本文将教你如何避免机器学习和数据科学中新手常犯的 6 个错误,创建杀手级的数据集。
不知道你有没有听说过下面这句话,如果没听过,那现在我们嘱咐你牢记这句机器学习界的箴言:你的数据质量怎样,模型性能就怎样。
很多人会犯一个错误:从不改善他们那“不忍直视”的数据集,反而只顾闷头优化模型。这就好比你整天只用很便宜的汽油,搞得车子经常出毛病,结果你的解决方法却是砸锅卖铁买了辆超跑。最合理的解决方案应当是先换成质量好的汽油,而不是想着先把汽车升级。下面就以图像分类任务为例,教你怎样通过提高数据集质量很容易的优化模型结果,当然这些方法适用于所有类型的数据集。
六个常见的错误及避免方法
1. 没有为模型准备足够的数据
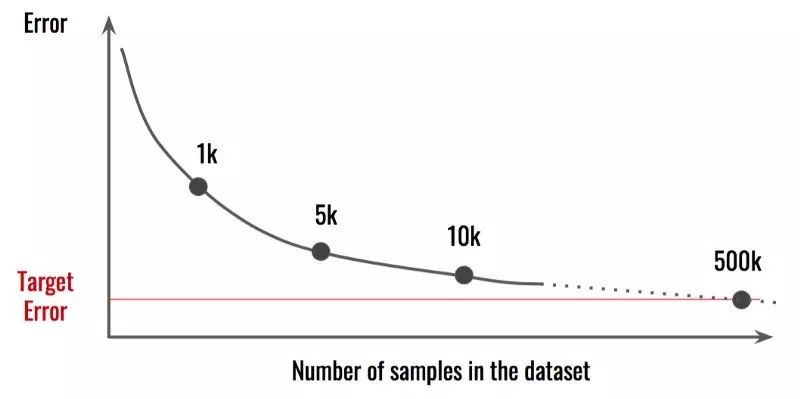
如果你的数据集很小,模型就无法获得足够的用于泛化的辨别特征。这样模型就会过拟合数据,造成训练错误很低但测试错误很高的问题。
解决方法1:获取更多数据。可以从当前数据集的来源处收集更多数据,或另找具有相似特征的数据集。
提醒:通常这并不是件容易的事情,需要投入很多时间和资源。而且,你或许也想知道需要再获取多少数据。可以将你的结果和不同数据集大小做个比较,然后试着推断。
比如上面这个例子中,似乎我们需要 50 万个样本才能达到目标误差值。这意味着我们需要收集比当前数据多出 50 倍的数据。处理数据或模型的其它方面获取更为有效。
解决方法2:数据增强。比如通过为同一图像创建多种副本,产生多个变体。这种方法能让我们以很低的成本获得大量的额外图像,且效果很好。常见的图像增强方法有旋转、平移、裁切、高斯模糊、缩放、变换颜色等。不过你需要确保数据仍然表示相同的类。

提醒:尝试完所有的增强方法可能仍然无法解决你的问题。例如,假如你想分类柠檬和酸橙,就别尝试颜色增强了,因为这会让模型认为颜色对于分类来说非常重要。这反而会让模型更难发现可以辨别的特征。

2. 数据类的质量很低
这个错误很容易犯,如果可能,一定要花时间遍历你的数据集,检查每个数据样本的标签。这可能会花一些时间,但如果数据集中存在反例,会对模型的学习过程产生不利影响。
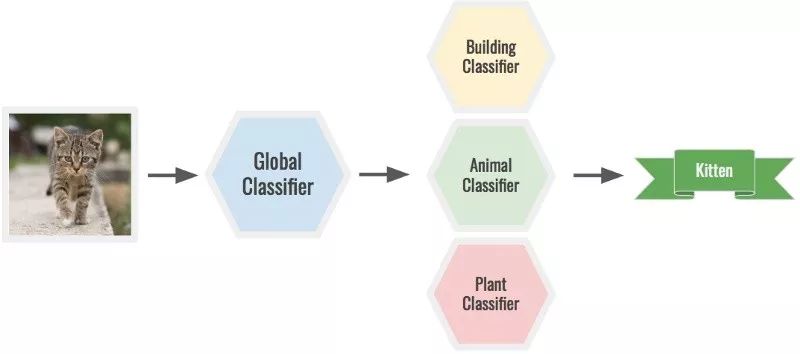
同样,应当为你的数据类选择正确的粒度级别。根据实际问题,你可能需要更多或更少的类。例如,你可以用一个全局分类器为一张猫咪的图像分类,确定它是不是动物,然后再将图像通过一个动物分类器来确定它是不是猫咪。较大的模型可以同时处理这两种任务,但会比较困难。
3. 数据的质量很低
如开头所说,低质量的数据只会带来低质量的模型。
你的数据集中可能存在离你的使用目标相去甚远的数据样本,而这些数据相比起到的作用而言,往往会让模型更容易产生困惑。
解决方法:去除质量最差的图像。这个过程会比较漫长,但是很值得,能够优化你的模型结果。

另一个常见问题是,你的数据集中存在一些和实际应用并不匹配的数据。例如,有些图像来自完全不同的数据源。
解决方法:想想模型的长远应用,从这个角度考虑去获取更贴合实际应用的数据。如果有时间,试着找找其它同类模型或工具使用的数据集。
4. 数据类不均衡
如果每个类的样本数量相对于所有的类来说不一样,那么模型可能会倾向于“青睐”占主导地位的类,因为这样它会产生更低的错误。我们常说的模型有偏差,就是因为数据的类分布不均衡。这是个比较严重的问题,需要你检查模型的精确度、召回率或混合矩阵。
解决方法1:为未被充分表示的类获取更多数据样本。不过,通常会花费一定的时间和资源。
解决方法2:对数据过采样或降采样。这意味着你需要从被过度表示的类中移除一些数据样本,在未被充分表示的类中复制样本。后者可以采取我们上面讲过的数据增强方法。
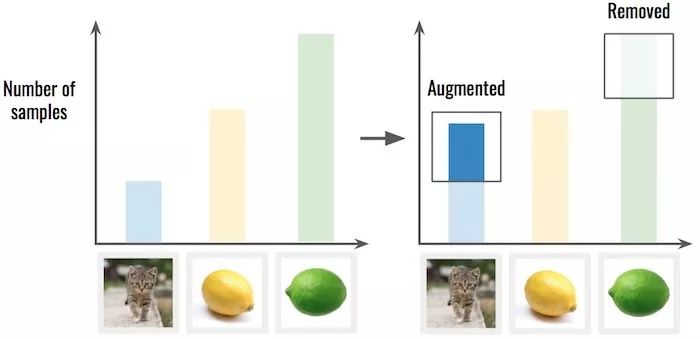
如上图,我们需要增强未被充分表示的类(猫咪),从被过度表示的类(酸橙)中去除部分样本。这样才能让类分布更平滑更均衡。
5. 数据不均衡
如果你的数据没有特定的格式,或数据值不处于一定范围内,那么你的模型可能就无法很好的处理数据。如果图像长宽比和像素值都分布均衡的话,模型会有更好的性能。
解决方法1:裁切或拉伸数据,这样就能有一致的长宽,这样数据样本就能有相同的长宽或格式。

解决方法2:将数据标准化,这样每个样本的数据值都在相同范围内。
6. 没有验证或测试
等清洗、增强和正确标记数据集之后,你还需要对数据集进行分割。很多人是按照下面方法分割的:80%的数据用于训练,20%的数据用于测试,这样能让你比较容易的发现过拟合问题。然而,如果你用同一测试集测试多个模型,有时会出现意外情况。选择测试准确率最高的模型,其实意味着在过拟合测试集。出现这种问题是因为你在选择一个模型时并非出于它的内在价值,而是它在具体数据集上的表现。
解决方法:将数据集分割为3部分:训练集(60%)、验证集(20%)和测试集(20%)。这样能防止测试集被模型的选择过拟合。应当选择如下过程:
◆ 用训练集训练模型;
◆ 在验证集上测试模型,确保没有出现过拟合;
◆ 选择表现最好的模型,用测试集对其测试,得到模型的真正准确率。

注意:选好部署的模型后,不要忘了用整个数据集去训练它!数据越多越好!
结语
本文我们谈论了机器学习入门者训练模型时,容易在数据集上出现的一些错误,对于如何避免这些坑,也提供了相应的方法和思路。总之,记住:“机器学习任务中的赢家可能没有最好的模型,但一定有最好的数据集”。
本文转自: DataCastle数据城堡,转载此文目的在于传递更多信息,版权归原作者所有。如不支持转载,请联系小编demi@eetrend.com删除。





