作者:Dylan Hiemstra
编译:ronghuaiyang
导读
使用深度学习检测那些伪装成背景的目标。

匹配背景的伪装。这就是生物学家所说的,当动物为了避免被认出而改变自己身体的颜色以适应周围环境。它的工作原理是欺骗观察者的视觉感知系统。使用传统的显著性目标检测(SOD)来检测这样的目标是一个挑战,因为它的工作原理是识别图像中最引人注目的目标。然而,伪装的物体与背景有很多相似之处,这使得它很难被发现。为了进行伪装目标检测(COD),它需要大量关于视觉感知的知识。一个潜在的解决方案是一个简单,但有效的框架,由一组国际研究人员创建,称为搜索识别网络(SINet)。
目前,由于缺乏大数据集,COD的研究还不是很深入。因此,研究人员创建了COD10K数据集。它包含了10,000张图片,分为78个不同的类别。它是一个混合的图像,包含伪装和非伪装目标,以及纯背景。数据集是使用层次结构构建的。首先,每个图像被分配一个超类别和一个子类别。然后,为每个图像仔细地标注每个边界框。然后,图像也被分配了一组属性,例如:遮挡或不可定义的边界。最后,通过标注每个目标实例来扩展标注。


现在已经讨论了数据集,让我们来看看框架本身。它由两个主要模块组成:搜索模块(SM)和识别模块(IM)。两者都受到了狩猎的启发。首先,捕食者会寻找潜在的猎物。如果猎物被发现,它将被识别并最终被捕获。
搜索模块
就像人类的视觉系统一样,感受野(RF)被用来突出靠近视网膜中央凹的区域,这是眼睛对微小空间变化敏感的一部分。这激发了研究人员使用一个感受野组件来模仿人类视觉系统的感受野。RF组件包含五个分支。将前四个分支拼接起来,并加上第五个分支。之后,组件的全部输出通过一个ReLU函数输出。
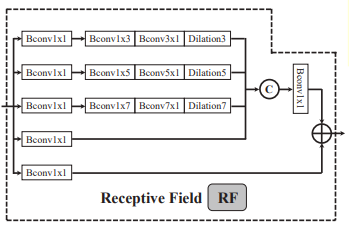
RF组件在SM中多次使用,如下图所示。来自Resnet-50的输入,经过了多个卷积层,上下采样层和连接层。
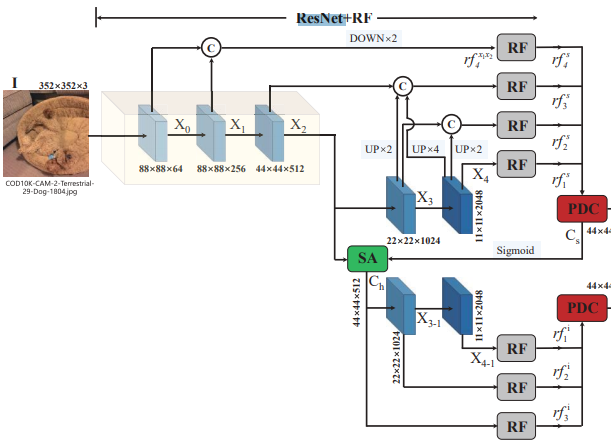
SM中还使用了搜索注意力(search attention, SA)函数,实际上,这是一个高斯滤波器,会生成一个增强的伪装图。
识别模块
接收到搜索模块的输出后,使用部分解码器组件(PDC)精确检测伪装目标。如下图所示,PDC使用SM的四个(一个可选)输入,输出是一个伪装的目标图。

从SINet的完整概述中可以看到,PDC被使用了两次。两者之间的区别在于生成伪装目标图所需的输入数量和输入本身。这两张图通过相加合并,以创建最终的伪装目标图。

Benchmark结果
研究人员使用三个不同的训练数据集测试了SINet,第一个训练集是CAMO数据集,第二个是他们自己的COD10K数据集,最后一个是这两个和一些额外数据的组合。对于模型的评估使用CHAMELEON数据集,测试集是CAMO和COD10K。根据研究人员的说法,COD没有其他的深度学习模式。因此,采用了12个其他非cod模型作为基准。
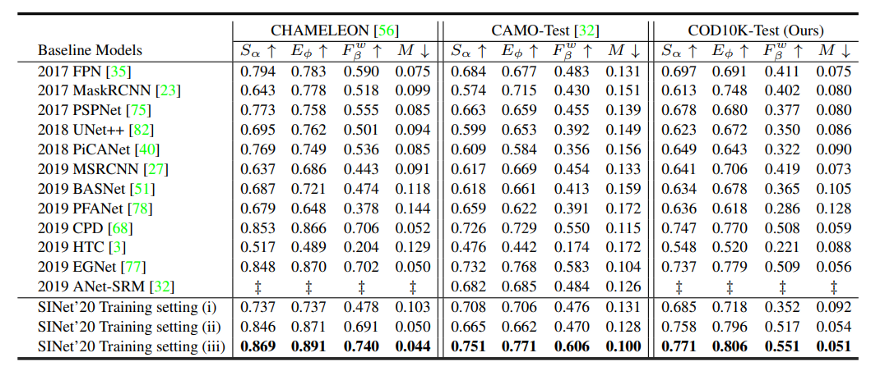
如上表所示,SINet优于其他所有模型。这并不奇怪,因为SINet是专门为COD设计的。值得注意的是,EGNet与SINet的结果相似,但是对比两者的训练时间,EGNet的训练时间要比SINet长得多。分别是48小时和1小时。这表明SINet对COD的解决方案是很有可用性的。
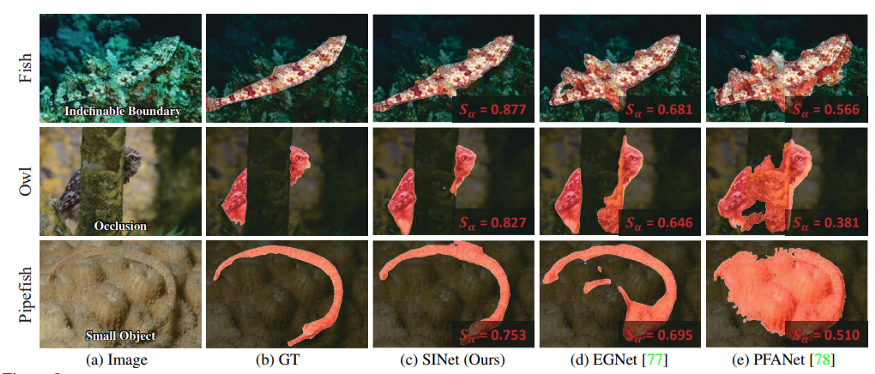
总结
SINet是最早的COD解决方案之一。虽然研究人员承认还有更多的领域需要探索,但看起来SINet将目标检测提升到了一个新的水平。它可以使发现和保护自然界的珍稀物种,发现果园中的苹果,帮助搜索和救援任务,或提高搜索引擎的搜索结果。我很好奇几年后COD领域会发生什么。随着对人类视觉系统了解的加深,我相信COD在未来会变得更好。
英文原文:https://medium.com/swlh/camouflaged-object-detection-using-sinet-b8d6fcae5cf9
本文转自:AI公园,作者:Dylan Hiemstra,编译:ronghuaiyang,
转载此文目的在于传递更多信息,版权归原作者所有。





