最近学习吴恩达教授的一些课程,其中提到解决过拟合的四种方法。我们从易到难逐一讨论:
1. 增加训练集
通常training set不是很丰富的情况下,更容易出现过拟合状况。但是label更多的数据也不是能够快速达成的事情。因此这个方法主要适合于图像识别领域,可以通过distortion人为的增加训练集,从而减轻overfitting。
2. Early stop
这个比较容易理解,训练的越久,training set error是越来越小了,但是|W|值会越来越大,这样就会导致test set error变大,overfitting变得严重。如果你仔细观察过误差曲线,应该会记得elbow现象,选择那个时机的参数是比较合适的。所以并不是training set的误差越小越好。
3. L2正则化
L2正则化的原理是尽量让W变小些,所以每次迭代的时候W再减去自身的一个比例,这样就可以抑制它的快速变化(正数时候的变大或者负数时候的变小)。这里肯定会有人问:既然有L2正则化,为什么不用L1正则化?原因很简单:L1正则化会导致很多w值的最优解为0。我相信很多人对此有疑问,课程里面也没有详细展开。所以下面我们就来详细探讨下为什么会是这样的结果。
首先如果采用L1正则化,那么公式应该改写为:
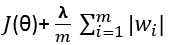
我们假设只有一个w系数,画一个二维的损失函数曲线作为例子。那么最有可能出现下图这样的情况,用了L1正则化后,损失函数的极值出现在了w=0这个点上。
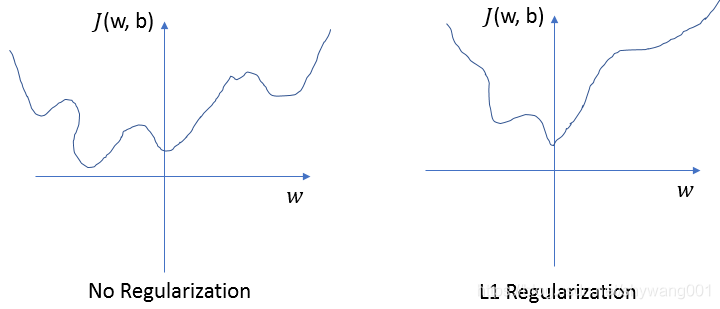
因为出现这种情况只需要满足,J(theta)’- lambda/m<0, 这样在W=0的左右两边,导数符号相反,根据梯度下降原理,它自动就会找到W=0这个点作为最优解。

4. Dropout
这个原理比较简单,就是随机去掉一些个神经元,通常input那一层是不动的,否则不是白搞了那么多feature了。
典型的 Inverted dropout,不影响prediction的方法,只是在做training时候按概率dropout,但是要记得对每一个神经元的输出进行反比例放大,这样不至于因为少掉一些神经元而导致往后传的数值发生很大的变化。
版权声明:本文为 CSDN博主shywang001 原创文章,
遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/shywang001/article/details/93720748





