译:张大倩 | 编:丛末
来源:AI科技评论
长短期记忆网络(LSTM),作为一种改进之后的循环神经网络,不仅能够解决 RNN无法处理长距离的依赖的问题,还能够解决神经网络中常见的梯度爆炸或梯度消失等问题,在处理序列数据方面非常有效。
有效背后的根本原因有哪些?本文结合简单的案例,带大家了解关于 LSTM 的五个秘密,也解释了 LSTM如此有效的关键所在。
秘密1:发明LSTM是因为RNN 发生严重的内存泄漏
之前,我们介绍了递归神经网络(RNN),并演示了如何将它们用于情感分析。
RNN 的问题是远程内存。例如,它们能够预测出“the clouds are in the…”这句话的下一个单词“sky”,但却无法预测出下面这句话中缺失的单词:“她在法国长大。现在到中国才几个月。她说一口流利的 …”(“She grew up in France. Now she has been in China for few months only. She speaks fluent …”)
随着间隔的拉长,RNN变得无法学会信息连接。在此示例中,最近的信息表明,下一个词可能是一种语言的名称,但是如果我们想缩小哪种语言的范围,那么就需要到间隔很长的前文中去找“法国”。在自然语言文本中,这种问题,完全有可能在相关信息和需要该信息的地方出现很大的差异。这种差异在德语中也很常见。

为什么RNN在长序列文本方面存在巨大的问题?根据设计,RNN 在每个时间步长上都会接受两个输入:一个输入向量(例如,输入句子中的一个词)和一个隐藏状态(例如,以前词中的记忆表示)。
RNN下一个时间步长采用第二个输入向量和第一隐藏状态来创建该时间步长的输出。因此,为了捕获长序列中的语义,我们需要在多个时间步长上运行RNN,将展开的RNN变成一个非常深的网络。
阅读参考:
https://towardsdatascience.com/recurrent-neural-networks-explained-ffb9f94c5e09
长序列并不是RNN的唯一麻烦制造者。就像任何非常深的神经网络一样,RNN也存在梯度消失和爆炸的问题,因此需要花费大量时间进行训练。人们已经提出了许多技术来缓解此问题,但还无法完全消除该问题,这些技术包括:
- 仔细地初始化参数
- 使用非饱和激活函数,如ReLU
- 应用批量归一化、梯度消失、舍弃网络细胞等方法
- 使用经过时间截断的反向传播
这些方法仍然有其局限性。此外,除了训练时间长之外,长期运行的RNN还面临另一个问题是:对首个输入的记忆会逐渐消失。
一段时间后,RNN的状态库中几乎没有首个输入的任何痕迹。例如,如果我们想对以“我喜欢这款产品”开头的长评论进行情感分析,但其余评论列出了许多可能使该产品变得更好的因素,那么 RNN 将逐渐忘记首个评论中传递的正面情绪,并且会完全误认为该评论是负面的。
为了解决RNN的这些问题,研究者已经在研究中引入了各类具有长期记忆的细胞。实际上,不再使用基本的RNN的大多数工作是通过所谓的长短期记忆网络(LSTM)完成的。LSTM是由S. Hochreiter和J. Schmidhuber发明的。
秘密2 :LSTM的一个关键思想是“门”
每个LSTM细胞都控制着要记住的内容、要忘记的内容以及如何使用门来更新存储器。这样,LSTM网络解决了梯度爆炸或梯度消失的问题,以及前面提到的所有其他问题!
LSTM细胞的架构如下图所示:
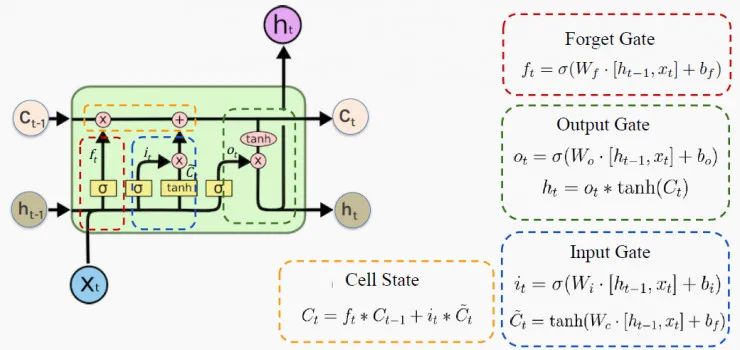
h 是隐藏状态,表示的是短期记忆;C是细胞状态,表示的是长期记忆;x表示输入。
门只能执行很少的矩阵转换,激活 sigmoid函数和tanh函数可以神奇地解决所有RNN问题。
在下一节中,我们将通过观察这些细胞如何遗忘、记忆和更新其内存来深入研究这一过程。
一个有趣的故事:
让我们设置一个有趣的情节来探索这个图表。假设你是老板,你的员工要求加薪。你会同意吗?这取决于多个因素,比如你当时的心情。
下面我们将你的大脑视为LSTM细胞,当然我们无意冒犯你聪明的大脑。

你的长期状态C将影响你的决定。平均来说,你有70%的时间心情很好,而你还剩下30%的预算。因此你的细胞状态是C=[0.7, 0.3]。
最近,所有的事情对你来说都很顺利,100%地提升了你的好心情,而你有100%的可能性预留可操作的预算。这就把你的隐藏状态变成了h=[1,1]。
今天,发生了三件事:你的孩子在学校考试中取得了好成绩,尽管你的老板对你的评价很差,但是你发现你仍然有足够的时间来完成工作。因此,今天的输入是x=[1, - 1,1]。
基于这个评估,你会给你的员工加薪吗?
秘密3:LSTM通过使用“忘记门”来忘记
在上述情况下,你的第一步可能是弄清楚今天发生的事情(输入x)和最近发生的事情(隐藏状态h),二者会影响你对情况的长期判断(细胞状态C)。“忘记门”( Forget Gate)控制着过去存储的内存量。
在收到员工加薪的请求后,你的“忘记门”会运行以下f_t的计算,其值最终会影响你的长期记忆。
下图中显示的权重是为了便于说明目的的随意选择。它们的值通常是在网络训练期间计算的。结果[0,0]表示要抹去(完全忘记)你的长期记忆,不要让它影响你今天的决定。

秘密4:LSTM 记得使用“输入门”
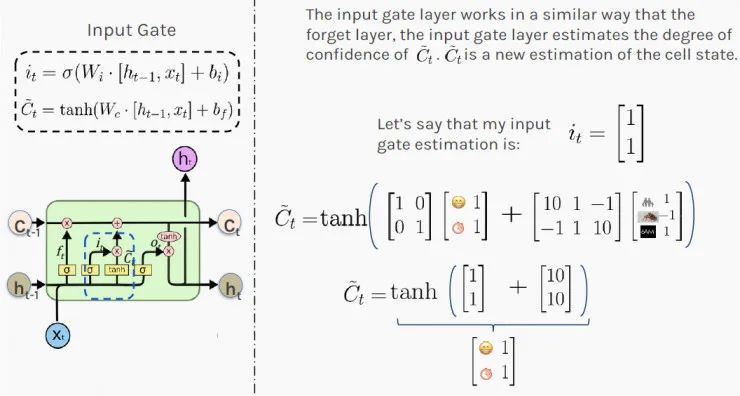
接下来,你需要决定:最近发生的事情(隐藏状态h)和今天发生的事情(输入x)中的哪些信息需要记录到你对所处情况的长远判断中(状态状态C)。LSTM通过使用“输入门”( Input Gate)来决定要记住什么。
首先,你要计算输入门的值 i_t,由于激活了sigmoid函数,值落在0和1之间;接下来,你要tanh激活函数在-1和1之间缩放输入;最后,你要通过添加这两个结果来估计新的细胞状态。
结果[1,1]表明,根据最近和当前的信息,你100%处于良好状态,给员工加薪有很高的可能性。这对你的员工来说很有希望。
秘密5 :LSTM使用“细胞状态”保持长期记忆
现在,你知道最近发生的事情会如何影响你的状态。接下来,是时候根据新的理论来更新你对所处情况的长期判断了。
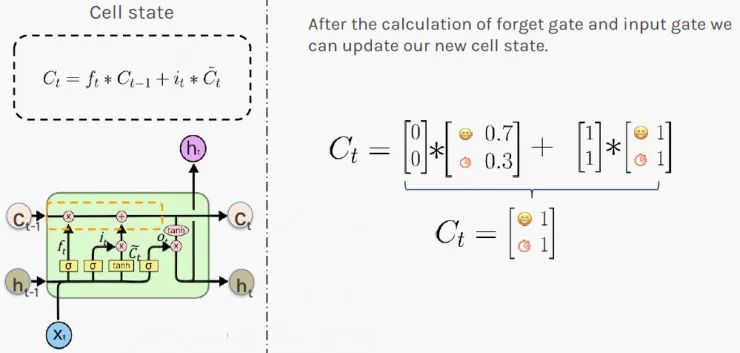
当出现新值时,LSTM 再次通过使用门来决定如何更新其内存。门控的新值将添加到当前存储器中。这种加法运算解决了简单RNN的梯度爆炸或梯度消失问题。
LSTM 通过相加而不是相乘的方式来计算新状态。结果C_t 被存储为所处情况的新的长期判断(细胞状态)。
值[1,1]表示你整体有100%的时间保持良好的心情,并且有100%的可能性一直都有钱!你是位无可挑剔的老板!
根据这些信息,你可以更新所处情况的短期判断:h_t(下一个隐藏状态)。值[0.9,0.9]表示你有90%的可能性在下一步增加员工的工资!祝贺他!

1、门控循环单元
LSTM细胞的一种变体被称为门控循环单元,简称GRU。GRU 是Kyunghyun Cho等人在2014年的一篇论文中提出的。
GRU是LSTM细胞的简化版本,速度比LSTM快一点,而且性能似乎也与LSTM相当,这就是它为什么越来越受欢迎的原因。
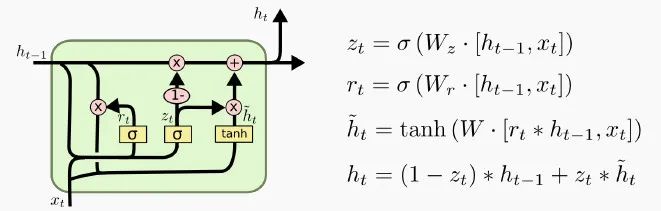
如上所示,这两个状态向量合并为一个向量。单个门控制器控制“忘记门”和“输入门”。如果门控制器输出 1,则输入门打开,忘记门关闭。如果输出0,则相反。换句话说,每当必须存储内存时,其存储位置先被删除。
上图中没有输出门,在每一步都输出完整的状态向量。但是,增加了一个新的门控制器,它控制之前状态的哪一部分将呈现给主层。
2、堆叠LSTM细胞
通过对齐多个LSTM细胞,我们可以处理序列数据的输入,例如下图中有4个单词的句子。
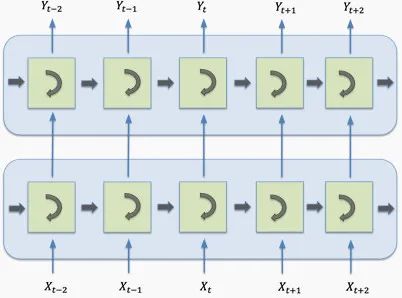
LSTM单元通常是分层排列的,因此每个单元的输出都是其他单元的输入。在本例中,我们有两个层,每个层有4个细胞。通过这种方式,网络变得更加丰富,并捕获到更多的依赖项。
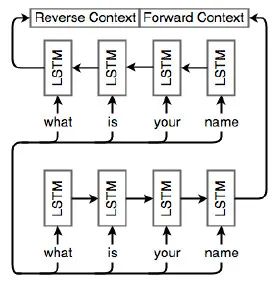
3、双向LSTM
RNN、LSTM和GRU是用来分析数值序列的。有时候,按相反的顺序分析序列也是有意义的。
例如,在“老板对员工说,他需要更努力地工作”这个句子中,尽管“他”一开始就出现了,但这句话中的他指的是:在句末提到的员工。
因此,分析序列的顺序需要颠倒或通过组合向前和向后的顺序。下图描述了这种双向架构:

下图进一步说明了双向 LSTM。底部的网络接收原始顺序的序列,而顶部的网络按相反顺序接收相同的输入。这两个网络不一定完全相同。重要的是,它们的输出被合并为最终的预测。
想要知道更多的秘密?
正如我们刚刚提到的那样,LSTM细胞可以学会识别重要的输入(输入门的作用),将该输入存储在长期状态下,学会在需要时将其保留(忘记门的作用),并在需要时学会提取它。
LSTM 已经改变了机器学习范式,现在可以通过世界上最有价值的上市公司如谷歌、Amazon和Facebook向数十亿用户提供服务。
自2015年中期以来,LSTM极大地改善了超过40亿部Android手机的语音识别。
自2016年11月以来,LSTM应用在了谷歌翻译中,极大地改善了机器翻译。
Facebook每天执行超过40亿个基于LSTM的翻译。
自2016年以来,近20亿部iPhone手机上搭载了基于LSTM的Siri。
亚马逊的Alexa回答问题也是基于 LSTM。
扩展阅读
如果你想知道更多关于LSTM和GRU的信息,可以阅读Michael Nguyen写的这篇带有动画说明的文章:
https://towardsdatascience.com/illustrated-guide-to-lstms-and-gru-s-a-st...
对于那些喜欢从头构建LSTM模型的人来说,这篇文章可能会有用:
https://towardsdatascience.com/illustrated-guide-to-lstms-and-gru-s-a-st...
下面,我将提供使用Python实践实施LSTM网络的方法。
1、情绪分析:一个基准
https://towardsdatascience.com/sentiment-analysis-a-benchmark-903279cab44a
基于注意力的序列到序列模型和Transformer超越了LSTM,最近在谷歌的机器翻译和OpenAI的文本生成方面取得了令人惊叹的成果。
2、NLU任务注意力机制的实践指南
https://towardsdatascience.com/practical-guide-to-attention-mechanism-for-nlu-tasks-ccc47be8d500
使用BERT、FastText、TextCNN、Transformer、Se2seq等可以全面实现文本分类,这个可以在 Github库中找到:
https://github.com/brightmart/text_classification
或者你可以查看这个关于BERT的教程:
https://towardsdatascience.com/bert-for-dummies-step-by-step-tutorial-fb90890ffe03
本文转自:AI科技评论,转载此文目的在于传递更多信息,版权归原作者所有。





