目标检测是计算机视觉领域中一个新兴的应用方向。
目标定位
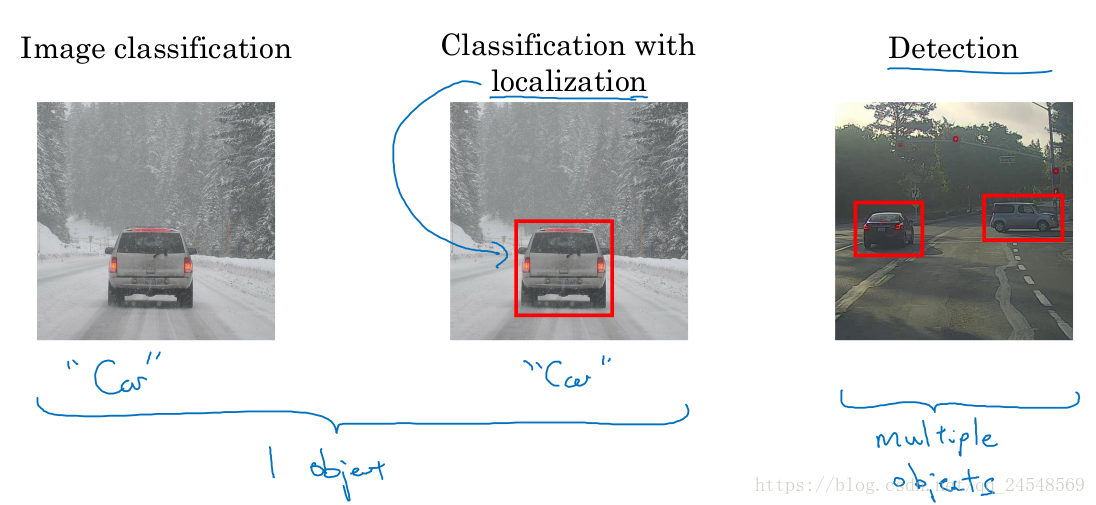
图像分类是对图像进行分类,比如判断图像中是否是车。定位分类不仅要图片分类,而且需要确定目标在图像中的哪个位置。目标检测中要识别的对象不仅仅只有一个,目标检测要识别图像中多个对象。
自动驾驶需要用到目标检测技术。给出一张汽车行驶中的图片
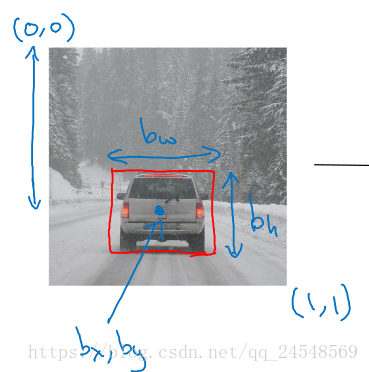
我们需要判断图中1-是否有行人,2-是否有车,3-是否有摩托车,4-图片是否只是背景图,还需要判断图中汽车的位置。设图片左上角的坐标是(0,0),右下角坐标为(1,1)。图中汽车的中心点位置大概为(bx=0.5,by=0.7),汽车的长和高分别是bw=0.3和bh=0.4。我们训练的神经网络就要有两种类型的输出,一种是4种对象的检测,另外一种是车的位置信息。
我们定义这张图片的标签y要包含下面几个元素
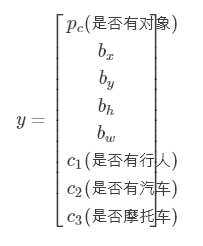
如果图片中有任意的对象,比如上图,那么
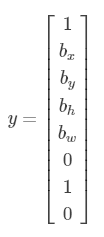
如果图片中什么都没有,那么
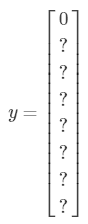
其中第一个元素置为0,其它元素可以不用设置,因为都没有任何对象了,我们不关心其它的信息了。
目标定位的损失函数是
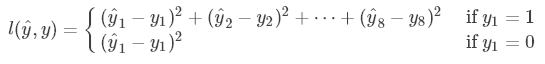
这里简单地使用了平方损失函数。
特征点检测
除了可以使用矩形框标出目标在图片中的位置,还可以使用特征点来表示目标的位置。
在人脸检测中,可以使用特征点来表示人脸的位置,或者具体的部位,比如眼睛,鼻子,嘴巴。

样本的标签y是一个坐标点的集合,第1个点表示左眼左侧眼角,第2个点表示左眼右侧眼角,第3个点表示右眼左侧眼角,以此类推。
特征点检测有许多应用场景。比如说AR,在人的头上显示一个皇冠,需要得到人脸的特征点位置,然后判断人脸的倾斜度,最后把皇冠“戴”到头上。
滑动窗体检测
为了从一幅大图中找出图中汽车的位置,需要用到活动窗体检测。首先使用汽车图片训练一个卷积神经网络,用于汽车分类。接着设置一个窗体,该窗体在大图上从上往下从左往右慢慢移动,每移动一步,把窗体截取的内容使用汽车分类器进行分类,如果检测到有汽车,说明图中的汽车位置在窗体的位置上。接着使用一个更大的窗体,重复上述步骤。
滑动窗体的移动步长设置大一些,可以减少汽车分类器的分类次数,但是可能会出现这种情况,窗体中的汽车只有车身的一部分,分类器不能识别,这样导致整个系统的性能降低。
把图片分成一块块区域,然后分别使用分类器分类,这样的滑动窗体的效率非常低。我们需要一个高效率的滑动窗体的方法。
首先要介绍把全连接层转成卷积层。
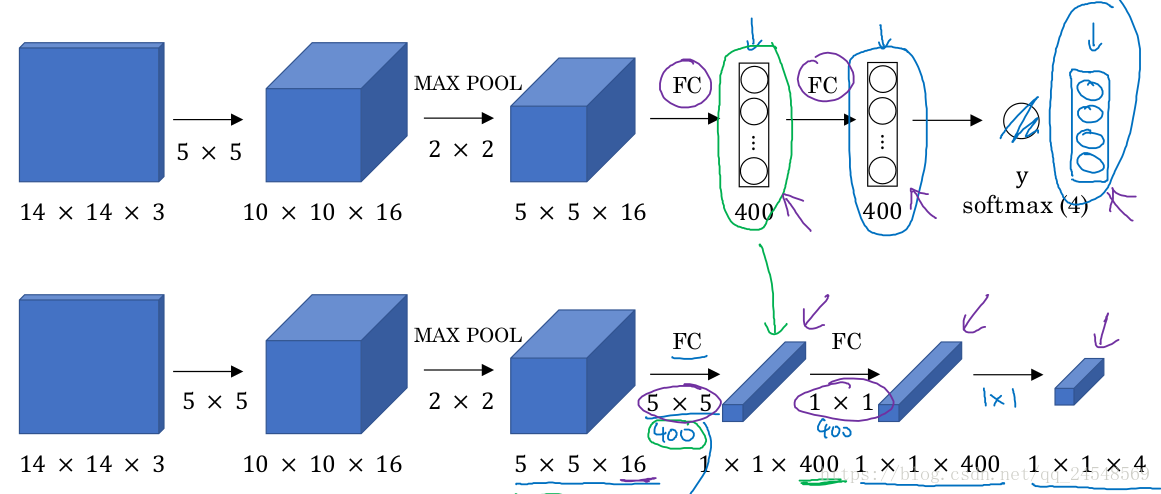
把上图的第一个全连接层,改成用5×5×16的过滤器来卷积,一次卷积的操作数是所有输入值,这相当于一次全连接,然后设置过滤器的数量为400,相当于计算全连接层的400个输出值。同理,把第二个全连接层改成用400个1×1×400的过滤器来卷积,得到的1×1×400输出就是第二个全连接层的输出。如此类推,最后得到1×1×4的输出就是softmax层的输出。
高效率的滑动窗体的方法是使用卷积来实现滑动窗体。
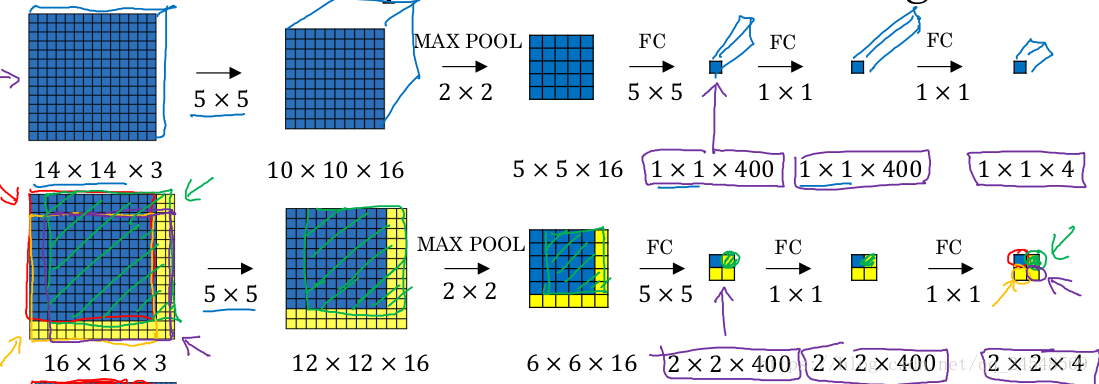
上图第一行表示一幅14×14×3的图片使用卷积网络进行分类的过程。其中全连接层使用卷积层实现。上图的下一行表示在一幅大图中实现滑动窗体的计算。首先只观察蓝色方块,这是一个滑动窗体,这个蓝色方块的大小满足上一行卷积网络的规格,把蓝色方块带入卷积网络,注意黄色区域也代入卷积网络中。最后2×2×4的蓝色块表示蓝色方块的分类结果。然后观察绿色框的区域,这是另外一个滑动窗体,你会发现卷积网络中绿色框的值就是绿色框区域在上一行卷积网络中的结果。把大图输入到卷积网络,卷积网络会同时计算大图的所有的相同大小滑动窗体的分类结果,这就加快了滑动窗体的分类效率。
Bounding Box 预测
滑动窗体检测对象的位置不是很精确,例如
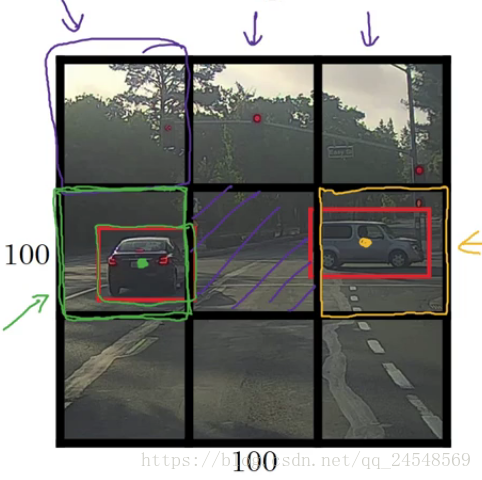
黑色框是滑动窗体分割的区域,在绿色框和黄色框中有汽车。直接把绿色框和黄色框作为图片中汽车的位置太粗略了,我们需要更加精确的汽车位置。这时可以使用到前面所说的目标定位的知识。
我们训练的分类器不仅仅要输出图片是否有汽车,还要输出汽车在图片中的位置(Bounding Box),所以可以使用目标定位使用的y,

把这张大图输入进卷积网络,最后得到的输出为3×3×8的矩阵,其中3×3代表滑动窗体,8表示每个滑动窗体的目标定位的8个预测结果。根据预测结果中的汽车位置信息,可以精确到汽车的具体位置。
这些方法来自YOLO算法。
交并比
交并比函数用于判断算法的定位预测是否正确。

红色框是正确的汽车位置,紫色框是预测的位置,交并比函数是指两者交集和并集的比。图中黄色区域指的是二者的交集,绿色区域指的是二者的并集,交并比函数公式是
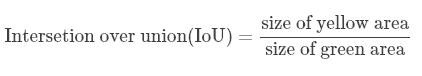
然后设置一个阈值,比如说0.5,如果IoU>0.5,则算法的定位预测没有问题。如果需要算法预测效果更加精确,阈值可以设置得更高。
非极大值抑制
滑动窗体检测有一个问题,就是一个对象可能会多次被检测到。例如

滑动窗体把图片分成19×19个区域,算法检测到绿色区域和黄色区域都有汽车。这几个区域都是汽车的一部分,它们组合起来,扩充更大的区域,才是完整的汽车。
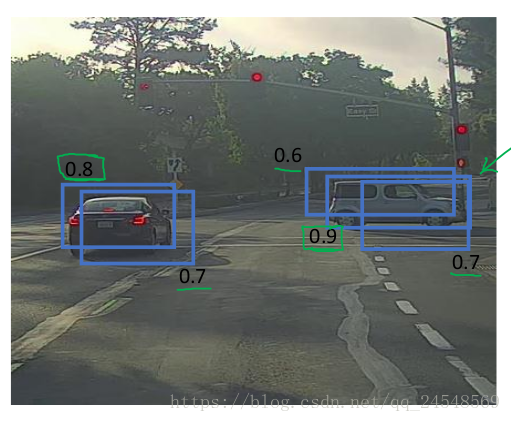
上图是一个物体被多次检测到的情况。非极大值抑制会清除多余的检测结果,比如,保留上图中pc值最高的两个(0.8和0.9)检测结果。
非极大值抑制算法的具体过程如下。
每个滑动窗体输出的预测值的形式是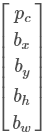 。
。
首先设置一个IoU阈值,比如0.5和一个概率阈值(置信度),比如0.6,清除所有 pc<0.6 的窗体。
如果还有剩下的窗体,执行下面的循环:
选择pc值最大的输出作为预测结果。
清除所有剩下的与前一步选择的窗体IoU>0.5的窗体。
Anchor boxes
上述所说的都是一个窗体检测一个对象,现在了解一下一个窗体同时检测多个对象的情况。如果两个物体对象同时出现在一个窗体中,它们的中心点位置相同,需要算法能够同时识别这两个物体对象。

上图中行人和车的中心点都在同一个位置,之前所说的算法只能检测到一个对象,因此需要修改算法。
图中的行人和汽车的形状不同,行人的矩形框比较长,汽车的矩形框比较宽,定义这些矩形框叫Anchor box,如下图所示

为了能够同时检测到Anchor box1和Anchor box2,需要修改标签y。本来y只有8个元素,现在y有16个元素,前8个元素用来输出Anchor box1的位置,后8个元素用来输出Anch box2的位置。pc表示对应的对象是否存在。
上图的标签y是下图的中间向量

如果行人离开的图片中,那么y值变为上图的右边向量。因为行人不在图片中,Anchor box1的位置信息就没有意义了,用?表示。
YOLO算法
现在来简单介绍YOLO算法的整个过程。
有一个例子是检测图片中的行人、汽车和摩托车。我们的算法主要检测行人和汽车,因此使用两个Anchor box。每个窗体的标签值y就如同下图所示,有16个元素,一半用来记录行人的位置信息,另一半用来记录汽车的位置信息。
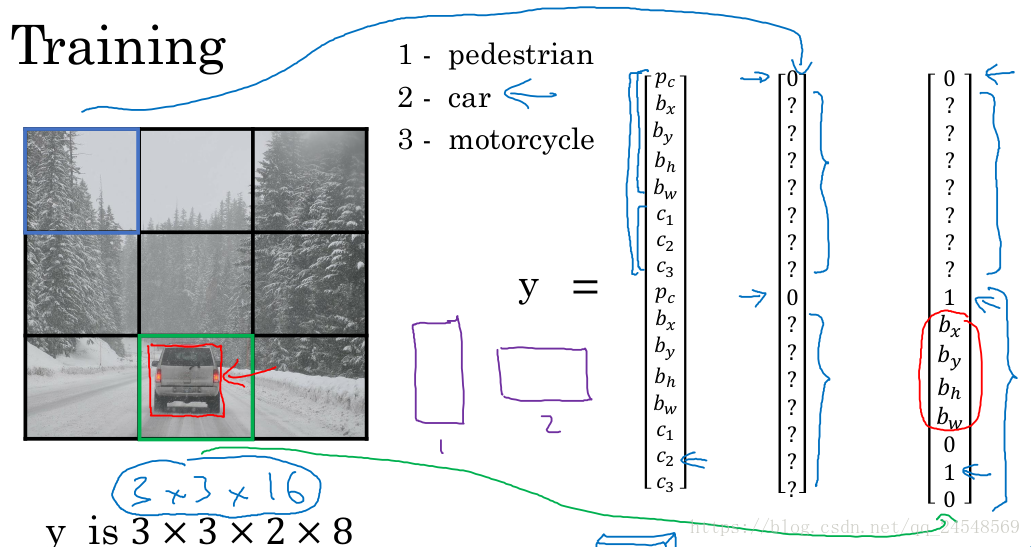
我们使用3×3的滑动窗体,不过一般使用更小的滑动窗体,比如19×19。训练出来的卷积网络最后输出的预测值大小是3×3×16。
对一张图片进行检测,每个窗体都会检测到两个位置信息,如下图。对象的边界的方框可能会超出窗体。

先把低于概率阈值的位置信息去掉

接着,对每个类别(行人和汽车),使用非极大值抑制算法来确定最终的位置。

R-CNN
R-CNN(带区域的CNN)提出了候选区域(Region proposal)的概念。R-CNN认为滑动窗体有时会检测什么对象都没有的区域,这会浪费时间,比如在下图的两个蓝色区域,是没有行人或汽车出现,对这两个区域进行卷积运算会降低系统的效率。

R-CNN对图片进行图片分割,得到一幅图片的区域图

不同的颜色块代表图片的不同区域,这些颜色块可以作为候选区域,R-CNN认为这些区域可能含有我们的目标对象,直接检测这些候选区域比检测所有的滑动窗体要快。
实际上R-CNN比YOLO要慢一些,但是R-CNN的思想值得借鉴。R-CNN自发表出来,已经有速度更快的版本。
R-CNN:最初的R-CNN算法,一次只对一个候选区域进行分类,输出的是label和bounding box(是否有对象和对象的位置)。
Fast R-CNN:使用滑动窗体的卷积实现来对所有的候选区域进行分类。
Faster R-CNN:使用卷积网络来获取候选区域。
版权声明:本文转自CSDN(叫什么就是什么),遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/qq_24548569/article/details/81177007





