作者:隐士低手
1. 画家算法
早期的gpu是没有z-buffer的,为了得到正确的图像,必须使用画家算法,也就是从后往前绘制几何体。几何体每帧都需要根据摄像机的位置进行排序,进而实现从后往前的绘制。画家算法不仅低效,还有一些无法解决的问题,比如几何体循环重叠:
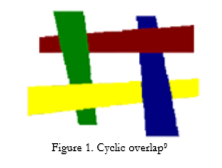
2. BSP树
为了解决画家算法带来的问题,前辈大神们创建了bsp算法。bsp树可以根据相机的任意位置,快速的获得排序后的渲染几何体。而且在生成bsp树的时候可以对重叠的物体进行切割,进而解决了循环重叠的问题。生成bsp树是一件很费时的事情,为了获得一棵相对平衡的二叉树,需要进行大量的试探测试,因此bsp树往往都是预计算的,这也就决定了这个算法比较适合应用于静态场景。bsp树也可以做层次视锥体剔除,比如使用k-d树(bsp树按照轴对称分割),进行遮挡剔除。希望详细了解BSP树的可以参考下面这篇论文。
http://archive.gamedev.net/archive/reference/programming/features/bsptre...
3. Z-Buffer
随着gpu硬件的发展,z-buffer横空出世。深度缓存让我们彻底摆脱画家算法,可以按照任意的顺序进行渲染。但是z-buffer有一个严重的问题就是overdraw。很多被遮挡的像素走完了整套渲染流程,虽然它最终没有在屏幕中显示。z-buffer只能帮助我们正确的渲染,却不能提升性能。
4. Early Z
一个像素的z值信息,其实在光栅化之后就已经确定了,如果能在这个阶段进行z-test那么就可以避免无用的ps计算,于是显卡厂商纷纷推出了early z技术。用来解决overdraw的问题。详细的early z的介绍可以参考下面链接。
https://zhuanlan.zhihu.com/p/53092784
5. 遮挡剔除
early z的性能提升非常明显,由其是对那些ps计算特别复杂的游戏。但是它还不够完美,因为被遮挡的几何体依然需要drawcall,顶点变换,光栅化,甚至是复杂的曲面细分。如果能从源头就把被遮挡的几何体剔除就完美了。但是这并不是一件容易的事情。因为实时的遮挡剔除十分复杂,往往会消耗大量的cpu时间,如果为了优化所耗费的时间比不上优化的时间就得不偿失了。因此如果场景特别复杂,比如城市,深林,遮挡特别多,场景特别复杂,遮挡剔除技术就会发挥巨大的作用。
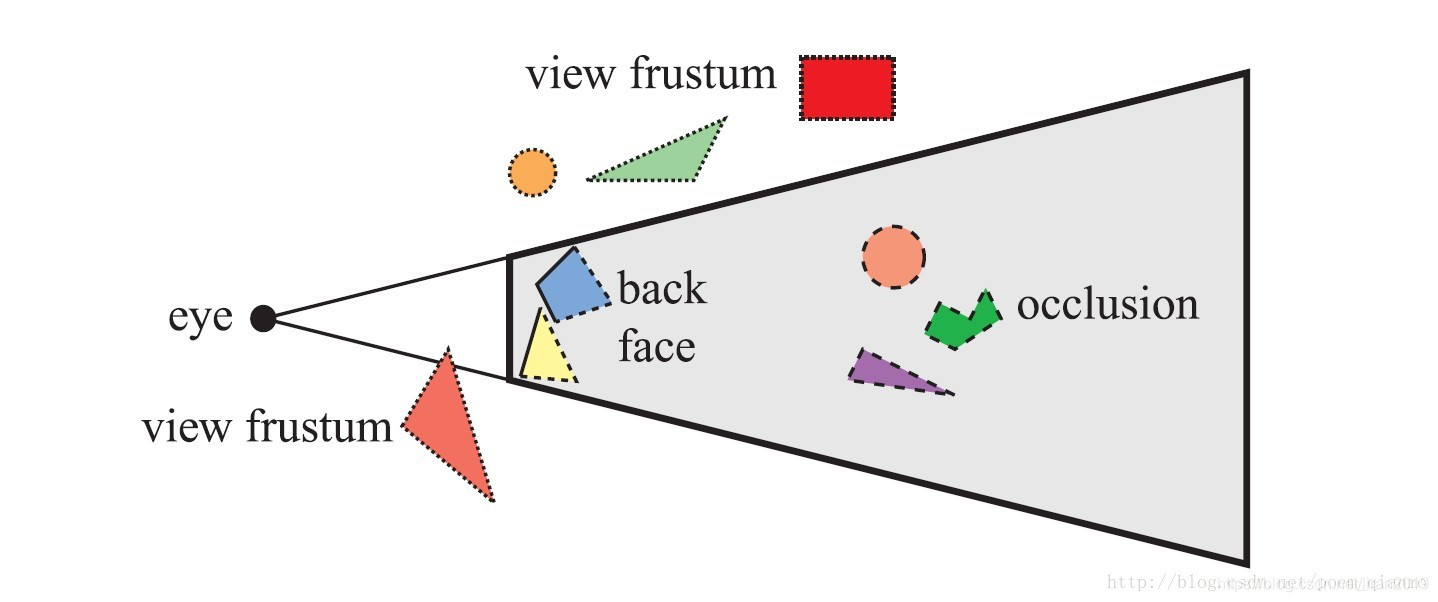
遮挡剔除技术也是不断发展的,我把它分成三个阶段,cpu时代,cpu+gpu时代,gpu时代。
5.1 基于Software Rasterization的遮挡剔除
从几何层面上判断遮挡需要使用光线追踪技术,这对实时渲染来说计算量太大了。因此我们只能通过深度比较进行遮挡剔除,比如我们渲染一个物体如果它的所有像素都被遮挡了,那么它一定是被遮挡了。这么做有点脱裤子放屁,确实在实际应用中我们不会这么做,我们往往使用BV进行测试,如果包围盒被遮挡了,那么就说明这个物体被遮挡了。如果BV是场景管理中的一个内节点,那么这个节点下的所有物体都会被剔除。这才是遮挡剔除发力的关键点,结合BV以及场景管理进行遮挡提剔除。
这里有一个问题就是如何判断一个包围盒是否被遮挡了?早期显卡并不支持硬件遮挡查询,于是一大批引擎采用了Software Rasterization的遮挡剔除方案,比如CE3,天涯明月刀的自研引擎。
首先进行遮挡查询我们需要一张深度图,这张图可以通过纹理保存到cpu中。
另外我们需要一个软光栅化系统,对BV进行光栅化,从而进行深度比较。
基本的思想就是这样,实现的细节有很多,比如使用SSE指令优化软光栅化,选择一个可以排序的场景管理算法,如何选择遮挡体,如何加速图形空间的深度比较等等,但万变不离其中。放一篇参考论文,大家如果感兴趣可以深入了解,这个技术的学名叫做Hierarchical Z-buffer。
Greene N, Kass M, Miller G. Hierarchical Z-buffer visibility[C]//Proceedings of the 20th annual conference on Computer graphics and interactive techniques. ACM, 1993: 231-238.
这种遮挡剔除工作全部都是在cpu端完成。
5.2 硬件遮挡查询
硬件厂商总是会根据需求增加显卡的功能,于是它们提供了硬件遮挡查询,我们可以直接通过gpu查询一个几何体是否被遮挡了。当然查询的原理也是根据深度比较,但是硬件做了优化可以快速的光栅化进行深度比较。这样就可以让cpu从软光栅化中解脱出来。但是整套遮挡剔除的工作不仅仅是遮挡查询,还有一大部分工作是在cpu端进行,于是就出现了cpu+gpu一起完成遮挡剔除的算法。这个算法和上面的算法最大的改变是:
- 遮挡查询交给gpu做了。
- 引入了cpu等待,gpu饥饿的问题。
传统的渲染cpu会把所有的指令丢到gpu中,然后继续执行其他的工作,比如物理,AI,逻辑等等。gpu从指令缓存中读取渲染指令,进行渲染。只要cpu指令丢的够快,gpu就不会饥饿,就像流水线一样。
但是硬件遮挡查询cpu需要等到gpu返回查询结果后才能继续工作,这就会导致cpu进行等待,cpu等待的期间不能给gpu丢指令,从而造成gpu饥饿。如下图R代表渲染指令,Q代表查询指令。
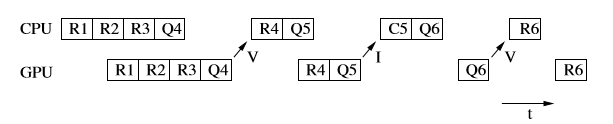
这个问题无法在硬件层上解决,我们只能从算法的角度优化,我们希望能够优化到下图的效果。

这里的优化思想是根据时间一致性,也就是说上一帧的画面和下一帧的画面差距不打,我们可以把上一帧没有被遮挡的物体,假定这一帧也没有被遮挡。我们让cpu进行遮挡查询,但不等待查询结果,我们在下一帧的时候检查上一帧的结果,这样cpu就无需等待gpu。我们假定一部分物体无需判断遮挡查询直接渲染,保证gpu不会因为一直查询而处于饥饿状态。具体的算法可以参考论文。
Bittner J, Wimmer M, Piringer H, et al. Coherent hierarchical culling: Hardware occlusion queries made useful[C]//Computer Graphics Forum. Blackwell Publishing, Inc, 2004, 23(3): 615-624.
UE4就是利用这个技术进行遮挡查询的,这也是目前主流的遮挡剔除技术。
5.3 GPU Driven Rendering Pipeline
这个技术是未来发展的方向,现在gpu越来越强大,完全可以解放cpu去做更复杂的逻辑。我们如果可以把整个遮挡剔除技术,甚至是场景管理也放到gpu中去做,不仅可以解放cpu还可以进行更精准的剔除。这个技术主要依靠computer shader以及DrawIndirect / MultiDrawIndirect技术进行处理,后面文章再详细介绍。
6. PVS技术
这是个老技术,又是一个长寿的技术,因为它简单易用。简单的说pvs就是离线处理场景的信息,生成一个可见列表。我们根据玩家所在的cell查询可见列表,判断哪些物体可以看到。这个技术适合多房间的室内场景。PVS的离线处理也是遮挡剔除技术的应用。只不过这里是离线的遮挡剔除技术,比如光线追踪。这是一个空间换时间的算法,遮挡剔除的效果会非常快。
7. Portal Culling

看图大家就明白这个技术的原理了,就是通过视口对视锥体进行裁剪。在E房间的时候使用原始的视锥体进行渲染,渲染F房间的物体就需要使用被裁剪的视锥体进行渲染,这也是一种遮挡剔除的技术,这个技术是实时的。
版权声明:本文为CSDN博主(隐士低手)原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/liran2019/article/details/106940169





