过拟合是指在模型参数拟合过程中,由于训练数据包含抽样误差,复杂模型在训练时也将抽样误差进行了很好的拟合。具体表现就是在训练集上效果好,而测试集效果差,模型泛化能力弱。

解决过拟合的方法:
1. 从数据入手
解决过拟合最有效的方法,就是尽力补足数据,让模型看见更加全面的样本,不断修正自己。
数据增强:通过一定规则扩充数据。可以通过图像平移、翻转、缩放、切割等手段将数据库成倍扩充。当然,随着GAN的发展,很多任务,可以通过GAN来有效补足数据集。
2. 正则化

从上式,可以看到一个平方差误差函数加上一个正则化项。到底什么是正则化呢,从字面理解,其实就是给需要训练的目标函数加上一些规则限制。可以看到二次正则项的优势,处处可导,计算方便,可以限制模型复杂度,即模型中多项式函数的阶次,阶次越大,模型复杂弯曲程度越大,其中我们优化的参数W就是多项式前的系数,W趋向于0,说明模型越简单。我们单独看二次正则项,它的梯度方向可以把W向0引导。
2.1. dropout
Dropout可以作为训练深度神经网络的一种trick供选择。在每个训练批次中,通过忽略一半的特征检测器(让一半的隐层节点值为0),可以明显地减少过拟合现象。这种方式可以减少特征检测器(隐层节点)间的相互作用,检测器相互作用是指某些检测器依赖其他检测器才能发挥作用。
Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征,如下图所示。

代码层面实现让某个神经元以概率p停止工作,其实就是让它的激活函数值以概率p变为0。比如我们某一层网络神经元的个数为1000个,其激活函数输出值为y1、y2、y3、…、y1000,我们dropout比率选择0.4,那么这一层神经元经过dropout后,1000个神经元中会有大约400个的值被置为0。
注意: 经过上面屏蔽掉某些神经元,使其激活值为0以后,我们还需要对向量y1……y1000进行缩放,也就是乘以1/(1-p)。如果你在训练的时候,经过置0后,没有对y1……y1000进行缩放(rescale),那么在测试的时候,就需要对权重进行缩放
为什么说Dropout可以解决过拟合?
(1)取平均的作用: 因为不同的网络可能产生不同的过拟合,取平均则有可能让一些“相反的”拟合互相抵消。dropout掉不同的隐藏神经元就类似在训练不同的网络,随机删掉一半隐藏神经元导致网络结构已经不同,整个dropout过程就相当于对很多个不同的神经网络取平均。而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。
(2)减少神经元之间复杂的共适应关系: 因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况 。迫使网络去学习更加鲁棒的特征 ,这些特征在其它的神经元的随机子集中也存在。换句话说假如我们的神经网络是在做出某种预测,它不应该对一些特定的线索片段太过敏感,即使丢失特定的线索,它也应该可以从众多其它线索中学习一些共同的特征。从这个角度看dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高。
dropout为什么进行缩放
因为我们训练的时候会随机的丢弃一些神经元,但是预测的时候就没办法随机丢弃了。如果丢弃一些神经元,这会带来结果不稳定的问题,也就是给定一个测试数据,有时候输出a有时候输出b,结果不稳定,这是实际系统不能接受的。那么一种”补偿“的方案就是每个神经元的权重都乘以一个p,这样在“总体上”使得测试数据和训练数据是大致一样的。比如一个神经元的输出是x,那么在训练的时候它有p的概率参与训练,(1-p)的概率丢弃,那么它输出的期望是px+(1-p)0=px。因此测试的时候把这个神经元的权重乘以p可以得到同样的期望。
3. Batch Normalization
BN原理这里不赘述了,我的博客里由整理。这里主要讲一下,为什么BN也会有dropout类似正则的能力。我们知道BN是为了解决CNN中internal covariate shift而提出的归一化方法。归一化带来的好处是,让输出遵从0,1正态分布,从而让输入在激活函数中处于线性部分,帮助网络更快拟合,但带来一个问题,激活函数都处于线性区,那网络非线性表达能力就会大幅削弱。所以为了更好的满足网络对线性与非线性的需求,BN在归一化后,又对结果进行了scale和shift。这两个参数可以通过数据来优化,自己学习判断该神经元对网络的贡献程度,如果他们认为该神经元无用,就会更新scale的值,让其趋于0。这就类似于dropout,随机阻断神经元。但区别在于,BN是主动学习,而dropout是随机。
4. 训练时间
选择合适的学习率,和学习轮次对于模型性能来说很重要。其实这个很好理解,当我们是指更小的 学习率,更多的轮次时,模型会针对训练集学习更加细节的特有的特征,那么网络就会缺少对共同特征的关注,降低模型泛化能力。
5. lable smothing
在常见的多分类问题中,先经过softmax处理后进行交叉熵计算,原理很简单可以将计算loss理解为,为了使得网络对测试集预测的概率分布和其真实分布接近,常用的做法是使用one-hot对真实标签进行编码,这种将标签强制one-hot的方式使网络过于自信会导致过拟合,因此软化这种编码方式。
如下,qi是label smoothing后的标签,可以看到,当i=y时,qi变成了比1小的数,同时,原来qi为0的情况,都通过均值提高了。K表示模型的类别数。
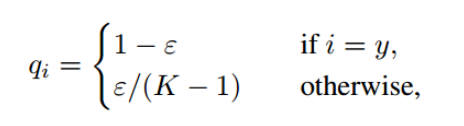
通过软化标签,降低正样本与负样本的惩罚力度,可以帮助模型降低对正样本独有特征的关注度,提高对负样本共有特征的提炼能力,缓和过拟合。
6. mixup
mixup可以理解为一种数据增强的方式,从训练样本中随机抽取两个样本进行简单的随机加权求和,同时样本的标签也对应加权求和,然后预测结果与加权求和之后的标签求损失,在反向求导更新参数。直接上公式
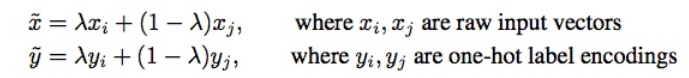
代码实现中,并不是同时取出两个batch,而是取一个batch,并将该batch中的样本ID顺序打乱(shuffle),然后再进行加权求和。而最后损失函数则是输出的预测值对这两组标签分别求损失,然后用之前样本所有的权重加权求和,反向求导更新参数。

版权声明:本文为CSDN博主「小小小绿叶」的原创文章,
遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/litt1e/article/details/106155416





