一、本文的内容包括:
1. Batch Normalization,其论文:https://arxiv.org/pdf/1502.03167.pdf
2. Layer Normalizaiton,其论文:https://arxiv.org/pdf/1607.06450v1.pdf
3. Instance Normalization,其论文:https://arxiv.org/pdf/1607.08022.pdf
4. Group Normalization,其论文:https://arxiv.org/pdf/1803.08494.pdf
5. Switchable Normalization,其论文:https://arxiv.org/pdf/1806.10779.pdf
二、介绍
在介绍各个算法之前,我们先引进一个问题:为什么要做归一化处理?
神经网络学习过程的本质就是为了学习数据分布,如果我们没有做归一化处理,那么每一批次训练数据的分布不一样,从大的方向上看,神经网络则需要在这多个分布中找到平衡点,从小的方向上看,由于每层网络输入数据分布在不断变化,这也会导致每层网络在找平衡点,显然,神经网络就很难收敛了。当然,如果我们只是对输入的数据进行归一化处理(比如将输入的图像除以255,将其归到0到1之间),只能保证输入层数据分布是一样的,并不能保证每层网络输入数据分布是一样的,所以也需要在神经网络的中间层加入归一化处理。
BN、LN、IN和GN这四个归一化的计算流程几乎是一样的,可以分为四步:
1. 计算出均值
2. 计算出方差
3. 归一化处理到均值为0,方差为1
4. 变化重构,恢复出这一层网络所要学到的分布
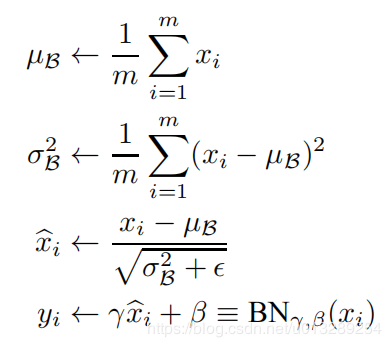
训练的时候,是根据输入的每一批数据来计算均值和方差,那么测试的时候,平均值和方差是怎么来的?
对于均值来说直接计算所有训练时batch 均值的平均值;然后对于标准偏差采用每个batch 方差的无偏估计
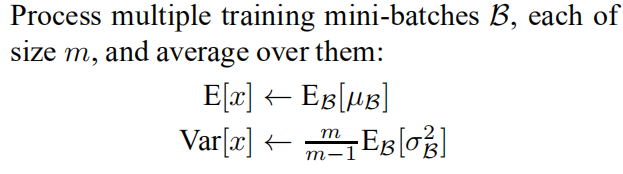
接下来,我们先用一个示意图来形象的表现BN、LN、IN和GN的区别(图片来自于GN这一篇论文),在输入图片的维度为(NCHW)中,HW是被合成一个维度,这个是方便画出示意图,C和N各占一个维度
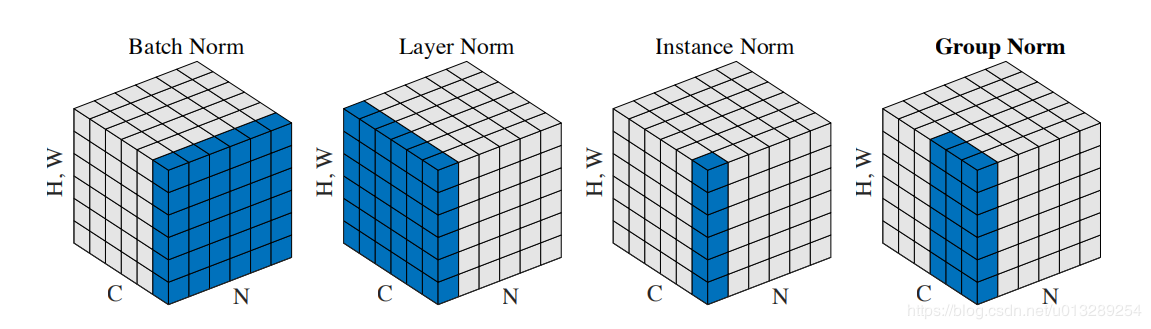
Batch Normalization:
1. BN的计算就是把每个通道的NHW单独拿出来归一化处理
2. 针对每个channel我们都有一组γ,β,所以可学习的参数为2*C
3. 当batch size越小,BN的表现效果也越不好,因为计算过程中所得到的均值和方差不能代表全局
Layer Normalizaiton:
1. LN的计算就是把每个CHW单独拿出来归一化处理,不受batchsize 的影响
2. 常用在RNN网络,但如果输入的特征区别很大,那么就不建议使用它做归一化处理
Instance Normalization
1. IN的计算就是把每个HW单独拿出来归一化处理,不受通道和batchsize 的影响
2. 常用在风格化迁移,但如果特征图可以用到通道之间的相关性,那么就不建议使用它做归一化处理
Group Normalization
1. GN的计算就是把先把通道C分成G组,然后把每个gHW单独拿出来归一化处理,最后把G组归一化之后的数据合并成CHW
2. GN介于LN和IN之间,当然可以说LN和IN就是GN的特列,比如G的大小为1或者为C
Switchable Normalization
1. 将 BN、LN、IN 结合,赋予权重,让网络自己去学习归一化层应该使用什么方法
2. 集万千宠爱于一身,但训练复杂
版权声明:本文为CSDN博主「时光碎了天」的原创文章,
遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u013289254/article/details/99690730





