来源:CSDN - 独孤呆博
本博客主要内容为图书《神经网络与深度学习》和National Taiwan University (NTU)林轩田老师的《Machine Learning》的学习笔记,因此在全文中对它们多次引用。初出茅庐,学艺不精,有不足之处还望大家不吝赐教。
理论上讲S型神经元构建起来的神经网络可以计算任意函数,但实践中使用其他神经元有时效果会好于S型神经元。对于不同的应用,其他类型的神经元组成的神经网络可能学习得更快或者在测试机上泛化的更好。
1. tanh 神经元
tanh [‘tæn] 神经元使用双曲正切(hyperbolic tangent)函数替换了 S 型函数,即
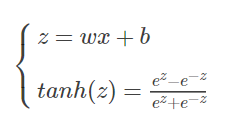
进行简单的代数运算,我们可以得到
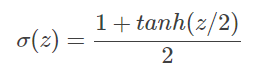
因此可以将 tanh 神经元看作是 S 型神经元按比例变化的版本。
绘制出tanh 神经元的形状如图1
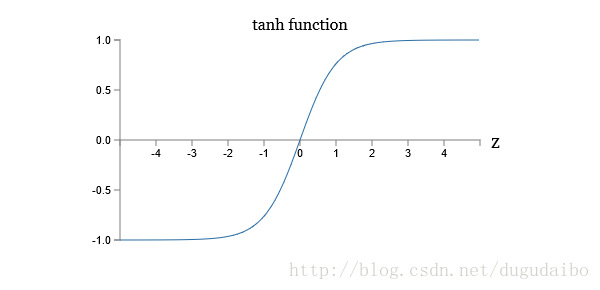
tanh 神经元与 S 型神经元之间的一个差异就 tanh 神经元的输出的值域是 (−1,1)(−1,1),而 S 型神经元输出的值域是 (0,1)(0,1),所以常常将tanh 神经元应用于需要将最终的输出进行正则化的神经网络中。并且之前提到的反向传播和随机梯度下降的方法也可以用于这个神经元上。
存在一些理论论点和实践证据表明 tanh 有时候表现更好。从启发式的角度考虑,假设现在只考虑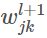 ,由反向传播的规则可以知道相关梯度为
,由反向传播的规则可以知道相关梯度为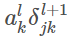 。因为所有的激活值都是正数,所以梯度的符号就和
。因为所有的激活值都是正数,所以梯度的符号就和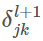 一致。这意味着如果 为正,那么所有的权重都会在梯度下降时减少,而如果为负,那么所有的权重都会在梯度下降时增加。换言之,针对同一的神经元的所有权重都会或者一起增加或者一起减少。这就有问题了,因为某些权重可能需要有相反的变化。这样的话,只能是某些输入激活值有相反的符号才可能出现,所以用 tanh 替换就能够达到这个目的。因为 tanh 是关于 00 对称的,我们甚至期望隐藏层的激活值能够大概地在正负间保持平衡,这样其实可以保证对权重更新没有系统化的单方面的偏置。然而实际上,对很多任务,tanh 在实践中给出了微小的甚至没有性能提升。
一致。这意味着如果 为正,那么所有的权重都会在梯度下降时减少,而如果为负,那么所有的权重都会在梯度下降时增加。换言之,针对同一的神经元的所有权重都会或者一起增加或者一起减少。这就有问题了,因为某些权重可能需要有相反的变化。这样的话,只能是某些输入激活值有相反的符号才可能出现,所以用 tanh 替换就能够达到这个目的。因为 tanh 是关于 00 对称的,我们甚至期望隐藏层的激活值能够大概地在正负间保持平衡,这样其实可以保证对权重更新没有系统化的单方面的偏置。然而实际上,对很多任务,tanh 在实践中给出了微小的甚至没有性能提升。
2. ReLU
修正线性神经元(rectified linear neuron)或者修正线性单元(rectified linear unit),简记为 ReLU。输入为 x ,权重向量为 w ,偏置为 b 的 ReLU 神经元的输出是
该函数的图像如图2
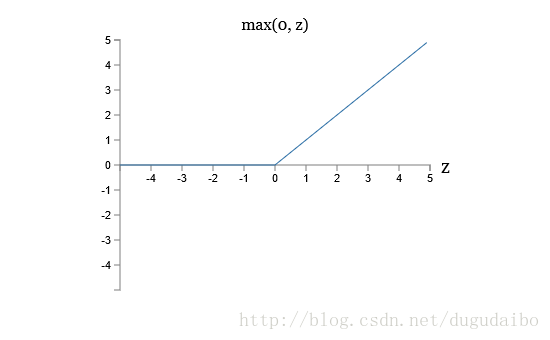
虽然函数形状与之前的两种神经元的形状不同,但是 ReLU 也可以计算任意函数,采用反向传播方法和随机梯度下降的方法。
从启发性的角度考虑这种神经元的优点主要在于两点。首先提高 ReLU 的权值输入并不会导致其饱和,所以就不存在前面那样的学习速度下降。另外,当权值输入是负数的时候,梯度就消失了,所以神经元就完全停止了学习。
3. 小节
只是在某些论文上有关于某一种神经元适合某一种应用的讨论,具体如何根据所面临的问题仍是一个待研究的问题。
版权声明:本文为CSDN博主「独孤呆博」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/dugudaibo/article/details/77774969





