周昕 I 文
衣德良 I 技术审稿
HPC (High Performance Computing) 数据中心可为用户提供强大的计算能力,但服务器本身的高能耗,也成为将其大规模部署的主要障碍。传统的数据中心(例如,提供网页服务) ,一般执行用户提交的低计算度和时长短的任务,主要工作都由CPU完成。近年来随着GPU(Graphics Processing Unit) 、FPGA (Field-Programmable Gate Array) 和TPU (Tensor Processing Unit) 等并行计算硬件的蓬勃发展,HPC数据中心逐渐成为工业和学术界完成大规模计算任务(例如,地理和气候环境模拟、DNA匹配、机器学习算法训练) 的最佳选择。其中,GPU因具有很高的通用性和易用性,使用最为广泛。GPU内部高度的并行结构和丰富的外围电路部分,使得其能效和总能耗都远高于CPU。因此,在优化HPC数据中心能耗时,应把GPU作为一个核心部件来考虑。
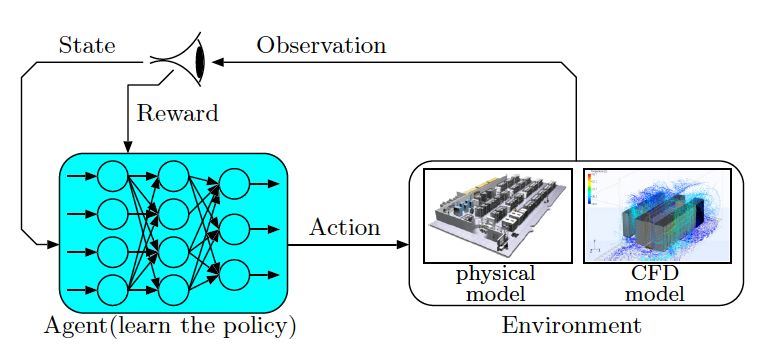
在之前的研究中,我们使用了深度强化学习算法来解决数据中心能耗优化的问题。如图1所示,在深度强化学习中,代理(agent)通过和真实环境(environment)交互,根据从环境得到的奖励(reward)和状态(state),反复探索动作(action)空间,找到全局最优的控制策略 (control policy) 。但在控制策略收敛之前,代理所生成的动作可能会对真实环境造成很多不可预测的严重后果(例如,系统崩溃、温度过高、硬件损坏) 。所以,在我们的解决方案中,使用了预测模型来代替真实环境,完成对代理神经网络的训练和验证,从而最大限度地减小实际应用中的风险。因此,建立GPU的相关能耗模型是我们提出的基于强化学习方法的关键。由于GPU包括了众多外围部件,结构比CPU要负责,客观上增加了对GPU功耗的模型建立的难度。

表1列举了一些GPU功耗模型建立的相关研究。表中的方法都通过收集GPU内部的Performance Counter(保存了GPU状态的内部寄存器) 的数据,来预测GPU的功耗。Ma[1] 使用linear regression算法来预测某一时间段内的GPU能耗。所得到的线性模型可以用公式1来表示,
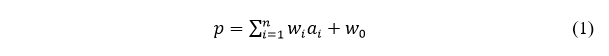
其中,表示从counter中观察到的数据,是训练时的权重。Nagasaka[2]扩展了Ma的方法,来预测一个GPU kernel的平均能耗。但是线性的模型存在一些缺陷,比如当执行非对称kernel时(例如,每个Streaming multiprocessor(SM)使用的core数不同),counter的数据会受到影响造成预测精度下降。此外,线性的模型忽略了实际环境中的非线性的部分,也会降低预测精度。相反的,Song[3]利用神经网络来建立了非线性的GPU功耗模型。如图2所示,Performance Counter的数据可以通过CUDA Profiling Tools Interface(CUPTI)读取,相应的能耗和温度数据则可通过Nvidia Management Library (NVML) interface来获得,这些数据最后用来训练神经网络预测GPU的能耗。
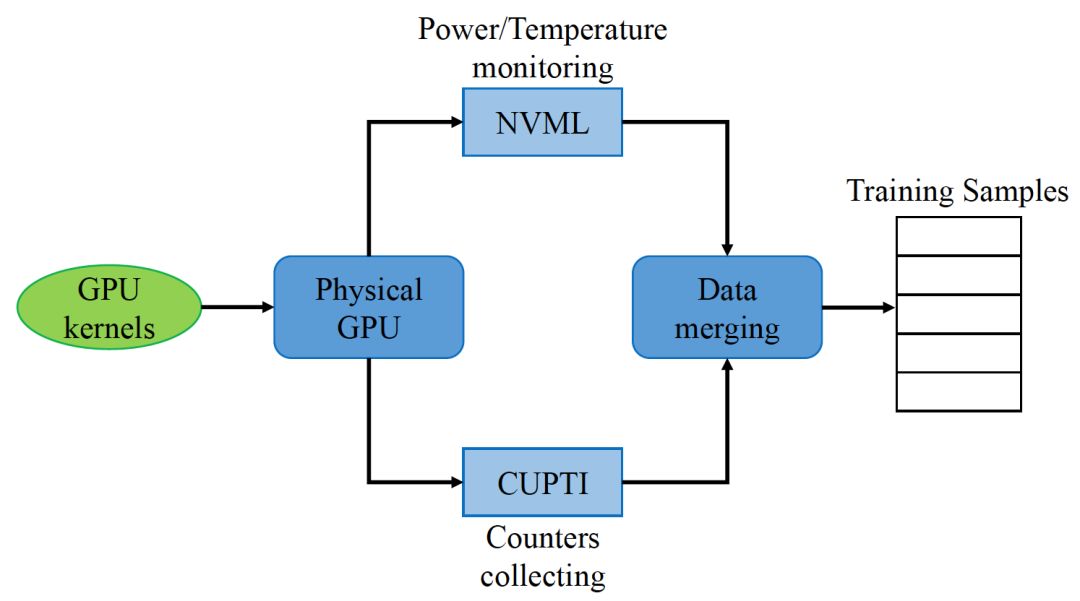
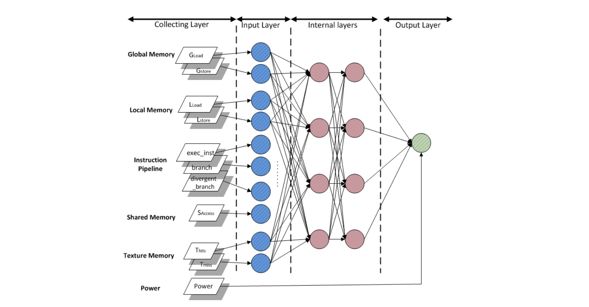
图3展示了以神经网络为基础的GPU能耗预测模型。输入特征大致被分为几部分,包括global memory的访问状态、local memory的访问状态、指令执行状态、shared memory的访问状态等。通过将相关系数高的多个特征合并,减少了输入特征的维度,降低了训练难度,使得该模型在相关研究中拥有最高的预测精度(2.1%的GPU能耗预测平均绝对误差)。
基于Performance Counter的预测模型拥有较高的预测精度,但同时也有它本身的局限性。其中,最重要的是此类模型需要从执行用户程序的GPU中在线读取状态数据,依赖于GPU硬件,不适合基于强化学习的数据中心优化算法的训练。这里就要提到另一种GPU能耗预测模型-GPU simulator。该类型的模型一般可以直接执行用户的程序,通过软件模拟的方法,输出GPU的状态信息和计算结果,摆脱了对GPU硬件的依赖。Chen[4] 就是利用了GPGPU-Sim来模拟物理GPU硬件,通过random forest的方法建立了预测模型。除GPGPU-Sim外,还有其他一些GPU simulator如表2所示。
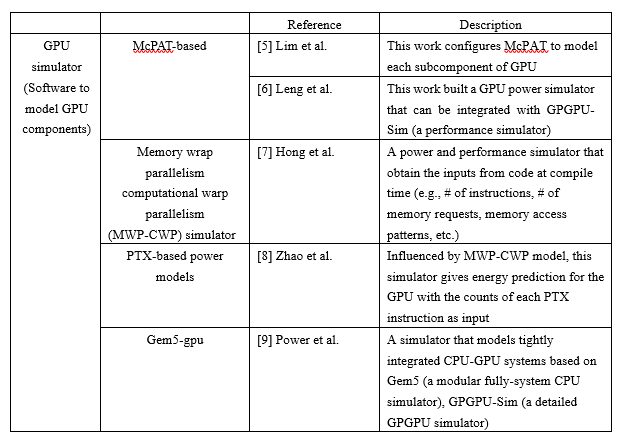
通常这些simulator本身程序复杂,模拟时间长,较难应用在基于强化学习的数据中心优化的训练。此外,基于Performance Counter的预测模型都是将low-level的特征(与用户程序本身结构相关性高,例如,shared memory的bank conflict的发生频率、global memory的访问次数等)作为输入,造成从用户任务到特征的映射过程复杂,模型建立困难。因此,接下来我们的工作是尝试将用户任务映射到high-level特征(例如,温度、风扇转速、当前能耗等)作为输入,并且建立轻量级的GPU simulator以适应我们基于强化学习的数据中心优化算法的训练。
参考文献
[1] Ma et al., “Statistical power consumption analysis and modeling for GPU-based computing,” ACM SOSP, 2009.
[2] Nagasaka et al., “Statistical power modeling of GPU kernels using performance counters,” IEEE International Green Computing Conference, 2010.
[3] Song et al., “A simplified and accurate model of power-performance efficiency on emergent GPU architectures,” IEEE IPDPS, 2013.
[4] Chen et al., “Statistical GPU power analysis using tree-based methods,” IEEE International Green Computing Conference, 2011.
[5] Lim et al., “Power modeling for GPU architecture using McPAT,” ACM Trans on Design Automation of Electronic Systems, 2013.
[6] Leng et al., “GPUwattch: Enabling energy optimizations in GPGPUs,” ACM ISCA, 2013.
[7] Hong et al., “An integrated GPU power and performance model”, ACM SIGARCH, Vol. 38, pp. 280-289, 2010.
[8] Zhao et al., “POIGEM: A programming oriented instruction level GPU energy model for CUDA program,” Springer Algorithms and Architectures for Parallel Processing, 2013.
[9] Power et al., “Gem5-gpu: A heterogeneous CPU-GPU Simulator,” IEEE Computer Architecture Letters, 2015.
本文转自:南洋理工CAP组,作者:周昕,转载此文目的在于传递更多信息,版权归原作者所有。如不支持转载,请联系小编demi@eetrend.com删除。





