作者:Savaram Ravindra
来源:mindmajix.com
图像识别是非常有趣和具有挑战性的研究领域。本文阐述了卷积神经网络用于图像识别的概念、应用和技术。
什么是图像识别,为什么要使用它?
在机器视觉领域,图像识别是指软件识别人物、场景、物体、动作和图像写入的能力。为了实现图像识别,计算机可以结合人工智能软件和摄像机使用机器视觉技术。
虽然人类和动物的大脑很容易识别物体,但计算机在相同的任务中却遇到了困难。当我们看着像树木、汽车或朋友的东西时,我们通常不需要有意识地去学习后才能判断它是什么。然而,对于计算机,识别任何东西(无论是钟、椅子、人类或动物)都是一个非常困难的问题,并且为该问题找到解决方案的风险非常高。
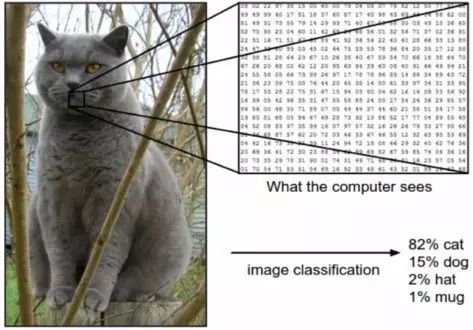
图像识别是一种机器学习方法,其设计类似于人类大脑的功能。通过这种方法,计算机可以识别图像中的视觉元素。通过依靠大型数据库和注意显露模式(emerging patterns),计算机可以理解图像,并制定相关的标签和类别。
图像识别的流行应用
图像识别有各种应用。其中最常见和最受欢迎的是个人图片管理。照片管理应用程序的用户体验正在通过图像识别变得越来越好。除了提供照片存储,应用程序还要进一步向人们提供更好的发现和搜索功能。他们可以通过机器学习提供的自动图像组织的功能来实现。集成在应用中的图像识别应用编程接口根据识别的图案对图像进行分类,并将它们进行主题分组。
图像识别的其他应用包括全景图库和视频网站、互动营销和创意活动、社交网络上的面部和图像识别以及具有巨大视觉数据库的网站的图像分类。
图像识别是一项艰巨的任务
图像识别不是一件容易的事情。实现它的一个好方法是,将元数据应用于非结构化数据。聘请人类专家手动标注音乐和电影库可能是一项艰巨的任务,但是当涉及无人驾驶汽车的导航系统,如将道路上的行人与各种其他车辆区分开来或过滤,分类或标记每天在社交媒体上显示的用户上传的数百万个视频和照片等挑战时,将变得遥不可及。
解决这个问题的一个方法是利用神经网络。我们可以利用传统的神经网络在理论上分析图像,但在实践中,从计算的角度来说,成本将是非常昂贵的。例如,一个普通的试图处理小图像的神经网络(让它变为30 * 30像素)仍然需要50万个参数和900个输入。一个功能强大的机器可以处理这一点,但是,一旦图像变得更大(例如达到500 * 500像素),则需要的参数和输入数量就会增加到非常高的水平。
与图像识别神经网络的应用相关的另一个问题是过度拟合。简单来说,过度拟合发生在模型裁剪本身与其已经被训练的数据非常接近的时候。一般来说,这将导致附加参数(进一步增加计算成本)和模型对新数据的暴露导致一般性能下降。
卷积神经网络
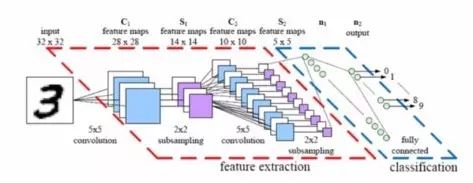
就神经网络的结构而言,一个相对简单的变化可以使更大的图像更易于管理。结果就是我们所说的CNN或ConvNets(卷积神经网络)。
神经网络的一般适用性是其优点之一,但是这种优势在处理图像时变成了一种妨碍。卷积神经网络进行有意思的权衡:如果一个网络是专门为处理图像而设计的,那么为了更可行的解决方案,必须牺牲一些一般性。
如果你考虑任何图像,接近度与其中的相似性具有很强的相关性,并且卷积神经网络明确利用了这一事实。这意味着在给定图像中,彼此更接近的两个像素更可能与彼此分开的两个像素相关。然而,在一般的神经网络中,每个像素都都与每一个神经元相连。增加的计算负荷使得网络在这种情况下不太准确。
通过停止很多这些不太重要的连接,卷积解决了这个问题。在技术术语中,卷积神经网络使得图像处理可以通过邻近度对连接进行滤波而计算可管理。在给定层中,卷积神经网络不是将每个输入连接到每个神经元,而是有意限制了连接,使得任何一个神经元仅从它之前的层的小部分接受输入(例如5 * 5或3 * 3像素)。因此,每个神经元只负责处理图像的某一部分(顺便说一句,这几乎是个体皮质神经元在大脑中的作用,每个神经元只对整个视野的一小部分起反应)。
卷积神经网络的工作过程
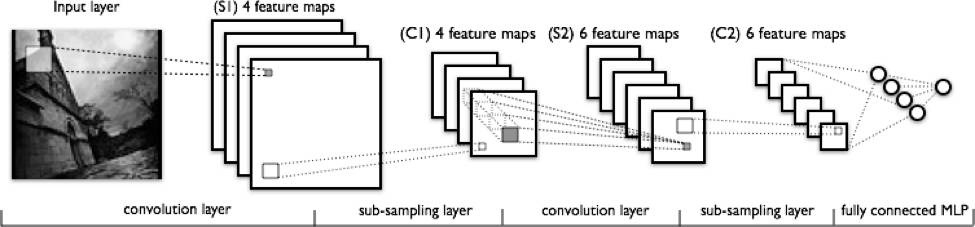
在上图中从左到右,你可以观察到:
- 对特征进行扫描的真实输入图像。通过它的过滤器是光矩形。
- 激活映射被安排在一个堆栈的顶部,另一个用于你使用的每个筛选器。较大的矩形为要进行下采样的1补丁。
- 激活图通过下采样进行压缩。
- 通过将过滤器通过堆栈进行下采样生成的一组新的激活映射。
- 第二次下采样——将第二组激活图压缩。
- 完全连接层,每个节点指定1个标签的输出。
CNN如何通过滤临近连接?秘密是添加了两种新的层:池化和卷积层。我们将以下述方式分解这个过程:使用一个被用于某种用途的,比如说,确定一张图片中是否包含祖父。
该过程的第一步是卷积层,其本身又包含几个步骤。
- 首先,我们将把祖父的图片分解成一系列重叠的3 * 3像素的拼图。
- 之后,我们将通过一个简单的单层神经网络来运行这些拼图,权重保持不变。将瓷砖排列组合,当我们保持每个图像尺寸是小的(在这种情况下为3 * 3)时,神经网络需要处理它们保证可控与小型化。
- 然后,将以数字表示照片中每个区域的内容的数组进行输出值排列,其中坐标轴表示颜色,宽度和高度。所以,对于每个拼图,在这种情况下,我们将有一个3 * 3 * 3的表示。(如果我们谈论祖父的视频的话,我们会抛出第四个维度——时间)。
- 下一步是池化层。它采用这些3或4维阵列,并与空间维度一起应用下采样功能。结果是一个池数组,其中仅包含重要的图像部分,同时丢弃剩余部分,这最大限度地减少了需要完成的计算量,同时也避免了过度拟合问题。
采用下采样阵列作为常规全连接神经网络的输入。由于使用池和卷积,输入的大小已经大大降低了,所以我们现在必须拥有普通网络能够处理的一些东西,同时保留最重要的数据部分。最后一步的输出将代表系统对于祖父图片的确信度。
在现实生活中,CNN的工作过程错综复杂,涉及许多隐藏、池化和卷积层。除此之外,真正的CNN通常涉及数百或数千个标签,而不仅仅是单一标签。
如何构建卷积神经网络?
从零开始构建CNN可能是一项昂贵而耗时的工作。话虽如此,人们最近开发了一些API,旨在使不同组织能够收集不同的见解,而无需自己研究机器学习或计算机视觉专业知识。
谷歌 Cloud Vision
GoogleCloud Vision是谷歌的视觉识别API,并使用REST API。它基于开源的TensorFlow框架。它检测单个面部和物体,并包含一个相当全面的标签集。
IBM沃森视觉识别
IBM沃森视觉识别是沃森开发者云(Watson Developer Cloud)的一部分,并附带了一大批内置的类别,但实际上是为根据你提供的图像来训练自定义定制类而构建的。它还支持一些很棒的功能,包括NSFW和OCR检测,如Google Cloud Vision。
Clarif.ai
Clarif.ai是一个新兴的图像识别服务,也使用REST API。关于Clarif.ai的一个有趣的方面是它附带了一些模块,有助于将其算法定制到特定主题,如食物、旅行和婚礼。
尽管上述API适用于少数一般应用程序,但你可能仍然需要为特定任务开发自定义解决方案。幸运的是,许多库可以通过处理优化和计算方面来使开发人员和数据科学家的生活变得更加容易,从而使他们专注于训练模型。有许多库,包括Theano、Torch、DeepLearning4J和TensorFlow已经成功应用于各种应用。
卷积神经网络的有趣应用
自动将声音添加到无声电影
为了匹配无声视频,系统必须在此任务中合成声音。该系统使用千个视频示例进行训练,用鼓棒击打不同的表面,产生不同的声音。深度学习模型将视频帧与预录音的数据库相关联,以选择与场景中发生的完全匹配的声音。然后系统将借助于类似于图灵测试的设置进行评估,人们必须确定哪个视频具有假(合成)或真实的声音。这是卷积神经网络和LSTM循环神经网络中非常酷的应用。
声明:部分内容来源于网络,仅供读者学习、交流之目的。文章版权归原作者所有。如有不妥,请联系删除。





