作者:Chu-Tak Li
编译:ronghuaiyang
导读
在网络结构中使用多种感受野,并对损失函数进行了改进。
今天我们要讲的另一种修复论文叫做Image inpainting via Generative Multi-column CNNs (GMCNN)。本文使用的网络架构类似于我们之前介绍的那些论文。本文的主要贡献是对损失函数进行了若干修正。
回顾
正如我在以前的文章中提到的,如何利用图像中其他像素所提供的信息,对提高图像修复效果至关重要。图像修复的一个非常直观的意义是直接复制图像本身中找到的最相似的图像patch,并粘贴在缺失的区域。有趣的是,我们应该意识到,在实践中,对于缺失的区域没有“正确”的答案。在现实中,给定一个损坏的/mask的图像,你不可能知道原始图像(ground truth)来进行比较。所以,我们有这么多的答案来解决缺失的区域。
介绍和动机
从以往的图像修复论文中,我们了解到感受野野对图像修复的重要性。对于3×3内核,我们可以调整膨胀率来控制它的感受野。如果扩张率为1,我们的感受野为3×3。如果膨胀率是2,通过跳过一个相邻像素,我们有一个5×5感受野,以此类推。这里,如果我们使用带有膨胀卷积的3×3、5×5和7×7内核会怎么样?这在本文中被定义为一个多列结构
在之前的文章中,寻找和缺失区域最相似的图像patch的过程是嵌入到生成网络中的,在这个工作中,该过程只是用来设计一个新的损失项用于训练。
由于缺少的区域没有“正确”的答案,像素级重建精度损失项(即L1损失)似乎不适用于图像修复。作者提出了基于缺失像素的空间位置,对L1损失项进行加权。靠近有效像素的空间位置对于L1的损失应该有更高的权值,因为它们对重构有更合理的参考,反之亦然。
方案和贡献

在我看来,本文遵循了我们之前提到的图像修复的趋势。首先,作者采用了扩展卷积的多分支CNN,而不是单一分支。三个不同的kernel大小被用于三个不同的分支,以实现不同的感受野和提取不同分辨率的特征。
其次,引入两个新的损失项来训练网络,分别是置信度驱动的重建损失和隐多样化马尔可夫随机场(ID-MRF)损失。置信度驱动的重建损失是一个加权的L1损失,而ID-MRF损失与预训练的VGG网络计算的特征patch比较有关。
图1显示了本文方法的一些修复结果。你可以放大以更好地查看这些高质量的结果。
方法
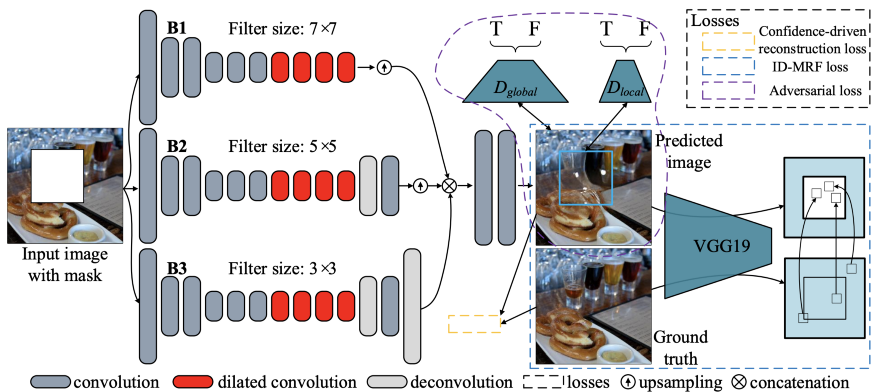
图2显示了本文提出的生成式多列卷积神经网络(GMCNN)的网络结构。如你所见,有一个多列生成器网络、两个鉴别器(全局和局部)和一个用于计算ID-MRF损失的预训练VGG19。
生成网络中有三列,每一列使用三种不同大小的过滤器,即3×3、5×5和7×7。、注意,这三列的输出被连接到其他两个卷积层以获得完整的图像。
ID-MRF正则化

简单地说,对于MRF目标,我们希望最小化生成的特征与通过预先训练的网络计算出的ground truth中的最近邻居特征之间的差异。在大多数以前的工作,余弦相似性测量被用来寻找最近的邻居。然而,这种相似性度量通常对不同生成的特征块给出相同的最近邻,导致修复结果模糊,如图3(a)所示。
为了避免使用余弦相似度度量可能导致完成图像模糊,我们采用了相对距离度量,修复结果如图3(b)所示。你可以看到,完成的图像有更好的局部精细纹理。
我们来谈谈它们是如何进行相对距离测量的。Y(hat)_g为缺失区域生成的内容,Y(hat)^L_g 和 Y^L 为预训练网络的第L层特征。对分别从Y(hat)^L_g 和 Y^L中提取的v和s特征块,计算v与s的相对相似度:
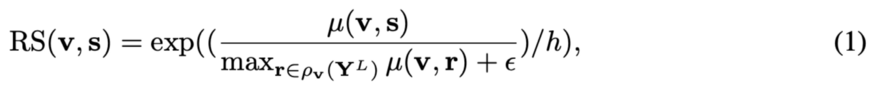
mu(. , .)是余弦相似度。r属于Y^L, v除外。h和 epsilon是正的常数。显然,如果v比其他特性patch更类似于s,那么RS(v, s)就会很大。你也可以考虑,如果v有两个类似的patchs和r,那么RS(v, s)就会很小。我们鼓励在缺失区域之外寻找类似的patches。
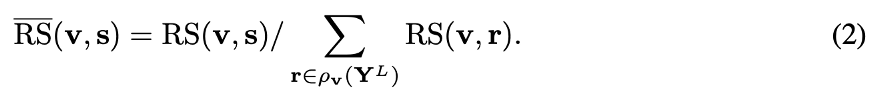
最后,计算了在Y(hat)^L_g 和 Y^L 之间的ID-MRF损耗。
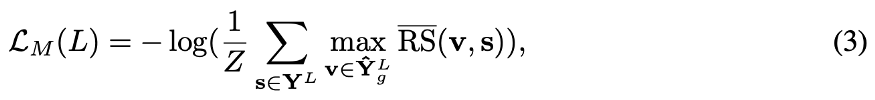
其中参数max RS(bar)(v, s)表示s是v最近的邻居,Z是一个归一化因子。如果考虑所有生成的特征patch都接近于某一特征patch s的极端情况,则max RS(bar) (v, r)较小,因此ID-MRF损失较大。
另一方面,如果Y^L 中的每个r都有自己的最近邻居Y(hat)^L_g,则max RS(bar) (v, r)很大,因而ID-MRF损失较小。这里,主要思想是强制/引导生成的特征patch有不同的最近邻居,从而生成的feature具有更好的局部纹理。
与先前的工作一样,作者使用预先训练的VGG19来计算ID-MRF损失。请注意,中间层conv3_2和conv4_2分别表示结构特征和语义特征。
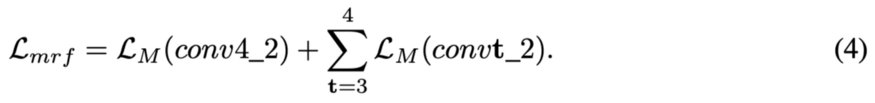
作者声称这种损失与最近邻搜索有关,并且只在训练阶段使用。这与在测试阶段搜索最近邻居的方法不同。
特征不变重建损失
所提出的空间变异重构损失实际上是一个加权的L1损失。确定权值的方法有很多种,本文利用高斯滤波器对掩模进行卷积,生成加权掩模,计算加权L1损耗。加权L1损失的主要思想是,接近有效像素的像素损失比远离有效像素的像素损失受到更高的约束。因此,位于缺失区域中心的像素损失应该有更低的L1损失权值(即更少的约束)。
对抗损失
与先前的工作类似,作者采用了改进的WGAN损失和局部和全局鉴别器。
最终的损失函数
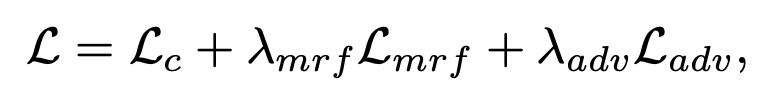
这是用于训练所提模型的最终的损失函数。与大多数修复论文相似,加权L1损失(第一损失项)的重要性为1。Lambda_mrf和Lambda_adv是控制局部纹理mrf正则化和对抗训练重要性的参数。
实验
作者在5个公共数据集上评估了他们的方法,即Paris StreetView, Places2, ImageNet, CelebA和CelebA- hq数据集。在他们的训练期间,所有的图像都被调整为256×256,最大的中心孔的大小128×128。在GPU上测试256×256和512×512大小的图像,每个图像大约需要49.37 ms和146.11 ms。

图4显示了Paris StreetView和ImageNet数据集的定性比较。请放大以更清楚地看到修复结果。很明显,本文提出的方法GMCNN给出了具有最佳视觉质量的修复结果。

正如我在之前的文章和本文开头提到的,PSNR与像素级重建精度有关,这可能不适用于评估图像修复。研究人员仍然报告PSNR和SSIM供读者参考,因为这些数值指标是所有图像处理任务的基础。如表1所示,本文提出的方法在五个数据集上获得了相当甚至更好的PSNR和SSIM。
消融研究


对不同网络结构在图像修复中的性能进行了评价。在他们的实验中,对于从粗到细的结构,没有使用上下文注意力。对于三个分支中感受野固定的GMCNN,采用大小为5×5的过滤器。对于具有不同感受野的GMCNN,三个分支分别使用了3×3、5×5和7×7的kernel。定量和定性结果分别见表2和图5。显然,具有不同感受野的GMCNN提供了最好的修复效果。
除了网络结构的选择和多重感受野的使用,作者还研究了两个提出的损失项的有效性,即信心驱动重建损失和ID-MRF损失。

图6显示了不同重建损失的视觉对比,即空间折现损失和提出的置信度驱动重建损失。请注意,空间折现损失根据像素的空间位置获得权重掩码,而提出的置信驱动重建损失通过将掩码图像与高斯滤波器进行多次卷积获得权重掩码。两位作者声称,由置信度驱动的重建损失效果更好。从我自己的经验来看,这两种重建损失是相似的。也许你可以试一试。



更重要的是,ID-MRF损失项是本文最强调的。因此,作者表明了这一失项的重要性,定量结果列在表3中。图7显示了使用ID-MRF损失和不使用ID-MRF损失训练的模型之间的区别。我们可以看到,使用ID-MRF可以增强生成像素的局部细节。此外,图8显示了使用不同的lambda_mrf来控制ID-MRF损失的重要性的效果。你可以放大以便更好地查看结果。我个人认为,修复的结果是相似的。从表3可以看出,lambda_mrf = 0.02提供了PSNR和视觉质量之间的良好平衡。
总结
综上所述,本文的创新之处在于使用ID-MRF损失项来进一步增强生成内容的局部细节。这种损失的主要思想是引导生成的特征patch在缺失区域之外寻找最近的邻居作为参考,并且最近的邻居应该是多样化的,这样可以模拟更多的局部细节。
多重感受野(多列或多分支)的使用是由于感受野的大小对图像修复任务很重要。由于局部相邻像素缺失,我们必须借用遥远空间位置的信息来填补缺失的像素。如果你看过我之前的文章,我想这个想法对你来说并不难理解。
使用加权L1损失也是由于缺少区域没有“正确”答案的事实。对于那些更接近缺失区域边界的缺失像素,它们相对受到接近有效像素的约束,因此需要对L1的损失赋予更高的权值。另一方面,对于位于缺失区域中心的缺失像素,它们的L1约束应该更小。
要点
参考我在上面的结论,我希望你能理解提出的ID-MRF损失的意义,因为这是本文的核心思想。对于本文的其他两个思路,即多列结构和加权L1损失。事实上,如果你关注过我之前的文章,我认为你可以很好地理解背后的原因。我认为多重/多种感受野的概念是深层语义修复的常见做法。
对于加权的L1损失,从我个人的经验来看,我不认为它会对修复性能带来明显的改善。当然,实现加权L1损失的方法有很多。如果你对此感兴趣,可以试一试。
英文原文:https://towardsdatascience.com/what-if-multiple-receptive-fields-are-used-for-image-inpainting-ea44003ea7e9
本文转自:AI公园,作者:Chu-Tak Li,编译:ronghuaiyang,转载此文目的在于传递更多信息,版权归原作者所有。





