超分辨率重建技术(Super-Resolution)是指从观测到的低分辨率图像重建出相应的高分辨率图像。
SR可分为两类:
① 从多张低分辨率图像重建出高分辨率图像
② 从单张低分辨率图像重建出高分辨率图像。
基于深度学习的SR,主要是基于单张低分辨率的重建方法,即Single Image Super-Resolution (SISR)
一、基于深度学习的超分辨率重建方法整理
1、SRCNN
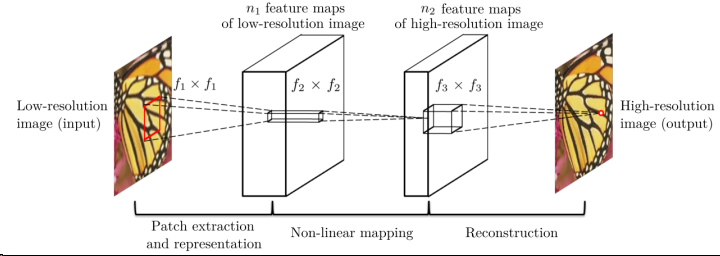
Super-Resolution Convolutional Neural Network(PAMI 2016, 代码)
该方法对于一个低分辨率图像,先使用双三次(bicubic)插值将其放大到目标大小,再通过三层卷积网络做非线性映射,得到的结果作为高分辨率图像输出。
2、DRCN
Deeply-Recursive Convolutional Network for Image Super-Resolution(CVPR 2016, 代码)
使用更多的卷积层增加网络感受野(41x41),同时为了避免过多网络参数,该文章提出使用递归神经网络(RNN)。
与SRCNN类似,该网络分为三个模块,第一个是Embedding network,相当于特征提取,第二个是Inference network, 相当于特征的非线性变换,第三个是Reconstruction network,即从特征图像得到最后的重建结果。其中的Inference network是一个递归网络,即数据循环地通过该层多次。将这个循环进行展开,就等效于使用同一组参数的多个串联的卷积层,如下图所示:
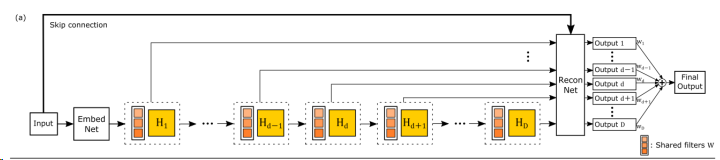
其中的H1到HD是D个共享参数的卷积层。DRCN将每一层的卷积结果都通过同一个Reconstruction Net得到一个重建结果,从而共得到D个重建结果,再把它们加权平均得到最终的输出。另外,受到ResNet的启发,DRCN通过skip connection将输入图像与Hd的输出相加后再作为Reconstruction Net的输入,相当于使Inference Net去学习高分辨率图像与低分辨率图像的差,即恢复图像的高频部分。
3、ESPCN
Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network(CVPR 2016, 代码)
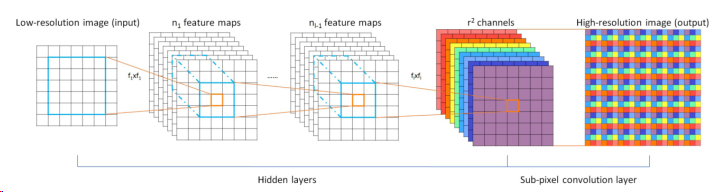
ESPCN的核心概念是亚像素卷积层(sub-pixel convolutional layer)。如上图所示,网络的输入是原始低分辨率图像,通过两个卷积层以后,得到的特征图像大小与输入图像一样,但是特征通道为r^2 (r是图像的目标放大倍数)。将每个像素的r^2 个通道重新排列成一个r x r的区域,对应于高分辨率图像中的一个r x r大小的子块,从而大小为r^2 x H x W的特征图像被重新排列成1 x rH x rW大小的高分辨率图像。这个变换虽然被称作sub-pixel convolution, 但实际上并没有卷积操作。
4、VESPCN
Real-Time Video Super-Resolution with Spatio-Temporal Networks and Motion Compensation(arxiv 2016)
上述几种方法都只在单幅图像上进行处理,而VESPCN提出使用视频中的时间序列图像进行高分辨率重建,并且能达到实时处理的效率要求。
5、SRGAN
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network(arxiv, 21 Nov, 2016)
本文将生成式对抗网络(GAN)用于SR问题。其出发点是传统的方法一般处理的是较小的放大倍数,当图像的放大倍数在4以上时,很容易使得到的结果显得过于平滑,而缺少一些细节上的真实感。因此SRGAN使用GAN来生成图像中的细节。
github(tensorflow): https://github.com/zsdonghao/SRGAN
github(tensorflow): https://github.com/buriburisuri/SRGAN
github(torch): https://github.com/junhocho/SRGAN
github(caffe): https://github.com/ShenghaiRong/caffe_srgan
github(tensorflow): https://github.com/brade31919/SRGAN-tensorflow
github(keras): https://github.com/titu1994/Super-Resolution-using-Generative-Adversaria...
github(pytorch): ai-tor/PyTorch-SRGAN
6、EDSR
Enhanced Deep Residual Networks for Single Image Super-Resolution, CVPRW2017
EDSR是NTIRE2017超分辨率挑战赛上获得冠军的方案。如论文中所说,EDSR最有意义的模型性能提升是去除掉了SRResNet多余的模块,从而可以扩大模型的尺寸来提升结果质量。
github(torch): https://github.com/LimBee/NTIRE2017
github(tensorflow): https://github.com/jmiller656/EDSR-Tensorflow
github(pytorch): https://github.com/thstkdgus35/EDSR-PyTorch
EDSR的网络结构如下:
标准化输入head:卷积×1
body:resblock(卷积×2+relu)*16
tail:卷积×(n+1)
标准化输出
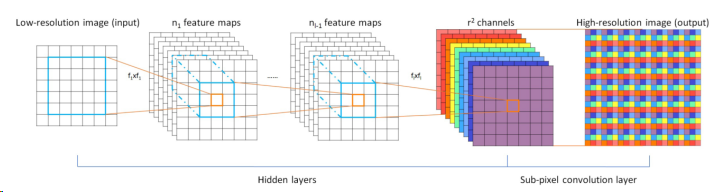
其上采样部分集成在tail的前n次卷积中,其中每次卷积将channels提升4倍,然后转化为放大2倍的feats(即将4个channels合并为一个长宽加倍的channel),重复log(n,2)次。借用ESPCN(上文有讲)的一张图示意一下这种方法,顺便一提,下面的WDSR上采样层也是用的这个原理:
EDSR去掉了ResBlock中的bn层,仅在resblock输出位置添加一个relu激活,源码如下,
class ResBlock(nn.Module):
def __init__(
self, conv, n_feats, kernel_size,
bias=True, bn=False, act=nn.ReLU(True), res_scale=1):
super(ResBlock, self).__init__()
m = []
for i in range(2):
m.append(conv(n_feats, n_feats, kernel_size, bias=bias))
if bn: # EDSR 的观点bn层对低抽象任务意义不大
m.append(nn.BatchNorm2d(n_feats))
if i == 0:
m.append(act) # conv->conv->relu
self.body = nn.Sequential(*m)
self.res_scale = res_scale
def forward(self, x):
res = self.body(x).mul(self.res_scale)
res += x
return res7、WDSR
Wide Activation for Efficient and Accurate Image Super-Resolution,CVPRW2018
建构于超分辨 EDSR 算法,亦即 NTIRE 2018 年的冠军模型,最主要的改进是在残差模块中 ReLU 激活函数前增大特征图。
github(pytorch):https://github.com/JiahuiYu/wdsr_ntire2018
一篇参考文章:https://blog.csdn.net/leviopku/article/details/85048846
WDSR_b网络结构如下:
标准化输入
head:卷积×1
body:block(卷积+relu+卷积×2)*16
tail:卷积×1
skip:卷积×1
标准化输出
tail部分仅有一次卷积,实际放大思路同EDSR,不过是一次卷积得到足够的channels(3*n^2),一步重建为3通道的图像。
其结构中有几个有意思的部分:
i. 其卷积层都外接了weight_norm层(w = g*v/||v||),据说可以一定程度缓解样本不均衡问题,并有防止过拟合的功能(可以看作一种正则化)。
ii. skip 结构实际上是一个单层卷积(channels变化为:3->3*n^2),从输入图片位置直接映射到tail的输出,其输出和tail输出尺寸完全一致,参照ResNet的方法合并,作为网络的输出
iii. 其Block对通常的ResBlock有修改,首先和EDSR的ResBlock结构就不一致(EDSR的ResBlock也和经典的有一定出入),其次其channels安排不是常规的沙漏结构(输入和输出channels一致且大于中间的channel,可能目的是假定中间层提取抽象特征),而是中间更大,为了获取更多的基础特征(作者认为对于超像素重建这种低抽象任务需要更多的底层信息来反映特征)。
class Block(nn.Module):
def __init__(
self, n_feats, kernel_size, wn, act=nn.ReLU(True), res_scale=1):
super(Block, self).__init__()
self.res_scale = res_scale
body = []
expand = 6
linear = 0.8
body.append(
wn(nn.Conv2d(n_feats, n_feats*expand, 1, padding=1//2))) # channels:64->64*6
body.append(act)
body.append( # channels:64*6->64*0.8
wn(nn.Conv2d(n_feats*expand, int(n_feats*linear), 1, padding=1//2)))
body.append( # channels:64*0.8->64
wn(nn.Conv2d(int(n_feats*linear), n_feats, kernel_size, padding=kernel_size//2)))
self.body = nn.Sequential(*body)
def forward(self, x):
res = self.body(x) * self.res_scale
res += x
return res8、DBPN
Deep Back-Projection Networks For Super-Resolution, CVPR2018
github(caffe): https://github.com/alterzero/DBPN-caffe
github(pytorch): https://github.com/alterzero/DBPN-Pytorch
二、Pytorch实现的EDSR/WDSR实验
github:https://github.com/Hellcatzm/EDSR-PyTorch
其实就是网上开源的 EDSR 和 WDSR 两个项目我合并了一下,有以下几点注意:
本项目 fork 自网上开源项目,以 EDSR 算法为基准,在原工程基础上添加了 WDSR 算法,并部分添加了注释,训练方法在 /src/demo.sh 下记录,注意不要去执行这个文件,该文件里面记录了工程的各种启动方式,选择想要执行的拷贝到命令行即可。
由于项目涉及大量的多进程操作,使得本工程在 windows 下不能正常执行,请在 Linux 下测试本工程。
如需使用 WDSR ,把命令行指令相应位置的 EDSR 改写为 WDSR_a 或者 WDSR_b 即可(不区分大小写)。
测试时我们首先在 EDSR 项目目录下新建 test 文件夹,存入低分辨率图片,然后在 src 目录下运行如下命令:
python main.py
--model 模型名称(不区分大小写)
--pre_train 已保存模型路径
--test_only
--save_results
--data_test Demo
生成的图片将保存在 experiment/results-Demo 文件夹下。
由于两个网络我们上面已经介绍了,对源码感兴趣的可以再 src 的 model 下浏览各个模型的核心实现,其代码由 model.__init__ 里的通用部分加 model.模型名称 里的各个模型的分支实现组成,由于 Pytorch 语法足够简洁且超分辨率重建网络并不复杂(最讨厌看目标检测的代码了,哈哈),所以不再长篇讲解源码了,我的项目里适当的给出了注释,这里贴个重建对比图,超分辨率重建效果都是有一点糊,好像油画一样,且细节不足,这项技术远远没有达到成熟。


本文转自:博客园 - 叠加态的猫,转载此文目的在于传递更多信息,版权归原作者所有。如不支持转载,请联系小编demi@eetrend.com删除。





