灯、各种类型的行人、交通标志等等。如果你所需要的只是一个图像分类问题,那么你可以为新类创建自己的数据集,每个类包含几千张图像,手工为其贴上标签,并为新类调整网络。在目标检测,特别是分割中,它就不那么容易工作了。
考虑一下最新和最大的自动驾驶真实数据集:Caesar et al.的nuScenes,顺便说一下,这篇论文已经被CVPR 2020接受了。他们创建了一个包含6个摄像机、5个雷达和1个激光雷达的完整数据集,并使用3D边界框(这是我们走向3D场景理解的新标准)和人类场景描述进行了充分标注。以下是数据的一个样本:
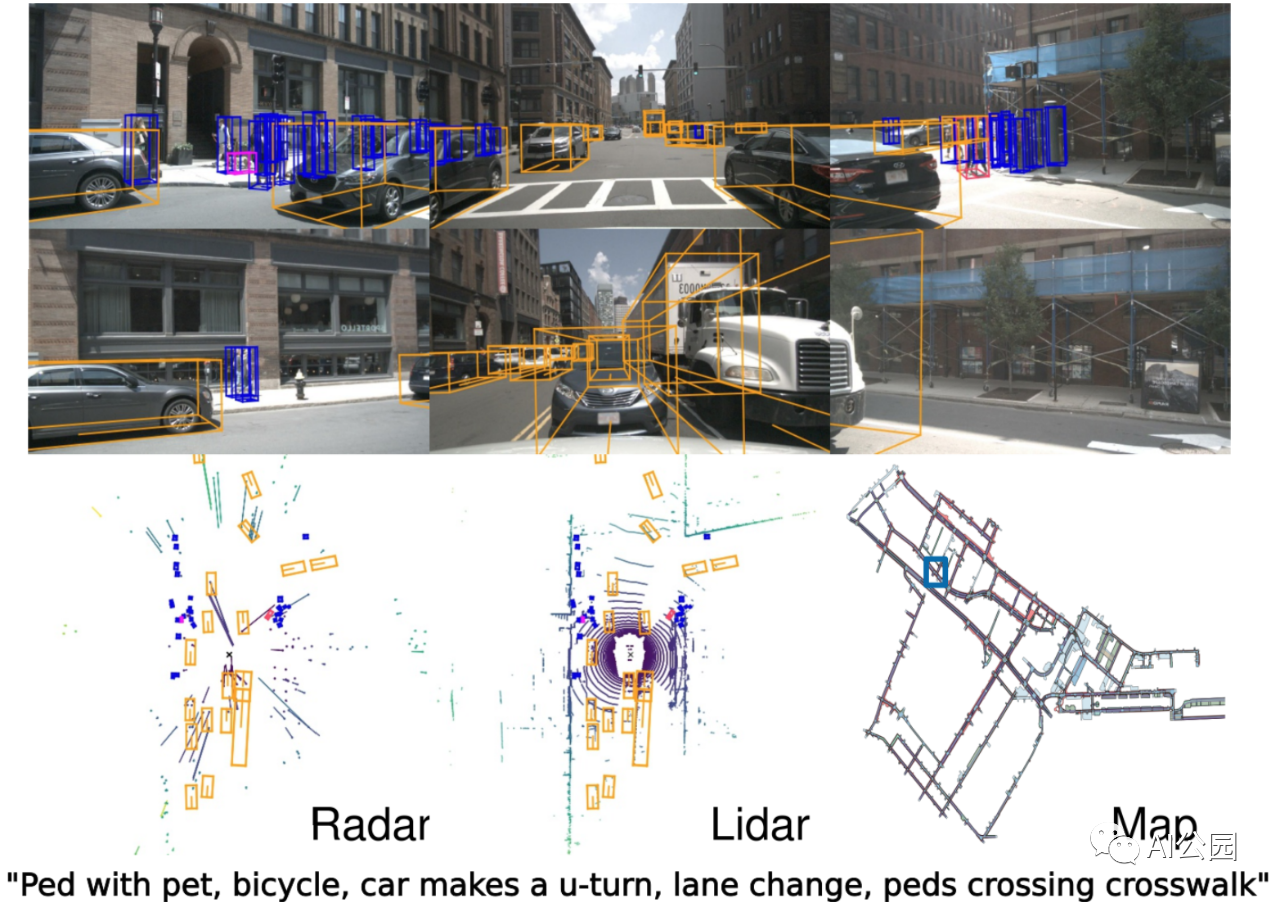
所有这些都是在视频中完成的!nuScenes数据集包含1000个场景,每20秒以2Hz的频率进行关键帧采样,所以总共有40000张非常相似的40张标注图像(来自同一个场景)。给这类数据贴上标签已经是一项庞大而昂贵的工作。
将其与名为ProcSy的自动驾驶合成数据集进行比较。它的特点是像素完美的分割(使用合成数据,没有区别,你可以像要求分割边界框一样简单),使用CityEngine构建深度地图的城市场景与交通,然后用虚幻引擎渲染。它看起来像这样(带有分割、深度和遮挡图):

在论文中,比较了不同分割模型在恶劣天气条件和其他可能使问题复杂化的因素下的性能。为此,他们只需要11000帧的小数据样本,这就是你可以从上面的网站下载的(顺便说一下,压缩文件就有30Gb)。他们报告说,这个数据集是从135万可用的道路场景中随机抽取的。但最重要的部分是数据集是程序生成的,所以实际上它是一个潜在的无限数据流,你可以改变地图、交通类型、天气状况等等。
这是合成数据的主要特点:一旦你预先投资创建(或者更准确地说,寻找和调整)你感兴趣的目标的3D模型,你就可以拥有尽可能多的数据。如果你做了额外的投资,你甚至可以转向全尺寸交互式3D世界,但这又是另一个故事了。
本文转自:AI公园,作者:Sergey Nikolenko,编译:ronghuaiyang,转载此文目的在于传递更多信息,版权归原作者所有。





