来源: AI Lab(Udesk技术团队)
深度学习(deep learning),顾名思义,是一种深层次的学习,也是学习的一种。我们先看看人类是如何学习的。
以幼儿园教授儿童认识汉字为例,按照汉字从简单到复杂的顺序,让小朋友反复看每个汉字的各种写法,并自己临摹。看得多了,自然就记住了。下次再见到同一个字,就很容易能认出来。
认字时,一定是小朋友的大脑在接受许多遍相似图像的刺激后,为每个汉字总结出了某种规律性的东西,下次大脑再看到符合这种规律的图案,考试就知道是什么字了。计算机认字时,也要先把每一个字的图案反复看很多很多遍,然后,在计算机的大脑(处理器加上存储器)里,总结出一个规律来,以后计算机再看到类似的图案,只要符合之前总结的规律,计算机就能知道这图案到底是什么字。

用专业的术语来说,计算机用来学习的、反复看的图片叫“训练数据集”;“训练数据集”中,一类数据区别于另一类数据的不同方面的属性或特质,叫做“特征”;计算机在“大脑”中总结规律的过程,叫“建模”;计算机在“大脑”中总结出的规律,就是我们常说的“模型”;而计算机通过反复看图,总结出规律,然后学会认字的过程,就叫“机器学习”。这里大家可能会有疑惑,如果新出现了没学习过的字,那模型不是永远不可能得出正确答案吗?确实是这样,对于分类问题而言,训练集中没有的类别,在测试集中是不会得到该类别的。这跟我们识字一样,例如我们考试中出现了“淼”这个字,但是我们压根没学过,我们可能根据偏旁猜测,其为“水”的读音。同样,机器也会以一种方式进行猜测,而得到答案。
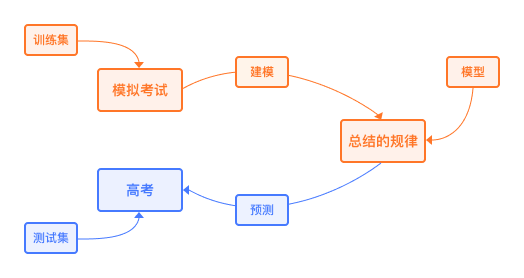
学习的过程再举个例子,如上图2所示,我们高中的时候为了取得优异的高考成绩,会进行多次的模拟考试,如果答案正确,我们相当开心。如果答案错误呢?我们便会寻求他人帮助或者查阅资料等,这个过程就是在积累经验(也就是在调整误差);通过查阅资料,我们大脑又进行了思考,认为此时想出的答案是正确的,最终便得到调整后的答案。通过不断纠正错误的答案与对正确答案的归纳总结,逐步加强认知,进而取得优异的高考成绩。如果让计算机来参加高考。模拟考试的数据叫“训练集”,电脑总结的规律叫“模型”,计算机做模拟题总结规律的过程,叫“建模”。计算机通过不断的模拟考试进而模拟出更强规律取得更高高考成绩的过程,就叫“机器学习”,而深度学习是实现机器学习的一种技术手段。深度学习是通过构建具有很多隐层的机器学习模型和海量的训练数据,来学习更有用的特征,从而最终提升分类或预测的准确性。也就是说,深度学习的基本构造是神经网络,而特点是网络的深度变深了(其实就是隐藏层多了),更加突出特征学习的重要性。

类比于人类解决问题的过程,大脑的思考就是深度学习的模型,是一个非常复杂的过程。学者们从生物神经网络得到灵感,构建了人工神经网络来帮助电脑完成类似大脑思考的工作也就是构建模型。从根本上说,深度学习和所有机器学习方法一样,是一种用数学模型对真实世界中的特定问题进行建模,以解决该领域内相似问题的过程。

我们现在有了神经网络,这个网络究竟是怎样学习的?其中的权重是如何调节的?我们可以把神经网络看成一个给一个输入就能给一个输出的黑盒子。在从模拟题学习做高考题的例子中,我们可以认为这个黑盒可以学习到那些组成题的基本的公式或者基础知识,根据这些知识便可以顺利作出同样依靠这些公式或者知识的题了。
以教小朋友识别数字为例。老师会把0到9这十个数字不厌其烦的教授,直到写一个数字,学生便可以读出这个数字是几。而计算机是怎么完成这个任务的呢?如图所示,输入手写的0,计算机是如何能正确将其归为“0”这一类的。

首先,图像在计算机中需要被转换成数字矩阵的形式,便于计算机识别。如图6所示,利用14*14的像素数字矩阵来表示图片,每个像素点用0-1的数字表示,颜色越深越接近1,空白的部分便用0表示。

然后我们准备一批标注好的数据,如图7所示。图中可以看到不同人的手写方式不同,写数字有非常多的写法,但不同的写法之间仍然有一些相似性,人可以识别出来并且打上标签,之后利用数据进行模型的构建,即从数据中发现数字隐含的规律。
图片

根据模型结构的不同,深度模型有多种不同的构建方式,例如下图所示的卷积神经网络(CNN)模型,将手写数字3的图片先经过卷积层(大致思路是用一个卷积核来过滤图像的各个区域,得到这些小区域的特征值)利用卷积核的特性,抽取出手写数字的关键信息。实际应用中,我们会使用多个卷积核抽取图片中各个维度的特征,例如垂直边缘,水平边缘,数字轮廓等。之后连接池化层(主要是为了进一步降低维度即降低计算量,下图中可以看到一个输入为32*32的矩阵在池化层时已经将数据量缩小为5*5),及全连接层(为了预测最终结果,从图中可以看出经过这一层会将图片对应到0到9数字的某一个上进行输出),共同构建出CNN模型用来预测手写数字。目前,在这项任务上准确率已经可以高达99%以上。
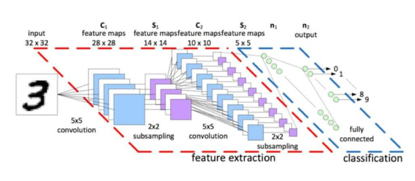
上文形象的叙述了什么是深度学习,并使用儿童学字与中学生参加高考举例来类比机器如何通过深度学习进行训练然后预测。之后简单介绍了使用CNN来构建手写数字识别模型。
本文转自: Udesk技术团队,转载此文目的在于传递更多信息,版权归原作者所有。





