本文档覆盖了开发人员需要遵循的主要原则,以避免图形应用程序产生严重的性能问题。这些建议来自PowerVR技术支持团队。
注意,不同GPU,不同驱动,具有不同的性能特征。性能优化应该是一个不断分析profiling和实验的过程。
1. 了解目标设备
尽可能多地了解目标平台的信息,以便理解不同的图形架构,以尽可能有效的方式使用设备。
可以在设备制造商的网站查找规范,包括可用的社区开发资源。 PowerVR Graphics SDK提供的公开架构和性能建议文档供参考如下:
- PowerVR Hardware Architecture Overview for Developers
- PowerVR Series5 Architecture Guide for Developers
- PowerVR Performance Recommendations
- PowerVR Low Level GLSL Optimisation
- PowerVR Instruction Set Reference
IMR(Immediate Mode Rendering) 立即渲染
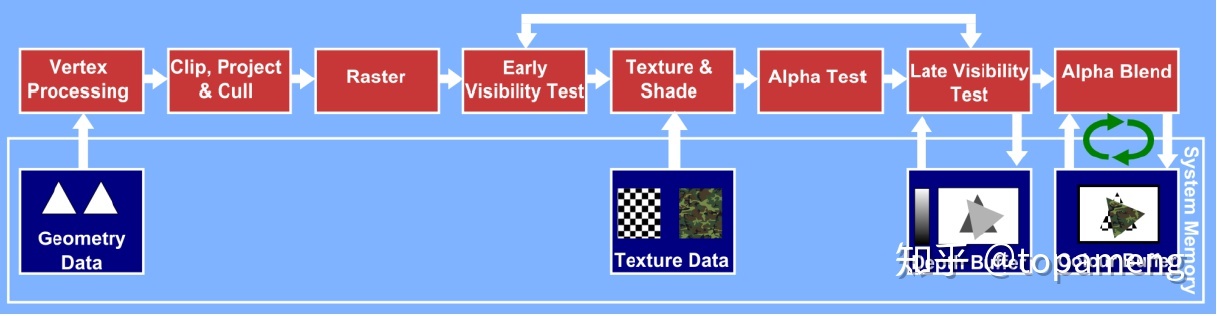
IMR:是将一个图元(通常是三角形),从头到尾走完整个管线Pipeline,中间不会停止。这种结构,控制简单,容易实现。但在做blending的时候需要从存储单元(显存)中回读之前渲染的结果(framebuffer)。写入每一个像素时需要读取depth/stencil缓冲区,不透明像素还需要写入depth/stencil缓冲区。而且渲染按照提交顺序直接执行,可能造成不可见物体也进行了渲染,造成overdraw浪费带宽和计算。可想而知在绘制一个复杂的大场景时带宽消耗是比较大的。
桌面GPU采用这个架构。是因为独立桌面GPU都有显存的,不需要通过系统总线从系统内存中读回数据。所以带宽开销比较小,是可以接受的。这些年GPU算力增长迅速, 而带宽增长缓慢,随着4K普及,桌面GPU带宽压力也在增大。也逐步产生了了一些基于tile的新渲染算法,如Forward+, tiled deferred lighting等,这里不做详述。
对于移动端的处理器(基本可以认为是ARM处理器)使用统一的内存存储空间寻址,这样读取depth/stencil缓冲区以及回读像素到GPU进行blending就变成了一件非常奢侈的事情。它会严重占用系统带宽,造成功耗提升,而且会影响整个系统芯片SOC的处理能力。
TBR(Tile Based Rendering)基于Tile的渲染
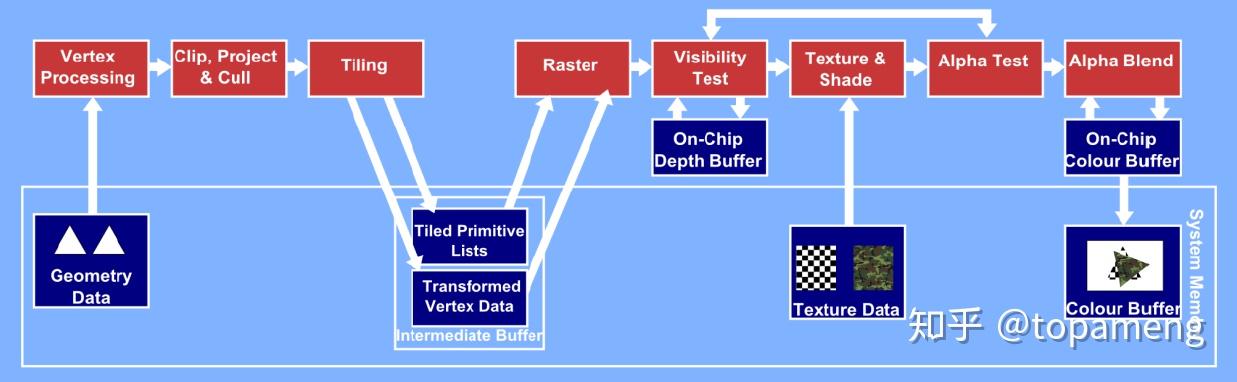
为了减少这种巨大的带宽需求。大部分移动GPU使用基于tile的渲染。将帧缓冲区framebuffer(包括深度缓冲区,多重采样缓冲区等)从内存移到高速片上on-chip缓存中。因为是片上的,更接近计算发生的地方(gpu芯片),访问它需要的功耗更少。但不幸的是,片上cache大小有限。通常片上tile缓冲区大小由GPU决定(通常32x32像素, 也可以小到16 x 16像素)。一旦完成tile的渲染,拷贝它到更耗电的主内存,仅仅需要回写最小的结果集合(颜色值):不需要写depth/stencil值。depth/stencil测试和(颜色)blending混合是完全在片上进行的。
TBR不再以图元primitive为单位,不像IMR那样执行完顶点着色器后立刻执行片段着色器。而是以rendertarget为单位,在一个rendertarget处理过程中,把所有提交的图元执行完顶点着色器之后,写回主内存,再进行光栅化,之后再执行片段着色器。我们将这些收集的中间数据称为frame data。一般这些数据的读取和写入使用的带宽比tile节省的带宽小的多。如果三角形数量超多会导致frame data膨胀,以及复杂的顶点shader, 都会抵消tile GPU的优势。
尽管相对IMR,TBR架构节省了带宽,但它并没有在渲染上减少overdraw。当渲染每个tile时,按照提交顺序处理几何体,如果一个不可见物体顺序靠前,几何体数据就会被处理,并且产生片段fragment,并为之提取纹理数据(浪费带宽),执行片段着色(浪费计算)。所以为了更好的利用Eayly-Z技术减少overdraw。应用程序需要从前到后排序不透明几何体再提交。让更靠近摄像机的不透明物体优先渲染。
大部分安卓属于TBR架构,但Mail上有Forward Pixel Kill(正向像素剔除)技术可以将通过early-z未进行片段渲染之前的像素剔除掉。当然安卓上还有Adreno,它处理overdraw最差。所以unity在安卓上对排序不透明物体也进行了排序
TBDR(Tile-Based Deferred Rendering)基于tile的延迟渲染
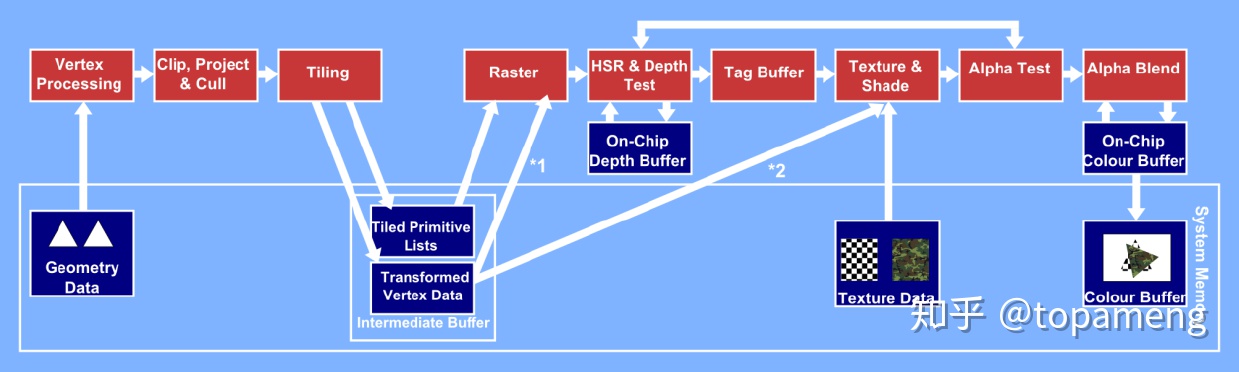
TBDR架构实现了TBR不具备的提交顺序无关的像素级隐藏面消除功能。HSR通过使用Tag Buffer跟踪可视的片段及其所属的图元,来高效消除不透明物体渲染的overdraw。也减少硬件提取片段着色所需数据(包括纹理数据和中间缓冲数据intermediate buffer data)浪费的系统内存带宽。 因为在HSR阶段只从frame data提取*1 position数据。其他几何体数据延迟到管线的*2阶段提取,所以也节省了中间缓冲数据消耗的带宽。
负责逐tile隐藏面消除功能模块称为ISP(图像合成处理器Image Synthesis Processor)
TSP(Texture and Shading Processor纹理和着色处理器)。
ISP 按tile逐个处理显示列表中的所有三角形。计算三角形方程。如果启动了深度测试,为tile上图元覆盖的每个片段获取深度信息,将计算的深度信息与tile片上深度缓冲区记录的值对比来决定片段是否可见。可见则更新片上深度缓冲区和tag buffer(tag buffer记录。直到处理完所有三角形,ISP 按组向TSP提交属于同一图元的片段,这样同时处理的片段属于同一图元。可以提升硬件的cache命中率。
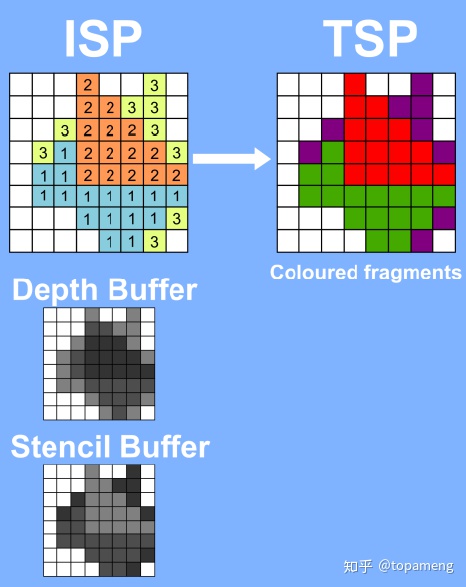
而本文主要针对PowerVR TBDR架构做性能建议。
在完全理解了图形架构之后,了解其他因素也很重要,例如CPU处理能力,内存带宽和温度负荷也会影响应用程序的性能。
2. 对应用程序进行分析Profiler
定位应用程序的瓶颈,并确定是否有改进的可能。
在尝试优化应用程序之前,了解性能瓶颈的位置非常重要。这样可以确保不浪费精力,也不会牺牲视觉质量以获得最小的收益。如果针对非性能瓶颈区域不适当地执行优化,则可能不会有性能提升。在某些情况下,错误的优化可能会导致性能下降。从PowerVR开发技术团队的经验来看,我们得出以下常见瓶颈列表,这些瓶颈通常存在于未经优化的应用程序中,从常见到不常见排序:
- CPU占用率
- 带宽使用率
- CPU/GPU同步
- 片段着色器指令
- 几何体上传
- 纹理上传
- 顶点着色器指令
- 几何体复杂度
在此过程中,分析工具至关重要,方便开发人员了解应用程序正在发生的事情,运行的硬件以及瓶颈的发生方式和位置。 可以使用分析工具PVRTrace和PVRTune
3. 不要使用不必要的Alpha Blend
确保在必要时才使用Alpha Blending,(减少Alpha Blending才能)充分利用硬件延迟架构并节省带宽。
尽可能关闭alpha blending, 如果需要透明对象,尽量将透明对象数量保持最小。这背后的原因是延迟渲染器(如PowerVR图形核心)在调用片段着色器处理片段之前,先计算片段的可见性。这样可以防止不可见片段被(不必要地)处理并输出到图像。如果开启了alpha blending, 则用于确定片段可见性的硬件HSR将无法使用。这是因为被alpha-blend片段遮挡的片段可能会影响最终的渲染图像。因为这种行为,启动alpha blending消除了延迟渲染图形架构的好处。这意味着硬件不再能够决定片段的可见性并将其(不可见的片段)从管线中删除。这可能会导致过度绘制overdraw(即正在处理的片段在最终图像上实际不可见)。overdraw会对应用程序性能产生负面影响,特别是处于渲染瓶颈的应用程序。
尽量分离Alpha=1不透明颜色的部分。
在立即模式GPU上,混合Blending通常比较昂贵,因为它需要在帧缓冲区framebuffer上完成一个读取-修改-写入的循环。而帧缓冲区framebuffer保存在相对较慢的内存中。
在基于tile的GPU上,这个读取-修改-写入循环完全在片上完成,因此消耗非常小。一些GPU拥有专用的Blending硬件,这让混合操作变得基本上免费。
之上所述的性能耗费,主要指Alpha blending带来的影响,而不是指像素上的alpha操作。
4. 执行Clear
在基于tile的图形架构上,清除帧缓冲区的内容,可以避免取回前一帧的frame data,从而减少内存带宽。
访问系统内存比其他图形操作耗费更多的带宽,带来更大的功耗。将内存访问保持在最低限度,可以降低应用程序产生内存带宽瓶颈的机率,并且可以降低应用程序的功耗。
大多数应用程序需要在渲染结束时生成图像,但不需要在帧之间保留深度和模板数据。如果不需要在渲染结束时保留帧缓冲区附件framebuffer attachments,则可以使相应的帧缓冲附件无效,防止它们被写入系统内存。
在新一帧开始时,很少有应用程序需要保留之前颜色缓冲区的内容。因此,如果不需要之前的帧缓冲器的内容。在渲染开始时通过清除操作,避免驱动程序将它们从系统内存加载到片上tile内存中。
执行清除并且废弃帧缓冲区的最终结果是:大幅减少系统内存带宽占用并降低功耗。
在OpenGL ES中,当渲染开始时,通过调用glClear函数来执行清除操作。另外,在渲染结束时,glDiscardFramebufferEXT或glInvalidateFramebuffer函数可用于废弃帧缓冲区。
Vulkan API可以显式控制帧缓冲区附件的加载和存储操作。在创建帧缓冲区时,将加载操作设置为VK_ATTACHMENT_LOAD_OP_DONT_CARE 或者 VK_ATTACHMENT_LOAD_OP_CLEAR。存储操作设置为VK_ATTACHMENT_STORE_OP_DONT_CARE,除非要保留数据。
5. 不要在帧中间更新数据缓冲区
修改GPU当前使用的(in-flight)资源(例如顶点缓冲区和纹理)有显着的成本。移动图形处理器往往有一帧的延迟latency,以确保硬件能够被充分利用。因此,更改未完成的渲染所需资源,通常会导致执行一下操作:
- 在api调用时修改缓冲区会挂起stall CPU, 直到未完成的渲染完成。
- 为新数据分配一个临时缓冲区,这样缓冲区修改api调用就可以完成,而不会挂起CPU线程。

由于纹理通常在片段着色期间访问,在图形管线中比访问顶点属性更晚,因此纹理修改(导致图形驱动程序挂起的)成本高于修改顶点缓冲区。为了性能,驱动程序可以选择通过创建临时缓冲区(例如ghosting)来避免挂起stall。但对于缓冲区存储空间用完的应用程序,无法这么做。对于不同的GPU和驱动程序,图形处理器采用挂起stalling还是ghosting也会有变化。为了获得最佳性能,仅在绝对必要时修改顶点缓冲区和纹理。如果必须修改缓冲区,可以在应用程序端使用循环缓冲区,这样当图形处理器可以读取一个缓冲区对象时,应用程序CPU线程也可以同时写入另一个。这样就可以防止stalling和ghosting行为。如果应用程序使用Vulkan 图形API, 那么应用程序开发人员有责任同步图形处理器。适当的机制如放置栅栏fences或者信号semaphores,以确保应用程序在图形处理器使用资源时不能访问它。这样可以更好的控制访问资源的方式和时间,但代价是更复杂的应用程序,因为驱动不能防范当前图形处理器使用的数据被访问。
6. 使用压缩纹理
减少纹理资源的内存占用和带宽成本
在某些情况下,需要考虑纹理大小和纹理压缩之间的平衡。可以使用更大的纹理和低比特率压缩方案,来实现带宽节省和可接受的图像质量之间的更好平衡。

不要与图像文件压缩混淆,纹理压缩目的是:减少运行时纹理占用的内存。这提供了几个性能优势,主要是减少了发送数据到图形核心系统时消耗的系统内存带宽。PVRTC和PVRTCII是PowerVR专有的压缩技术,在(PowerVR)硬件上能够获的最佳的性能,平均每个像素占用2个比特。压缩纹理的纹理缓存也很高效,因为较低的像素大小,允许更多的像素放入到有限大小的纹理单元缓存cache中(纹理单元并不是读取一个像素点,通常是一个块chunk)。对于PowerVR系列和图形目标,某些会支持额外的压缩纹理格式,如ASTC。
7. 使用mipmaping
这样能够提升纹理缓存效率,从而减少带宽占用提升性能
Mipmaps是纹理图像更小的预过滤变体,代表纹理的不同细节层次lod。使用mipmaps时,通过使用缩小过滤模式,图形核心可以设置为自动计算最接近细节层次,映射该mipmap的纹素到渲染目标像素pixels上。这意味着能够使用正确的mipmap来进行纹理映射
使用mipmap有两个重要的优点:
- 它通过大规模提高纹理缓存效率,来提升图形渲染性能,特别是在强烈缩小情况下-纹理数据更容易填充到tile内存。
- 它通过减少欠采样(没有mipmaping的)纹理引起的锯齿,提升图像质量。
mipmapping的唯一限制是需要大约每个图像多付出三分之一的纹理内存。根据具体情况,与渲染速度和图像质量相比,此成本可能较小。
有一些情况例外,应该避免使用mipmaps。
例如:
- 不能过滤的情况,如包含非图像数据纹理(如索引或者深度纹理)
- 从不缩小的纹理,如UI元素,它的每个纹素始终一对一映射到像素
理想情况下,应使用像PVRTexTool这样的工具来离线创建mipmap, PVRTexTool作为PowerVR Graphics SDK一部分提供。也可以实时产生mipmap,这对于渲染到纹理目标时更新mipmaps十分有用。在Opengl ES中,可以使用glGenerateMipmap函数实现。在Vulkan中没有这样的内置函数,开发人员必须手动生成mipmaps。对于压缩纹理不能在线生成mipmaps。如PVRTC必须离线生成mipmaps。必须考虑哪一个成本更合适:离线生成的存储成本,还是运行时生成mipmaps的运行时成本(以及在Vulkan情况下,增加的代码复杂性)
8. 不要使用Discard
避免在纹理阶段进行深度测试处理,因为在early-z架构上这会降低性能。
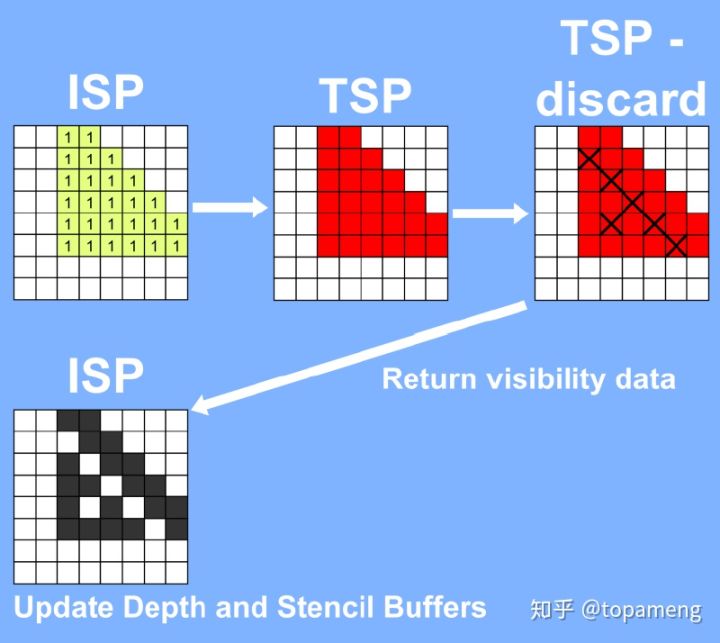
应用程序应避免在片段着色器中使用discard操作,因为使用它不会提升性能(如果丢弃区域很大,在pc上可以起到优化作用)。因为大部分移动图形核心使用基于tile的延迟渲染(TBDR)架构,使用discard会抵消这类架构的优点。应用程序应避免alpha test,与不透明图元不同,alpha test图元,在early depth testing(如PowerVR的隐藏面消除hsr,被更靠近摄像机片段遮挡的片段会被丢弃)管线阶段不能执行深度写入。直到片段着色器执行并且片段可见性已知之前,alpha test图元都不能将深度数据写入到深度缓冲区中。这些延迟的深度写入会影响性能,因为直到alpha test图元更新深度缓冲区,后续图元都不能被处理。
为了获得最佳性能,考虑使用alpha blending替代alpha test来避免延迟深度写入操作。为了确保HSR尽可能移除更多的overdraw,需要按如下顺序提交绘制:
- 不透明opaque
- alpha-tested
- blended
粗略情况,可以使用alpha blend并设置alpha为0代替discard操作。还需要对透明物体从前到后排序。注意alpha test物体一般是不需要排序的。因为dicard操作只发生在alpha小于阈值的像素上,这部分像素会因alpha blend受益,但如果大部分像素是作为不透明渲染的,这部分并不能受益反倒可能因overdraw而损失性能。而且很多时候因为透明排序问题导致无法简单替换。
如果保证渲染完全正确,就不能简单使用alpha blending替换alpha test,需要使用Z-Prepass渲染策略。首先使用包含discard逻辑的简单片段着色器(不包含光照计算等)来填充深度缓冲区,然后再次渲染场景,设置深度测试函数为GL_EQUAL,使用包含光照的shader来渲染,虽然多pass渲染会导致性能下降,但这种方法比单pass包含大量计算和discard操作的渲染方式性能更好。
如果渲染瓶颈在discard操作上可以采取Z-Prepass这种方式,但一般引擎是不会做设个假设的,对于TBDR移动架构也并不推荐Z-prepass(见后面对depth pre-pass的说明)。如果discard像素过多,也可以通过增加少量三角形减少需要discard区域(alpha值小于阈值区域)来优化,当然有时只是改变三角形形状就能达到缩小discard区域目的。

9. 不要强制不必要的同步
避免可能挂起stall图形管线的API功能,并且不要直接访问硬件缓冲区。
当CPU和图形核心任务并行运行时,图形应用程序可达到最佳性能。当一帧frame顶点处理任务与前一帧frame的片段着色任务并行时,图形核心也会最有效地运行。当应用程序发布导致图形核心中断的命令时,会显著的降低性能。
硬件调度任务最有效方式时保持顶点处理和片段任务能够并行。为了实现这一点,应用程序目标是尽可能移除导致CPu和图形核心同步的函数:
- 在OpenGL ES中,同步函数,如glReadPixels, glFinish, eglClientWaitSync和glWaitSync.
- 在Vulkan中,开发人员可以更好的控制资源的同步,因为图形处理器和CPU之间的任何同步都是开发人员定义的。
应用程序性能不佳的常见原因之一是:应用程序从CPU访问帧缓冲区内容。当发布这样的操作时,应用程序发起该调用的CPU线程会被挂起直到图形核心完成该帧缓冲区附件的渲染。当渲染完成之后,CPU才能开始从附件读取数据。在这期间,图形核心没有写入该附件的权限,这可能导致图形核心挂起stall对该帧缓冲区的后续渲染。由于成本高昂,这些操作应该在绝对必要时才使用—例如,当玩家请求捕获屏幕截图时
10. 从下向上移动计算
通过沿管线向上移动计算到处理更少实例的地方,从而减少计算的总数。
在管线中越早执行计算,就可以越多地减少整体操作的数量。也可以显著减少工作量。通常在场景中,顶点数量比需要处理的片段数量要少。这意味着逐顶点处理计算,相对于逐像素,可以大大减少计算量。
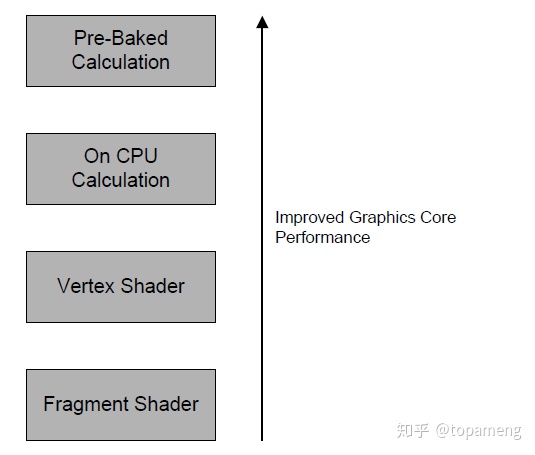
也可以考虑将计算从图形核心移除。虽然图形核心执行(计算)操作比CPU快得多,但相对于图形核心对很多顶点执行操作,CPU只执行一次操作就会更快。为了进一步理解这个概念,可以考虑通过烘培场景来执行离线计算,从而通过简单的查找替换昂贵的实时计算。例如,对场景中静态物体(如地形,建筑和树等)使用光照贴图代替实时光照。这大大提升了性能,并且在许多情况下,比运行时计算提供了更高的光照质量。
以unity举例,如果一个模型做uv动画,uv移动计算在CPU端要好于在顶点shader中计算,更好于在片段shader中计算。注意在CPU端是通过修改材质uv参数来做uv动画,而不是修改模型全部顶点数据的uv值。同样在后处理中在顶点计算一个值要比全屏像素中省的多
注意不是所有操作都能从片段着色移到顶点着色中,光栅化对顶点数据进行透视校正插值,只对线性变化的属性正确。所以在顶点中放入光照高光之类非线性计算结果是不对的。
其他因素
按材质分组
修改GL状态机会导致图形驱动的CPU开销,因为更改需要被解释并转换成可以发布到图形核心的任务。要减少这类开销,尽量减少API调用的数量以及应用程序端状态修改。
对于几何体数据,尽可能多的合并网格到一个绘制调用draw call中. 示例如下:
火车上的座位网格相对彼此具有独立的静态位置和方向,并使用相同的渲染状态。座位和火车可以组合成一个单一网格。绘制火车内部时,几个绘制调用合并为一个调用。按PowerVR硬件的隐藏面移除特性,(不透明物体)不需要按深度顺序提交几何体来减少overdraw。少了这个限制,应用程序可以专注基于渲染状态进行绘制排序,确保最小化状态修改。
与几何体数据类似,可以通过纹理图集或者纹理数组将多个纹理合并到一个单一绑定对象中。然后通过适当的着色器统一变量应用纹理到每个对象上。
如避免读取/写入正在使用的缓冲区对象中所讨论的那样,修改缓冲区数据可能导致图形管线停滞stall或者增加图形驱动程序分配的内存量。当合并绘制时,考虑缓冲区的更新频率很重要。例如,将具有静态顶点数据、空间连贯的物体合并到一个顶点缓冲区,将具有动态数据(如布料等软体对象)合并到另外一个顶点缓冲区中。
使用索引列表
图形驱动使用顶点缓冲区缓存顶点数据属性,如用于将2D图像映射到网格的纹理坐标,模型/空间位置等。对于不常更改顶点属性的静态对象,顶点缓冲区可以提升性能,因为缓存了可重用于多帧渲染的数据。
在上面的示例中,索引缓冲区和顶点缓冲区一起使用。索引缓冲区定义了顶点缓冲区元素访问的顺序以代表网格中的三角形。索引缓冲区可以提升性能并且缩减了复杂网格数据的存储空间。这是因为顶点属性只写入到顶点缓冲一次,然后根据需求被引用多次来表示围绕该顶点位置的三角形。PowerVR硬件针对三角形索引列表进行了优化,对于精细的性能调整,顶点和索引缓冲区应该进行排序来提升GPU访问数据时的缓冲效率。我们的3D场景导出和转换工具,PVRGeoPOD, 在产生POD文件时可以自动对网格数据进行排序。
使用所有的CPU核心
现代移动设备通常具有多个CPU核心,为了在现代CPU架构上获取最佳性能,应用程序尽可能使用多线程。例如,考虑在主线程上进行图形更新,同时在单独的工作线程上更新物理系统。通过拆分大量的工作如物理,动画,文件I/O等到多个线程,使应用程序更高效的使用CPU。通常可以带来更流畅的用户体验。如果应用程序使用Vulkan图形API,则可以拆分绘制命令的准备(构建command buffers)到多个线程
使用较低的数据精度
使用mediump修饰符声明的shader变量表示16位浮点数(FP16),应用程序在适当的地方都应该用FP16, 因为在理论上它的吞吐量是FP32(highp)的两倍, 从而显著提升了性能。通常使用FP32地方,需要提供足够的精度并且最大和最小值不会溢出,以致引入视觉瑕疵
使用细节层次(LOD)
细节层次是应用程序需要考虑的重要因素,这里应该采用“足够好”的概念。应用程序开发人员必须考虑昂贵的图形效果和高质量资源对性能的影响。
mipmaping是一种LOD形式,在规则7已经讨论过。LOD的第二种考虑因素是几何体复杂性。应该为每个对象或者对象一部分使用适当的几何体复杂度级别。
以下是浪费计算和内存资源的示例:
- 对于覆盖屏幕很小区域的对象使用大量的多边形,如远处的背景对象。
- 由于摄像机角度或者剔除,使用多边形增加的细节不可见- 例如视锥体外的对象。
- 对能够使用很少图元就能绘制的对象,使用了大量图元。例如,使用数百个多边形来渲染单个四边形。
考虑使用bump maping之类的着色器技术来减少几何体复杂度,仍然可以保持高层次的视觉细节。对于反射pass之类的技术尤其如此,在其中大量的几何体数据不可见
不要使用 depth pre-pass
在采用延迟渲染结构的图形硬件上,如PowerVR,应用程序不需要depth pre-pass,因为不会有性能收益。执行这个操作只会浪费时钟周期和带宽。因为在片段处理开始之前,在光栅化期间硬件会自动检测并从管线中移除被遮挡的(不透明)几何体。
使用片上内存进行高效延迟渲染
对于延迟光照之类的图形技术,通常需要附加多个颜色渲染目标到一个帧缓冲区对象,渲染所需的中间数据,然后做为纹理采样这些数据来实现。虽然灵活,但这种方法,即使经过优化,仍然会消耗大量的系统内存带宽,这对移动设备非常高昂。
OpenGL ES(3.x)和Vulkan图形API都提供了一种方法,通过片上on-chip缓冲区,实现了覆盖相同位置像素片段着色器之间的通信,这个缓冲区只能由相同像素坐标处的着色器调用读取和写入。
GLES扩展shader_pixel_local_storage(2)和Vulkan临时附件使应用程序能够将中间逐像素数据存储在片上tile缓存中,虽然每种方法都有自己的实现细节,但它们都提供了相似的功能和相似的收益。例如,延迟光照pass的“G-Buffer”附件仅需要一次,可以存储在tile缓存,然后再完成绘制后丢弃。
上述两种API特性对于基于tile的渲染器(如PowerVR图形核心)非常有益,因为它允许应用程序高效使用片上tile缓存。不需要分配中间缓冲区附件或者回写到系统内存-它们只存在于片上tile缓存中。这对内存带宽非常昂贵的移动和嵌入式系统非常有用。
正确使用这些功能能够显著降低系统内存带宽使用率。此外,对于大部分回写中间数据到系统内存,然后在相同像素位置采样的技术(例如延迟光照),都能使用这些API特性优化。
使用显式API
Vulkan 式新一代图形和计算API。它高效,精简和现代,目标是发挥当前和未来的设备架构优势。Vulkan适用于各种平台,如桌面PC,游戏主机,移动和嵌入式设备。
发布于 2019-11-27
来源:知乎 - topameng
原文链接:https://zhuanlan.zhihu.com/p/93998160





