一、简介
本章节我们将介绍如何对图像上的每个像素进行分类,其思想是创建图像上所有检测到的目标区域的地图。 基本上,我们想要的是下面的图像,其中每个像素都有与之关联的标签。最后我们将学习卷积神经网络(CNN)如何为我们完成这项工作。

二、图像分割
全卷积网络分割:
完全卷积神经网络(FCN)是普通的CNN,其中最后一个完全连接的层被另一个具有大“接收场”的卷积层替代。 这个想法是捕获场景的全局上下文(告诉我们图像中我们所拥有的,还给出一些关于事物位置的粗略概念)。

重要的是要记住,当我们将最后一个完全连接的(FC)层转换为卷积层时,如果我们看看在哪里有更多的激活,我们将获得某种形式的本地化。

这个想法是,如果我们选择新的最后一个conv图层足够大,则可以将这种本地化效果放大到我们输入的图像大小。
从普通CNN转换为FCN
这是我们将用于分类的普通CNN转换的方法,即:将Alexnet转换为用于分割的FCN。只是提醒我们,这就是Alexnet的样子:
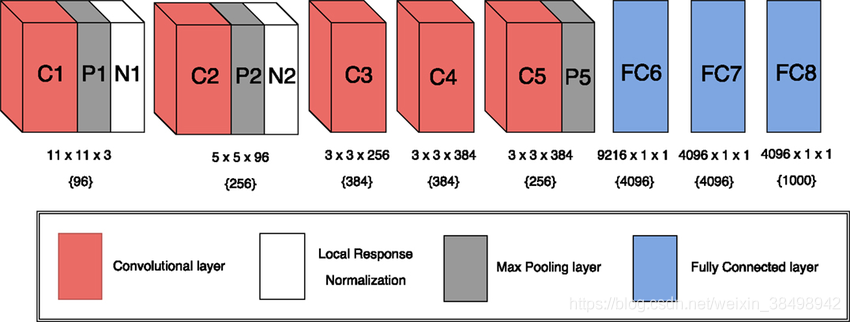
下面显示了AlexNet中每个图层的参数:

在Alexnet中,输入固定为224x224,因此所有池化效果都会将图像从224x224缩小到55x55、27x27、13x13,最后是FC层上的单个行向量。

现在,让我们看一下进行转换所需的步骤。
1)我们从普通的CNN开始分类
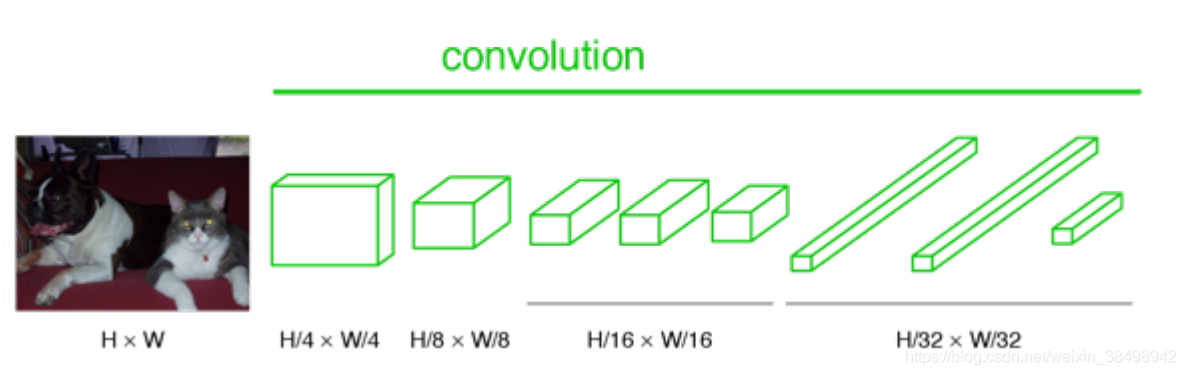
2)第二步是将所有FC层转换为卷积层1x1,我们现在甚至不需要更改权重。 (这已经是一个完全卷积的神经网络)。 FCN网络的优点是我们现在可以使用任何图像大小。

在这里观察到,使用FCN,我们可以使用不同的尺寸H xN。下面的图显示了如何显示不同的尺寸:
3)最后一步是使用“反卷积或转置卷积”层将激活位置恢复到与图像大小有关的有意义位置。 想象一下,我们只是将激活大小扩展到相同的图像大小。
最后的“上采样”层也具有一些可识别的参数。
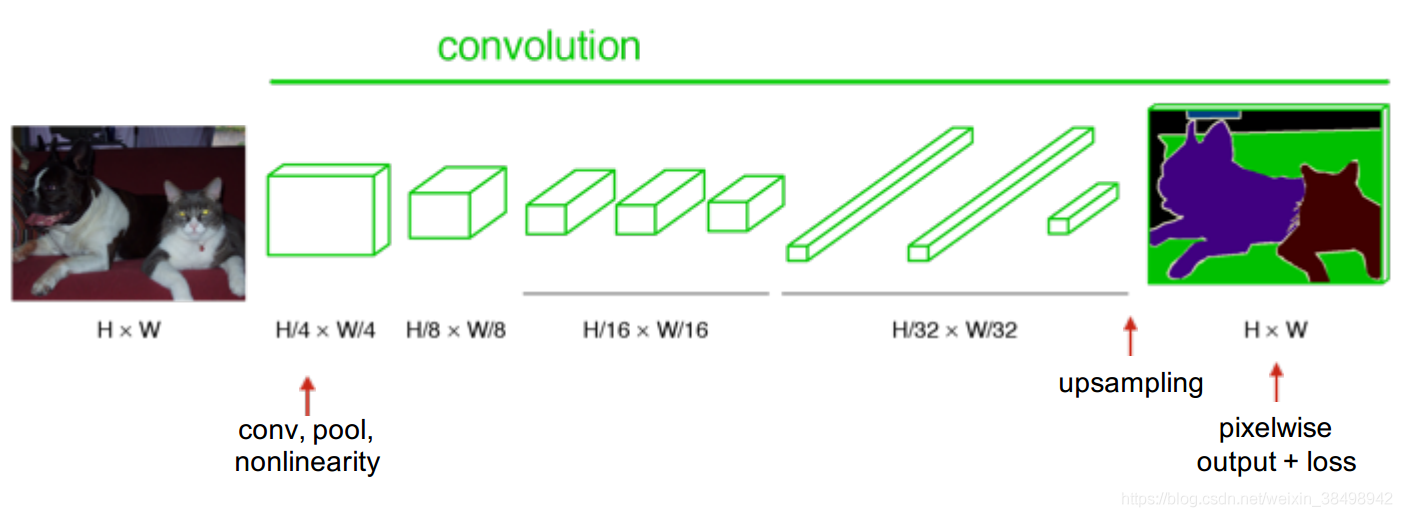
现在有了这种结构,我们只需要找到一些“基础事实”,并从预先训练的网络(即Imagenet)开始进行端到端的学习。
这种方法的问题在于,由于激活在许多步骤上按比例缩小,因此仅执行此操作就会损失一些分辨率。
版权声明:本文为CSDN博主(weixin_38498942)原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/weixin_38498942/article/details/108488153





