作者:Jacob Solawetz
编译:ronghuaiyang
导读
在计算机视觉中,检测小目标是最有挑战的问题之一。本文给出了一些有效的策略。

为了提高你的模型在小目标上的性能,我们推荐以下技术:
- 提高图像采集的分辨率
- 增加模型的输入分辨率
- tile你的图像
- 通过增强生成更多数据
- 自动学习模型anchors
- 过滤掉无关的类别
为什么小目标检测很困难?
小目标问题困扰着世界各地的目标检测模型。不相信吗?查一下最近的模型在COCO上的评估结果,YOLOv3,EfficientDet和YOLOv4:
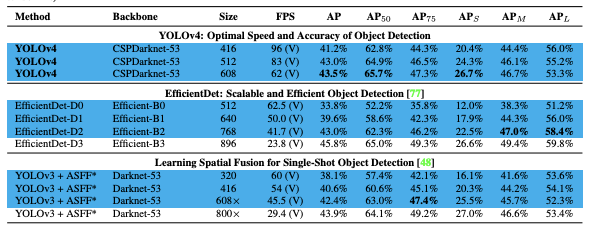
以Efficient为例,小目标的AP只有12%,大目标的AP为51%。这几乎是五倍的差异!那么,为什么检测小物体如此困难呢?
这一切都归结于模型。目标检测模型通过在卷积层中对像素进行聚合来形成特征。

在网络的末端,基于损失函数进行预测,损失函数根据预测值和ground truth之间的差异对所有像素进行加和。
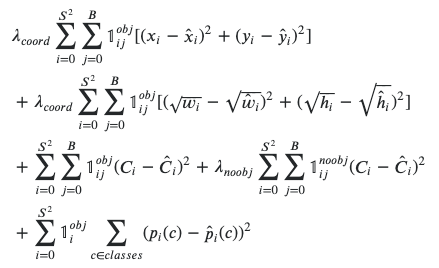
如果ground truth框不大,则在进行训练时信号会很小。此外,小物体最有可能有数据标记错误,他们的识别可能被忽略。
从经验和理论上讲,小物体是很难的。
提升图像采集的分辨率
分辨率,分辨率,分辨率……都是分辨率的锅。
非常小的物体的边界框中可能只包含几个像素,这意味着增加图像的分辨率可以增加探测器可以从那个小盒子中形成的丰富特征,这是非常重要的。
因此,我们建议尽可能提高采集图像的分辨率。
提高模型的输入分辨率
一旦你有了更高分辨率的图像,你就可以放大模型的输入分辨率。警告:这将导致大型模型需要更长的时间来训练,并且当你开始部署时,也会更慢地进行推断。你可能需要实验来找出速度与性能之间的正确权衡。
在训练YOLOv4中,你可以通过改变配置文件中的图像大小来轻松缩放输入分辨率。
[net]
batch=64
subdivisions=36
width={YOUR RESOLUTION WIDTH HERE}
height={YOUR RESOLUTION HEIGHT HERE}
channels=3
momentum=0.949
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue = .1
learning_rate=0.001
burn_in=1000
max_batches=6000
policy=steps
steps=4800.0,5400.0
scales=.1,.1你也可以在训练YOLOv5中通过改变训练命令中的图像尺寸参数来轻松缩放你的输入分辨率:
!python train.py --img {YOUR RESOLUTON SIZE HERE} --batch 16 --epochs 10 --data '../data.yaml' --cfg ./models/custom_yolov5s.yaml --weights '' --name yolov5s_results --cache对图像进行Tiling
检测小物体的另一个重要策略是将图像切割后形成batch,这个操作叫做tile,作为预处理步骤。tile可以有效地将检测器聚焦在小物体上,但允许你保持所需的小输入分辨率,以便能够运行快速推断。
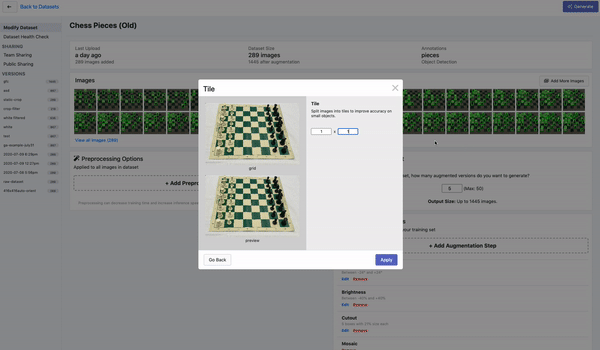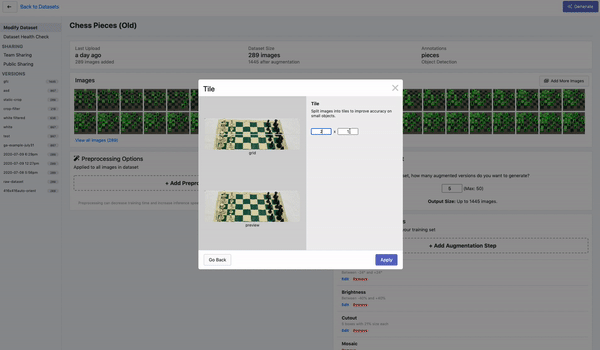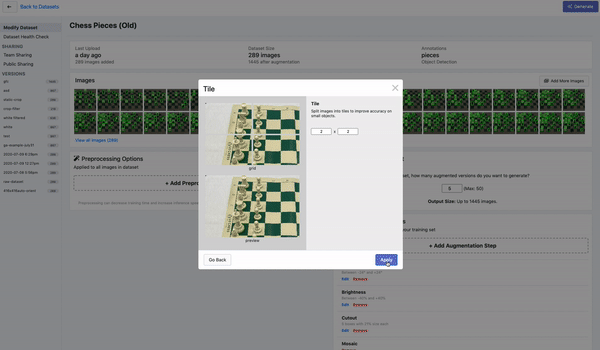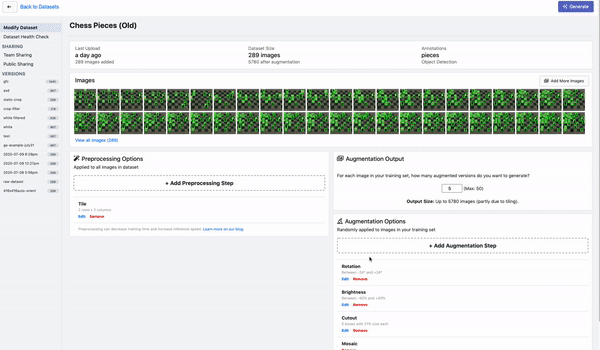
如果你在训练中使用tile,重要的是要记住,你也需要在推理时tile你的图像。
通过增强产生更多数据
数据增强从基本数据集生成新的图像。这对于防止模型过拟合训练集非常有用。
一些特别有用的小物体检测增强包括随机裁剪、随机旋转和马赛克增强。
自动学习模型Anchors
Anchors是你的模型学会预测的与之相关的原型边界框。也就是说,anchors可以预先设置,有时对你的训练数据不是最优的。最好根据你手头的任务自定义调优它们。幸运的是,YOLOv5模型会根据你的自定义数据自动为你完成这项工作。你所要做的就是开始训练。
Analyzing anchors... anchors/target = 4.66, Best Possible Recall (BPR) = 0.9675. Attempting to generate improved anchors, please wait... WARNING: Extremely small objects found. 35 of 1664 labels are < 3 pixels in width or height. Running kmeans for 9 anchors on 1664 points... thr=0.25: 0.9477 best possible recall, 4.95 anchors past thr n=9, img_size=416, metric_all=0.317/0.665-mean/best, past_thr=0.465-mean: 18,24, 65,37, 35,68, 46,135, 152,54, 99,109, 66,218, 220,128, 169,228 Evolving anchors with Genetic Algorithm: fitness = 0.6825: 100%|██████████| 1000/1000 [00:00<00:00, 1081.71it/s] thr=0.25: 0.9627 best possible recall, 5.32 anchors past thr n=9, img_size=416, metric_all=0.338/0.688-mean/best, past_thr=0.476-mean: 13,20, 41,32, 26,55, 46,72, 122,57, 86,102, 58,152, 161,120, 165,204
过滤掉无关的类别
类别管理是提高数据集质量的一项重要技术。如果你有一个类与另一个类明显重叠,你应该从数据集中过滤掉这个类。也许,你认为数据集中的小物体不值得检测,所以你可能希望将其拿掉。
总结
正确地检测小物体确实是一项挑战。在这篇文章中,我们讨论了一些策略来改善你的小物体探测器,即:
- 提高图像采集的分辨率
- 增加模型的输入分辨率
- tile你的图像
- 通过增强生成更多数据
- 自动学习模型anchors
- 过滤掉无关的类别
英文原文:https://towardsdatascience.com/tackling-the-small-object-problem-in-obje...
本文转自:AI公园(AI_Paradise),原作者:Jacob Solawetz,编译:ronghuaiyang,转载此文目的在于传递更多信息,版权归原作者所有。





