作者:leonwei
在基于ue的手游开发中,经常会发现android系统的实际内存占用要比我们预估的高很多,优化内存的占用就要先明确究竟每1k实际的内存占用分布在哪里及如何运用工具有效的获取真实的内存组成,本文将结合项目经验详细介绍这个部分,并据此分别介绍一些常用的瓶颈和优化。最终了解你的android程序中的每1k内存。
一、Android程序内存分配原理
Android内存管理基础
Android内存的管理核心是paging和memory-mapping(mmap)。
Paging
Andoid系统中使用虚拟内存地址来索引内存,虚拟内存被划分为固定大小的page页,典型的页大小为4K。内存分配最开始都是在虚拟内存上分配,当需要访问这段内存的时候,如果发现它没有存在于物理内存上(即MMU不能找到这个虚地址va对应的物理地址pa),即发生了缺页(page fault),缺页有几种可能:
① Bug,程序访问了它不应该访问的虚地址空间,android系统会触发访问不合法,kill掉进程
② Va是合法的,但是这块va对应的pa还从来没有被分配出来过(例如你mmap的一段内存空间,但是从来没用过,这时第一次在这块内存上写入),这叫做lazy-allocation,这时系统会真正分配一段物理内存给你用,然后在页表上对应好这段pa和va。注意第一次写入这里才算真正占用了物理内存,mmap的分配并不算。
③ Va是合法的,但是这va对应的pa内容当前并没有在物理内存上,而是被swap到一个backup的file上,这时系统会给这个page在pa上分配物理内存,然后将这块内容从文件读回到物理内存上(swap-in)。
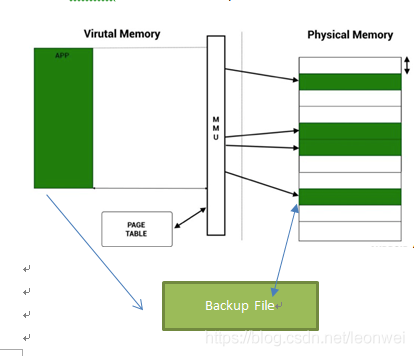
Swap和zram
典型的linux系统的虚拟内存都有swap操作,即一段物理内存在一段时间不用的时候,为了节省物理内存将他们备份到它的backup file上,一段时间后缺页时再换回。
但是在android上大多数情况是没有这套swap机制的,因为对于移动端的IO代价太大,所以大多数情况被映射到pa的page是不能被swap的。只有一种情况除外,即如果这段虚拟地址段具有backup file,并且当他被swap-in到pa后是只读的,那么它是有机会被swap-out回disk的,因为swap这种内存的代价很小,他们不会在物理内存上被更改,通常这类情况包括那些代码文件的mmap(如dex so等)。
此外android上还使用了一种特殊的ZRAM机制来压缩一些物理内存上的page,但是并不把他们swap-out到disk上,而是仍然在ram中,这是一段被压缩了的page,系统会选择压缩一些page存储在内存中以腾出一些物理内存的占用。
MMAP
Linux上一个重要的特性是memory mapping。如上面所述,va和pa之间通过mmu建立了一个对应关系,通过page fault来触发pa的分配,此外va还会对应一个backup file,作为swap-in/out时的备份存储。这个va和backup file之间的对应关系就叫做memory mapping,我们可以利用这个机制做文件读取。
Memory mapping的调用函数是mmap,它的原型是
void* mmap(void *addr, size_t length, int prot, int flags, int fd, size_t offset)
void munmap(void *addr, size_t length)
addr为预映射的虚拟内存地址起始(传null则让系统给你分配)
length为大小
offset为偏移
prot为这段地址区域的保护方式:
-PROT_EXEC(可被执行)
-PROT_READ(可读)
-PROT_WRITE(可写)
-PROT_NONE(不能存取)
flags代表为这段区域的各种特性:
-MAP_FIXED:如果传入是start地址不能成功建立映射,则放弃映射
-MAP_SHARED:对映射区域的写入会复制回它的backup文件,而且允许其他进程共享对该文件的映射
-MAP_PRIVATE:对映射区域的写入会产生一个backup文件的复制,且这个区域的修改都不会再写回backup文件(shared和private必须二选一)
-MAP_ANONYMOUS:匿名映射,忽略文件fd参数,且映射区域不能和其他进程共享
-MAP_DENYWRITE:只能写入映射的内存,不能直接写入文件
-MAP_LOCKED:锁定映射区域、,说明该段不能被swap
它有两种用法:
第一种是映射文件到内存做读取, 这时提供一个文件句柄,然后将文件内容映射到一段虚拟内存地址空间,这样就做到了通过访问虚拟地址空间--造成缺页—swapin backup file的方式来根据需要读取文件。他相比传统的文件读取效率更高。
第二种是创建一个匿名映射,匿名映射没有backupfile,只是单纯分配一块虚拟内存空间,这其实是android上调用new一个对象做的事情,我们new一块int的数组,事实上在new后很可能是通过mmap分配了一块虚拟内存空间,而只有当第一次写入的时候才触发缺页而占用真正的物理内存,所以统计android的物理内存占用不是看new了多少,或者文件映射了多少,而是实际上虚拟内存缺页了多少。
MMAP和new malloc
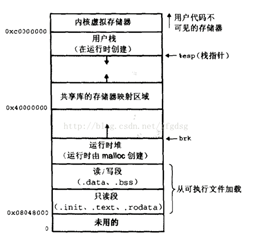
我们知道我们可以用new创建对象,new里面就是用的malloc/calloc等分配内存空间,那么malloc和mmap之间是什么关系呢。首先new 和malloc是c++/c语言层面的事情,实际在类linux的操作系统层面,给用户提供的申请内存的函数只有brk/sbrk和mmap函数。
如下图典型32位系统中一个进程的虚拟地址空间分布状态,sbrk的作用就是扩展heap部分的上界,可以传入一个分配的大小,并返回新的brk地址。
Malloc函数当申请小内存时使用sbrk来分配内存,大内存则使用mmap申请,如果是这种情况,这时的malloc并没有申请物理内存的占用 。但实际上大部分malloc的实现都会在操作系统内再维护一个内存池,它会预先申请一块较大的连续内存复用,最终都是走的mmap。
二、Android程序的内存构成
有了前面的android的内存管理的基础知识,这里谈下android进程的内存组成
从adb meminfo说起
当我们运行adb shell dumpsys meminfo xxx.xxx.xxx的时候将得到一份最简单的android程序内存报告,这里面的pss+swap的总量也是我们android内存统计的金标准。
一个典型的adb 内容如下
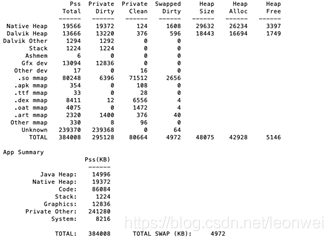
这里面可以看到pss privatedirty privateclean swapped diry 这几个重要的指标
这里能看到的所有值都是物理内存大小,即缺页的那些虚拟内存的大小,而不是真正虚拟内存的大小,注意这里看到的所有内存大小都是真真实实占着你的物理内存的(比如我随便new 1个int[1024],在你对这块内存写入之前它都不会占用物理内存并体现在这里。)
PSS是指proportional set size,是指你的进程实际占用的物理内存大小,但是android内存涉及到在系统中同其他进程共享一部分库(可能是so,可能是字体文件等的mmap),所以这里面会考虑这个因素计算你的进程平摊的这部分共享库的大小,这里的p就意味着统计了这个平摊后的物理内存。这是衡量进程占用内存的最真实指标。
Private Dirty和Private Clean则是完全该进程自己(而不包括和别人共享部分)占用的物理内存,clean是指那部分可能被swap的内存部分(即前面说到的拥有backup文件,mmap之后一直保持只读状态,他们具有被swap out的可能,比如你的so库文件。),而dirty部分就是除clean之外那些不能被swap的内存。Private Dirty通常是你的进程内存最需要优化的地方,因为他们是大头。
Swapped Dirty指的并不是被swap-out出去的内存,而是android系统中zram机制压缩掉的部分Private Dirty部分的不常用物理内存,这个重要度等同于Private Dirty,因为哪些Private Dirty会被压缩不能被控制,所以这部分多通常也是Private Dirty 的。
因为PSS中已经包含了Private Dirty和Private Clean,但是没包含swapped dity,所以最终衡量你的进程对物理内存的占用应该是取PSS+Swapped Dirty
下面则是按照各种category分别统计的内存值,仍然很有意义。
Native Heap:这是C/C++层直接通过malloc分配的内存,在UE的框架中你几乎不会在ue代码中分配到这部分内存,因为UE的所有malloc都统一走了UE的内存管理机制FMalloc,而Fmalloc的底层使用的mmap。所以当你看到Native Heap存在数值较大,一般只有几个大的可能:除ue之外引入的其他第三方库,以及一个很大的大头gles的driver在client内存一侧的分配。这部分的内存通常普遍较大,且剖析比较复杂,在非root的android机几乎很难用正常的方法hook到,是很多UE手游内存分析人员的盲区,这部分profile我们后面详细讲。
Dalvik Heap/other:这是android的java虚拟机分配的内存,也就是java部分分配的,ue基本不直接写java层代码,所以大的话多数是接入的第三方SDK分配的,这部分可以很容易的用android studio的memory profiler看到分配堆栈。
Stack:很好理解栈分配内存
Ashmem:进程的匿名共享内存 Anonymous Shared Memory ,通常不会很大,和操作系统有关系
GFX dev:通俗来说是你的显存,android 显存和内存在同样的物理设备上,所以统计的总内存是包括显存的,至于adb如何知道哪些是显存,是因为gles和egl的so库在分配显存的时候也是使用的带backup文件的mmap,adb只是简单的统计了所有gles和egl的mmap将其视为显存,这部分通常就是在gpu上的资源,gpu上的资源由很多种,占大头的就是texture,buffer,shader programe,这个是所有游戏的大头,后面也会详细讲这部分的profile。
Other Dev:除显卡外所有其他硬件设备的mmap后的物理内存,可能包括声卡等,通常不多。
.so mmap:这个就是so库本身文件mmap占用的物理内存,我们随着游戏进度会逐渐的读取我们的so文件,造成和缺页的部分就是在物理内存产生占用,这部分大就是so库太大了,但是这部分因为有很多是readonly的mmap,所以有更大的机会被swap-out出去。
.apk .dex oat .art mmap:这些都是android 程序文件本身被mmap占用的内存,和so的性质差不多。
Other mmap:是所有除了上面的之外其他的所有非匿名方式的mmap,想要知道是什么可以通过下面要讲的命令查看。
Unkonwn:在UE程序中这部分通常是最大的一块,在meminf中它指所有的匿名mmap,因为是匿名的,所以meminf不知道是什么,就统计在unkown中,用匿名映射做的mmap基本就是mmap方式的内存分配,在ue中ue自己的Fmalloc系统使用的就完全是mmap方式的内存分配(改成ansi方式除外),所以这里的unkown内存基本等同于UE的fmalloc的内存,就是你的ue程序分配的内存。看,通过ue的fmalloc的内存其实只占整个android进程内存的一部分而已,我们通过ue的llm_full等跟踪到的内存其实只是这个unkown内存的部分。
RSS 和 VSS
上面说的是PSS的统计,其实还有两个口径的内存统计,RSS和vss
通过adb shell top可以查看所有进程的rss vss信息。
RSS即resident set size,它表示该进程本身除了和别的进程共享部分实际占用的物理内存,即比pss小一些。
VSS则是值改进程分配的虚拟空间大小,这个值通常意义不大,因为理论上你的虚拟空间可以分配的很大,比如你要mmap很多的文件,但是并不代表你要同时访问这些文件在物理内存上。
了解android的每1k内存 -- 查看进程完整的虚拟内存空间映射情况
到这里为止我们知道了使用简单的adb指令查看android的内存组成,那么adb meminfo又是根据什么统计出来了呢,其实可以去查看adb meminfo的代码实现,它基于了更详细的虚拟内存映射信息。
通过指令adb run-as xxx.xxx.xxx cat /proc/pid/smaps 可以查看到当前整个进程的虚拟内存映射情况,即每1k物理内存是在哪里发生的。如下表是其中的一部分
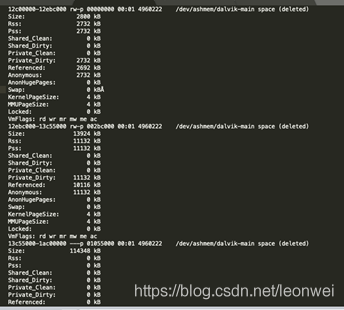
这里面详细记录了你的进程的每一块虚拟地址空间的分配情况,如图中的第一个block中,说的是12c0000-12ebc000这块连续的虚地址空间,它的大小是2800K(虚拟地址大小),它也映射的物理内存RSs和pss都是2732kb,后面的ashemen说明它是一个匿名共享内存,最终会被统计到adb meminfo的ashm中 。
这个文件很大,很详细,我们还可以得到一个更简要的信息,通过命令
adb shell run-as xxx.xxx.xxx pmap pid –x 可以得到规整成下面的一个表
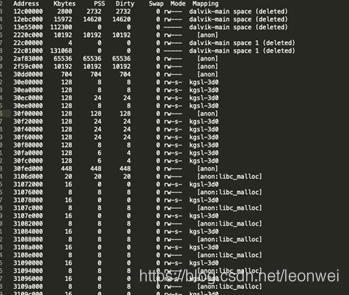
这个表更容易看,分别列出来虚拟内存其实地址,大小,映射的pss物理内存大小,内存属性,以后后面的mapping的来源。
从mapping的来源我们可以简单推测这个内存的创建来源。例如有这么些可能:
如果看到dalvik-main,那它一般是java 虚拟机的native 分配,这个最终会被统计到meminf的dalvik里。
Anon:这个就是匿名mmap映射,最终会被统计到meminf的unkown里,这个在UE中就是所有的Fmalloc
Anon:libc_malloc 这个是通过malloc方法进入的mmap,即你所有的new ,malloc调用,在ue里面这个基本就是第三方库的malloc分配,当然还有一个大头是gles 的driver的malloc分配。
Kgsl-3d则是gles对显存硬件的虚拟内存映射,换句话说就是显存,meminf正是统计这个标签来获取gfx的大小。
在后半段还会看到**.SO,这个不是说这个so分配了多少,而是这个so文件本身在虚拟内存映射后缺页的物理内存大小,即so文件被当前读入到内存上的大小,这个会动态改变,因为程序对so的访问也是动态的
还有***.ttf,这个就是对ttf字体文件的读取,同so的读取一样。
可以看到,其实adb meminf也是靠这个pmap映射算出来前面那份报表。
根据这个映射清单,我们基本可以先大致一眼瞄出程序的主要内存占用在哪。作为UE手游,通常你要关注的是
Nativeheap(主要是gl的driver和第三方库,会很大,你的图形资源是否太多)
GFX(显存,贴图,buffer,shader,你的图形资源是否太多)
Unkown(UE中的fmalloc)
So mmap(So库是否太大)
当然从这里还是不能给出一些指导意见,所以我们需要再详细分解这些内存的使用,因为我们基于了UE4引擎,所以我们还有更多的手段。
UE程序的完整内存组成
因为在UE引擎内部的内存分配和释放望去可以在引擎层hook住,所以UE引擎范围内的内存使用我们是可以详细的追踪细化的。在引擎层我们能hook住的内存分配主要来自两块:
① 通过FMalloc对内存的分配。因为UE用fmalloc承接了所有new/delete,所以通过在fmalloc这层去hook,可以抓住这些分配。另外malloc底层又通过mmap去分配,等于通过追踪UE的fmalloc可以追踪整个android内存的Unkonw部分,即匿名mmap映射部分。
② 通过对graphic api的调用而触发一些gpu资源的创建。例如通过一个glcreatexxx可以创建某个显卡资源,整个过程会产生driver的开销即gpu上显存的开销,在很多平台我们不太可能准确的查询到这里面多分配了多少内存,但是至少可以根据资源估计出在显卡上的显存开销。这个显存的开销就对应了gfx部分。
所以在ue的引擎内部我们有可能容易的细化上面说的Unkonw和GFX部分。而UE引擎为我们提供了这个机制,即LLM(Low Level Memory Checker)
2.1LLM
LLM通过插入各种tag来将所有待统计的内存划归到某个tag下。通过维护一个tag的堆栈,将fmalloc到的内存统计到当前栈顶的tag下。Llm在最底层hook了fmalloc的每一个统计,如果没有任何tag在当前栈中,那么所有内存计入在untagged这个tag下,如果我们在代码中插入一个基于scoped的tag,就可以把这个scope下的内存计入你的tag下。通过LLm我们不会遗漏任何Fmalloc分配的内存。
此外程序刚初始化的时候,LLM会记录一个内存,被它估计为可执行程序本身的内存,记在Program这个tag下。而rhi每个对于gpu资源的创建也会被LLM记录在额外的texture,buffer等标签下,他们不是fmalloc内存的一部分,是对GPU的内存占用的估算。
LLM的类型
LLM主要分两种,即两种统计口径,分别为default和platform,他们是两个维度的统计。
LLM基于代码中定义LLMTag来伪每个内存打标签,一个tag要至少包含类型名,组名,可以通过查看LLM_ENUM_GENERIC_TAGS这个宏来看所有的tag。
一个tag要么属于default的统计范畴,要么属于platform的统计范畴,这个可以通过查看DECLARE_LLM_MEMOPRY_STAT这部分代码来判断属于哪个口径。
default和platform的tag会同时设置,也就是说default和platform会同时统计每个内存的使用,每个内存都会被default和platform的某个tag同时抓到。
default-统计和平台无关的内存(即无论到哪个平台上,default的内存都是差不多的)
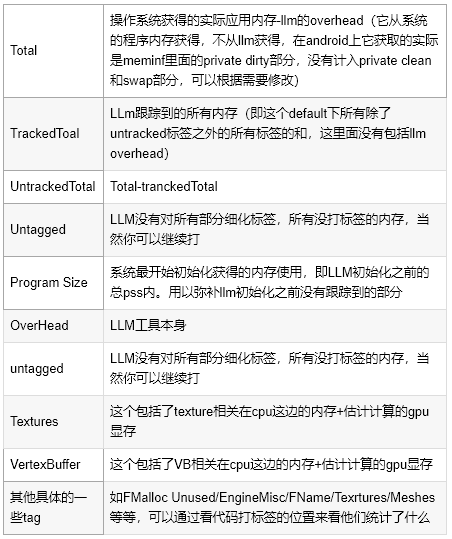
通过stat LLM和stat llmfull 可以看到详细的统计。前者是按大组去统计的,后者是细分的。主要的统计项目包括:
platform-统计和平台相关的
通过stat llmplatform可以看到详细的统计,主要项目包括

可以看到上面一些tag是存在交叉的,例如platform口径下的fmalloc实际上包含了default下面的很多tag的和。
之所有有这样两个口径是方便我们从不同维度理解内存的组成,platform的维度和机型平台相关,default则和平台无关。当然无论哪个维度,加起来的总和是一样的。
怎样打开并使用LLM?
1.默认dev debug 包才开启,如果在test包开启,则需要设置宏ALLOW_LOW_LEVEL_MEM_TRACKER_IN_TEST= 1
2.需要连接调试器启动,例如xcode或者android studio
3.加上启动参数 -LLM
4 如果启动参数带上 -LLMCSV 则会定期将结果自动保存在磁盘为csv文件。
5.带上启动参数 -LLMCSV可以写到csv里面
运行时,输入指令stat LLMFULL 和stat LLMPLATFORM 分别看到default和platform两种统计口径的结果
2.2 构建你的UE程序的android内存清单
在对一个基于UE程序的android进行内存剖析的时候,第一件事情一定是生成一个报告,这个报告可以说明总的pss的每一k分别分布在哪里,这才是解决一切问题的前提,不然都是盲猜。
在这里我们需要试图整理出一个完整的UE程序的内存清单。
从最前面我们知道Android内存从meminfo上来看可以分为
Nativeheap
Davik
Gfx
.so/.dex/.oart map…
Unkonw
而UE的fmalloc采用匿名映射,基本代表unkonwn的部分,而且ue还估计了tex buffer的显存,可以认为代表了大部分的gfx。而LLm肢解了fmalloc和显存这部分。
所以可以认为用llm我们首先就分解开了gfx的大部分和unkonw的全部。
那么然后是其他的几个部分,需要我们自己做点工作了。
NativeHeap部分
这部分是所有通过malloc分配的内存。UE内部的任何内存分配都不在这里,那么这里主要是什么?主要是其他任何第三方so通过malloc获取的内存,事实上ue内部也可能存在某些插件不走统计的fmalloc而是直接malloc系统内存,那么也会进入这里。这其中最大大头的一个so通常就是那个叫做libgles***.so所分配的,它代表显卡driver在driver层分配的内存(注意不是显存)。
这部分内存通常很大,怎么分析。我们需要把这部分内存的分配hook到。
如果是root的版本(或者是非root但是android10以上版本)你可以参考这个文档https://source.android.com/devices/tech/debug/native-memory上的一些方法,包括其中介绍的malloc debug,perfetto等方法,强烈推荐的是android-10以上可以用的perfetto,如果是任意一台一些低端机,那么就只能采用一些hack的方法。我推荐一个开源的项目xhook https://github.com/iqiyi/xHook,是通过 PLT (Procedure Linkage Table) 的技术hook住任意函数的调用,当然就包括malloc。
在笔者的项目中集成了这个xhook,然后我hook住所有so的malloc,relloc,calloc,free。就可以拿到每个so的native heap的分配,他们的和就等于这个nativeheap的值。
一个典型的UE手游的nativeheap的分解值可能是这样的:

不出意外gles相关的so会是绝对大头,它是显卡的driver部分(我们后面分析显存的时候在细讲),另外我们看UE4本身也会有走非fmalloc的代码,是其中的某些plugin。
除了可以通过这种方法拿到每个so占用的nativeheap,还可以自己写些代码拿到具体这个so的nativeheap分布在了那里。例如我想分析gles的driver占用的这125M内存是从哪来的,有的人说gles的driver是显卡driver决定的,我们无法介入,确实这里是一个黑盒,但是所有的driver内存分配究竟还是你的每一个gl api调用而产生的,通过在你的每个glapi调用前后打tag,你还是应该能够统计到这些内存究竟同什么样的api调用相关,你就知道该优化什么。
例如笔者在项目中在所有的gl api前后打一些tag,来分段统计这个hook到的gles的nativeheap,可以非常精确的拿到几个大户对driver的内存分配情况,例如tex,buffer,shader的创建。此外我们甚至还可以结合具体逻辑再细分tag,拿到具体哪些类型的buffer更占显卡driver等等。
GFX和显存相关部分
显存通常是一个UE程序的绝对大头。在Android程序中,显示相关资源需要的内存包括:
A CPU游戏引擎测需要对应的结构
B Meminfo上GFX部分的显存
C Meminfo上面的GL Mtrack
D Meminfo上面的EGL Mtrack
E 显卡driver分配的
其中A包括为了创建贴图,buffer等在cpu这边的结构体,原始数据等,已经被LLM统计了,他是内存的部分,相对好追踪,就不讨论。
B出现在adb meminfo上,是我们常规意义上称为的显卡访问的存储资源,显存。它的统计方法是统计pmap中显存mmap映射文件(adreno上是kgsl-3D0这个文件)的pss部分。
C 这一项只有较新的设备有,因为android上显存的管理和内存不一样,不是采用虚拟内存映射,缺页后再调入物理内存,而是虚存vs有多大,就直接为其分配多大的物理内存。所以很多老的系统只统计B而计算出的总PSS其实是要比真实物理内存占用要小的。而GL Mtracker这个项正是统计了那些pss映射为0的部分的vss大小。所以这个加上B才是真实的显存大小 ,如果你的android系统不统计C,那么可以自己去pmap里面累加。
D 这是EGL分配的硬件资源,因为一些显示资源不是gl分配的,例如backbuffer是系统从窗口系统中分配的,这属于egl的分配范畴。一些老的系统没有统计这个。
E opengl是一个client-server架构,server指的是显卡那部分,client指的就是CPU这侧的dirver部分,很多显示资源不只需要在server部分对应显存分配,同样需要消耗大量的client部分的driver内存。例如去创建一个新的glbuffer,不管这个buffer实际上有多大,笔者在一些adreno机器上测试它在driver这块都需要分配固定的4096+284k的内存,因为driver内部要维持一个渲染状态和结构。例如去map一个glbuffer,那么driver这边通常是需要malloc一个这个glbuffer大小的buffer出来,用来接受你对map结果的写入,driver在合适的时机再同步给server那边的glbuffer。所以gl的driver部分的内存是不可忽视的一大块,它就是我们前面将的那一节的nativeheap的gles的部分。
很多老的机器系统因为不统计C和D,会导致pss看起来比实际小很多。
A在llm中有,E在nativeheap中获取,这里面我们还不能拿到准确组成的是BCD,即真正显存上的那一部分,但是如果我们看gl文档,gl资源的组成主要就包括以下几种:texture,buffer,shader和program,sampler,queryobject。而大头主要就是texture,buffer,shader和program。所以我们可以推测。事实上在UE里面已经对texture和buffer进行的推测。
在gl每次创建tex和buffer的最底层,UE都加了一个hook,根据当前tex和buffer的属性推测了程序实际使用的tex和buffer大小,我们通过指令stat rhi,可以看到ue推测的各种类型的tex和buffer内存。那么bcd三项的和减去ue推测的tex和buffer,就只剩下shader和program的内存了。
这里我们对显存可以拿到完整的清单。当然对于bcd三项我们还有其他方法,例如截帧软件可以截取当前所有存活于显卡的渲染资源,包括看到所有的tex,buffer,shader,也可以用来辅助定位哪些显示资源占了更多。
.so/.dex/.oart map…
这部分是程序代码文件本身的mmap部分,在游戏过程中,随着随游戏代码文件的读入,而导致缺页分配物理内存,如果项目这个很大,要考虑对so文件瘦身。
Dalvik
这是java虚拟机部分分配的内存,因为我们几乎不会写java代码,所以基本不大,另外也可以轻易的用android studio的profilor分析到这部分内存的产生。
你的内存组成清单
下面我们就可以专业的拿出一个完整的UE程序在android上的内存组成清单,它应该看起来包括这些主要内容。
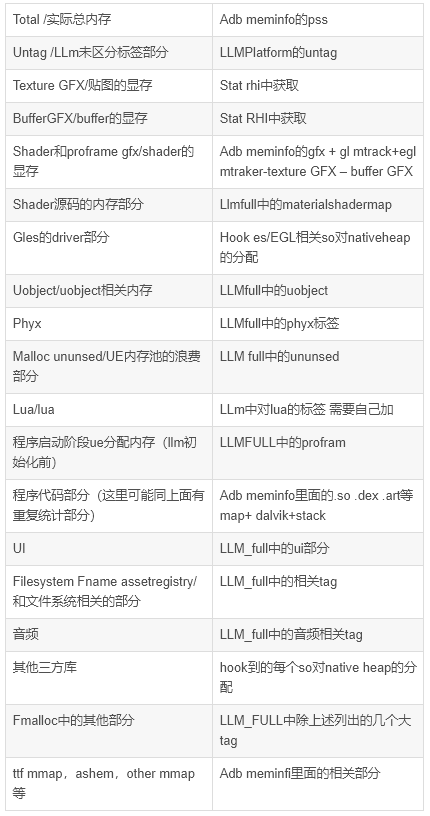
在正常情况下这里面的子项加起来应该基本等于total部分,如果有明显出入,就要再具体分析出入在哪里了。
当我们拿出了这样的一个清单,一个UE程序在android上的内存瓶颈会非常清晰,然后下一步就是去优化这些瓶颈了。
三、UE程序常见的内存瓶颈和优化
这里会对应上面一节给出的内存组成清单,来简要说下可能会成为瓶颈的地方及其常用优化方法。
• 贴图的显存
最有效的方法是砍美术!是的,如果程序的占用显存过大,多少都涉及到过量的美术资源。
当然除了砍美术之外,还包括合适的贴图压缩格式和质量,贴图的合并减少贴图的张数。我们经常以贴图的尺寸,格式来估计贴图占用的显存大小,但是实际上这是个理想情况,实际上在很多硬件上,最终一个贴图对显存的占用还要受很多因素,例如,内存的对齐。笔者曾经在一个snapdragon660的机器上实测过几种不同格式分辨率贴图的实际对显存pss的占用。

大多数情况实际的pss都要比ue估计的更多。这里面似乎存在这样几个规则:
对于astc6*6 4*4,显存的实际分配情况比预估多,猜测至少对于adreno存在astc图像按照16个block对其的情况(因为如果按照16个block对齐计算则同实际pss值一致)
16block对其的情况存在一些基础开销:
开了mip的贴图:28k,因低级mip也须补足最小16 block
同压缩大小不成比例的贴图:astc8*8最适合128 倍数的贴图
astc6*6最适合96倍数的贴图
astc4*4最适合64倍数的贴图
同比例差很大的贴图会产生对其开销,例如1024*1024的带mip的贴图在astc6*6下比预期要多86k(14%)。
所以我们要尽量选用和你压缩质量最匹配的分辨率,并且因为每张带mip的28k的基础开销,能合并贴图尽量合并是能减少内存大小的。
当然为了更贴合实际使用情况,可以修改ue的估算公式。
此外合理的加载,gc,缓存,texturestreaming的使用都是贴图的优化策略。
• Buffer的显存
和贴图一样,要先考虑过量的美术资源使用,除此,还要考虑到:
是否引入了没使用的attributer,如uv2,color
是否用了过多的instance合批造成的instance buffer等。
此外statimesh的streaming也可以考虑打开。
• Shader和program的显存/内存
shader变体是UE的一个老大难问题,在大型项目中,几乎都存在变体爆炸的问题,事实上笔者的项目在shader这块曾经累计抠出来过不下200M的内存。这里面可能需要考虑的策略包括:
尽可能减少母材质,减少对母材质管线属性的的overrider(例如overide它的blendmode就等于新出一个ps)
减少材质可使用的vertexfactory
减少显示的定义更多的materialshaderd模板类型
在materialshader的shoulcompile里面做更多更细致的裁剪,去掉不可能的组合
只加载当前qulitylevel的材质
除了减少变体外,ue中默认永远不会清理已经编译的shader和programe,这会导致你的程序越跑这部分内存越高,到达一个峰值,可以考虑使用LRU动态卸载一些不用的programe,考虑在shader被编译到programe后及时卸载,尤其是使用binarycache的情况下,其实根本是不需要编译glshader的,programe完全从binary生成。
另外包括推迟shader和programe的编译阶段,ue默认在initrhi阶段就编译glshader了,但其实很多情况这个shader根本从来没被用来attach glprogram。
由于ue内部完全没有考虑对glshader的卸载,所以这块需要自己改造一下。
• Gles的driver
如果跟踪gles的native的分配情况,会发现这里面的大头还是tex,buffer和shader的相关操作。一些较常见的问题包括:
创建任何一个glbuffer,在很多机器上都存在一个4k左右的基础开销,无论这个buffer多大,而如果你的游戏使用了大量的buffer,尤其是你用了大量的ubo,你会发现你的ubo真正的显存加起来可能只有几k,但是在driver层用于管理他们的结构内存已经高达几十M!所以一定不要使用大量散装的ubo,你应该尝试使用ue的emulated ubo,或者自己合并全局的ub,并用double buffer去管理cpu和gpu的访问冲突。
另外包括长期的mapbuffer也会在driver分配内存。
此外也可以尝试ue中分开存放的顶点的attribufer buffer,但是pos buffer因为tbdr的问题还是尽量单独存放。
• Uobject
减少数量和减少属性。通过将场景中的物件整合成hism后发布,是可以大大减少uobject的总量的,此外通过objlist dump出每个类型的uobject的数量和内存后,针对性的删掉它们中没用的成员变量
• Malloc unused
这是一个躲不掉的内存开销,因为ue的bin式的内存管理会将所有的内存分配按照固定大小对其从整个page中分配。这个过程至少就存在这样两种浪费:一个是内存的对其浪费,一个是页的空白浪费。避免这个问题,有几种思路:
总的内存分配减少,这部分内存就自然成比例减少。
做好内存对齐,找到那些对其不良的部分,我们可以hook malloc的底层,发现这样的地方
减少内存分配的次数,频繁程度,尤其是短期内的大量分配,它会容易分配大量page,虽然后面内存被释放,但是dirty page已然被撑大而不能有效回缩,造成大量的unused 内存。这里面的重灾区又常见在tarray的频繁resize,可以hook一下所有因tarray的reize导致的内存分配去优化它。如果是renderthread,通常可以用fmemstack,sceneallocater的array来避免频繁的直接内存分配,至于rhithread也有类似于rhicmdlist.alloc这种优化的内存分配方式。
• Lua
包括合理的设置lua的gc参数,gc的步长,阈值等,防止lua到了较高内存才执行gc。此外如果是大量的配置表导致的lua内存则要考虑用其他方式代替,如sqlite。
• 代码的so map
除了减少我们的代码量之外,还要strip掉so的符号,以及不去编译一些用不到的UE特性,plugin等。
• Assetregistry
如果资源量太多,会发现assetregistry,包括fname等都会占用较高的内存,除了我们尽量减少cook清单外,还可以考虑关闭assetregistry,不会对游戏性能造成什么影响。
写到这里文章已经超过1万字了,出于篇幅的限制(事实上是真的写累了..),这里就只列举了一些可能是较大瓶颈的内存问题,当然每个项目都有每个项目特有的问题,就需要case by case了。但是最重要的前提是只要我们建立了合理正确的内存分析策略得到完整的内存分布清单,那么问题就会很容易暴露和定位,解决问题才会成为可能。
总之,工欲善其事必先利其器,发现问题->分析问题->解决问题的最前面应该是找到发现问题的方法论并制作发现问题的工具,而这正是本文想着重讲述的。
版权声明:本文为CSDN博主(leonwei)原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/leonwei/article/details/105459382





