性能度量是衡量模型泛化能力的评判标准,性能度量反映了任务需求,在对比不同模型的能力时,使用不同的性能度量往往会导致不同的评判结果,因此什么样的模型是好的,不仅取决于算法和数据,还取决于任务需求。
1、错误率和精度
其实说白了就是我们的损失函数所体现的指标,比如常见的在分类问题中分类错误类别所占的比例或者是回归问题中的均方误差等,分别如下面的公式所示
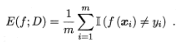
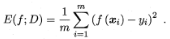
2、查准率、查全率与F1
查准率:查准率表示预测的正例中有多少是真正的正率(也就是你预测正例的准确性)
查全率:查全率表示真是的正例中有多少被准确的预测为正率(也就是你把多少的正例给预测出来了)
首先我们引入混淆矩阵,混淆矩阵表示如下
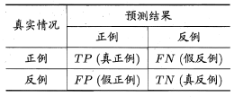
简单说下变量的概念,例如TP就是预测为为正例的结果中真正的正例的比例(也就是说你预测为正例的结果中实际上是有正例和反例的),FP就是你预测为正例的结果集中实际上是反例所占的比例。对于FN和TN的概念也是一样的。现在可以将我们的查全率和查准率表示出来
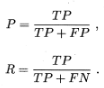
P为查准率,R为查全率。那介绍查全率和查准率到底有什么用呢,事实上这两个概念都有对应的特征定场景,比如查准率,对于一些步允许犯错误的场景,我们就希望查准率要高,也就是要收紧我们的阀值,对一些不能极大概率确定为正例的我们统统步预测或者作为反例。比如在对病人的病情预测时,我们就一定要保持足够高的准确性,对于那些没有足够把握的预测还是让专家进行进一步的分析。而对于查全率就是可以理解为一个正例都不能放过,也就是放宽预测的阀值,争取将所有的正例都预测出来(即使在这个过程中还会将很多反例预测为正例,那也无所谓)。
从查全率和查准率的概念来看,这两者是相互矛盾的度量。一般来说查准率高时,查全率往往偏低;查全率高时,查准率就偏低。P-R曲线正式描述查全率和查准率的变化曲线(很多时候我们希望两者都够好,但特定的业务场景可能会偏向某一个值),P-R曲线如下
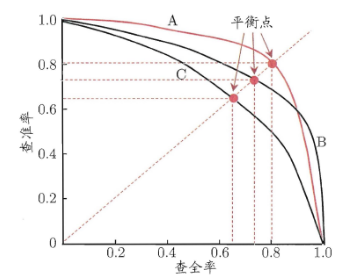
在上图中展示了三个模型(模型A,B,C)的P-R曲线图,那如何根据P-R曲线来评价模型的好坏呢。第一,若模型的曲线包围了另一个模型的曲线(如A和B都包围了C),则认为模型A,B的性能要优于C;第二,对比B和A,当模型的曲线交叉后,就比较这两条曲线下面的面积,面积大的模型性能更好。然而对于这样的面积比较是比较难做到的,因为这些曲线都是不规则的,在算面积的时候往往比较复杂,因此引入另一个度量标准F1,其表达式如下

F1是将查全率和查准率放在同样重要的位置上的一个度量值,F1值越大也代表了模型的性能越好
3、ROC与AUC
学习器对测试样本的评估结果一般为一个实值或概率,设定一个阈值,大于阈值为正例,小于阈值为负例,因此这个实值的好坏直接决定了学习器的泛化性能,若将这些实值排序,则排序的好坏决定了学习器的性能高低。ROC曲线正是从这个角度出发来研究学习器的泛化性能,ROC(Receiver Operating Characteristic)曲线与P-R曲线十分类似,都是按照排序的顺序逐一按照正例预测,不同的是ROC曲线以“真正例率”(True Positive Rate,简称TPR)为横轴,纵轴为“假正例率”(False Positive Rate,简称FPR),ROC偏重研究基于测试样本评估值的排序好坏。


通过ROC来比较模型的性能的方法和P-R曲线是一样的。ROC曲线是对预测样本排好序之后,通过选取不同的阀值来计算出不同的TPR值和FPR值绘制的。AUC就是ROC曲线的面积。而最理想的分类器就是FP和TN为0,即全部分类正确,此时有TPR=1,FPR=0。
本文转自:博客园 - 微笑sun,转载此文目的在于传递更多信息,版权归原作者所有。





