作者:谈谈音频开发
深度学习神经网络模型中的量化是指浮点数用定点数来表示,也就是在DSP技术中常说的Q格式。作者在以前的文章(Android手机上Audio DSP频率低 memory小的应对措施 )中简单讲过Q格式,网上也有很多讲Q格式的,这里就不细讲了。神经网络模型在训练时都是浮点运算的,得到的模型参数也是浮点的。通常模型参数较多,在inference时也有非常多的乘累加运算。如果处理器的算力有限,在inference时用浮点运算将导致CPU load很高,极大影响性能。而且通常一个参数用浮点数表示占四个字节,而如果用8比特量化的话,一个参数只占一个字节,memory得到了极大的节约,在memory紧张的处理器上尤为重要。所以通常都要对神经网络模型进行量化,来降低CPU load和节省memory。由于特征数据(比如智能语音中的MFCC数据)在送入模型前基本都做了归一化处理,值都压缩到了【-1,1】的范围内,所以现在主流的都是用8比特来量化。
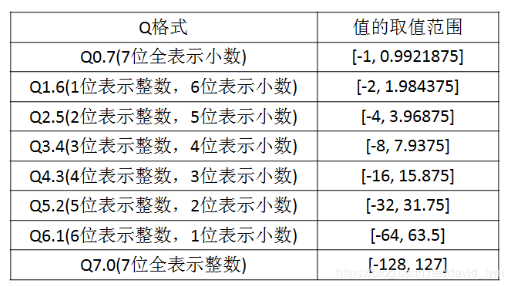
下表是用8比特来量化的各种Q格式的值的取值范围。
模型的量化可分为训练中量化和训练后量化,还可分为对称量化和非对称量化。我们用的是训练后对称量化,即先训练好用浮点表示的模型参数等,然后再去量化,量化某类值(比如weight)时看其绝对值的最大值,从而可以知道用什么定标的Q格式最合适。
我们目前用的是主流的8比特量化方式。模型的量化主要包括两方面的内容:各层参数的量化和各层输出的量化。
先看各层输出的量化。在评估时把测试集中各个文件每层的输出保存下来,然后看每层输出值的绝对值的最大值,比如绝对值最大值为3.6,可以从上面的8比特量化表看出用Q2.5 量化最为合适(也可以用公式 np.ceil(np.log2(max))算出整数的表示位数,然后确定小数的表示位数,从而确定定标)。
再来看各层参数的量化。参数主要包括weight和bias,这两种参数要分别量化,量化方法同上面的每层输出的量化方法一样,这里不再赘述。需要注意的是如果当前层是卷积层或者全连接层,为了减少运算量,一般部署模型时都会将BatchNormal(BN)层参数融合到卷积层或者全连接层(只有当卷积层或者全连接层后面紧跟BN层时才可以融合参数,否则不可以)。
具体怎么融合如下:假设层的输入为X,不管是卷积层还是全连接层,运算均可以写成 WX + b (W为权重weight, b为bias),BN层执行了两个操作,一个是归一化,另一个是缩放,两个阶段的操作分别为:

将上面三个式子合并(卷积层或者全连接层的输出就是BN层的输入, 原卷积层或者全连接层的参数为 Wold 和 bold ),可以得到:
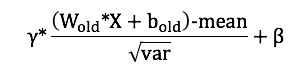
上式等于 Wnew * X + bnew,展开得到:
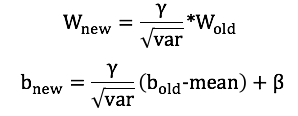
这样合并后的运算就成了:
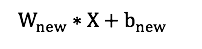
在卷积层或者全连接层里用上面得到的新参数(Wnew和bnew)替代旧参数(Wold 和 bold),inference时BN层就消失啦。
卷积层或全连接层中,主要是乘累加运算,通常格式是output = ∑ input*weight + bias。这里input是当前层的输入(即是上一层的输出),weight是当前层的权值,bias是当前层的偏置,output是当前层的输出。这四个值均已定标,在运算过程中要想得到正确的结果,需要做移位处理。怎么移位呢?下面举例说明。
假设input定标为Q5.2 ,weight定标为Q1.6 ,bias定标为Q4.3 ,output定标为Q2.5 。
假定只有一个input和一个weight,input浮点值是28.4,用Q5.2 表示就是01110010 (28.4 * 22= 113.6,四舍五入就是114),weight浮点值是1.6,用Q1.6 表示就是01100110,bias为12.8,用Q4.3 表示就是01100110。Input * weight = 01110010 * 01100110 = 0010 1101 0110 1100 = 11628(十进制表示)。八位数乘以八位数超出了8位数的表示范围,要用16位表示。28.4 * 1.6 = 45.44,要让11628表示45.44,所以11628用Q7.8 表示(11628 / 45.44 约为256 = 28)。
从上面计算看出,两个八位数相乘是16位数,16位数的定标小数位数是两个8位数的定标小数位数相加。这里Q7.8 中的8是Q5.2 中的2加上Q1.6 中的6。定标小数位数知道了,整数位数就是(15 - 小数位数),这里小数位数是8,整数位数就是7(7 = 15 - 8)。不同定标的数也不能直接相加,所以要把bias的Q4.3 表示的值转换成Q7.8 表示的值。Bias原始为12.8,用Q4.3 表示就是12.8 * 23,用Q7.8 表示就是12.8 * 28。可以看出bias从Q4.3 转变为Q7.8 ,只要乘以25即可,即左移5位。
再来看上面的式子output = ∑input*weight + bias,等式右边经过计算后变成了Q7.8 ,而等式左边是根据非常多的样本算出来的层的输出的绝对值的最大值得到的定标Q2.5 ,所以最后要把Q7.8 格式转换成Q2.5格式 。对于一个浮点数,假设为a,用Q7.8 表示就是a *28 , 用Q2.5 表示就是a * 25 ,可以看出要把Q7.8 格式转换成Q2.5格式 ,只需右移3位(3 = 8 - 5)即可。
所以每一层计算过程中移位的处理如下:假定input定标为_{_{}}_{}Qa.b,weight定标为Qc.d,bias定标为Qe.f,output定标为Qm.n。这些值均为8比特表示,即a+b=7,c+d=7,e+f=7,m+n=7。input * weight 为16比特Qu.v表示,其中v=b+d,u = 15 - v。计算过程中要把bias从8位表示变成16位表示,若f<v,bias则要左移(v-f)位,若f>v,bias则要右移(f-v)位,若f=v,则不移位。处理后∑input*weight + bias是一个16位表示的数,而output是一个8位表示的数,还要把16位表示的数转换成8位表示的数。若n<v,16位表示的数则要右移(v-n)位,若n>v,16位表示的数则要左移(n-v)位,若n=v,则不移位。
按照上面的方法,各层的模型参数以及输出都量化好了。量化好后还要对量化进行评估,评估的指标是余弦相似度和欧几里得距离等。余弦相似度是用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小的度量。余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似。公式如下:
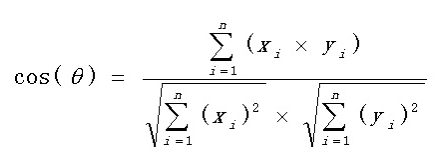
欧几里得距离,又称欧氏距离,是最常见的距离度量,衡量的是多维空间中两个向量之间的绝对距离。欧氏距离越小,相似度越大;欧氏距离越大,相似度越小。公式如下:
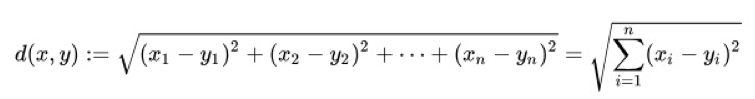
评估时要一层一层的评估,用余弦相似度和欧几里得距离等比较每层的量化前浮点的输出的向量和量化后的定点的输出向量(定点的输出向量算好后要根据定标转成浮点数才能比较)。余弦相似度要接近1和欧几里得距离要接近0,才是一个合格的量化。否则要找出量化中的问题,直到指标达标。
本文转自:博客园 - 谈谈音频开发,转载此文目的在于传递更多信息,版权归原作者所有。





