今天突然被以前同学人问到机器学习中的’过拟合‘和‘欠拟合’是什么意思呢?
“过拟合就是训练的时候效果很好,损失函数值可以降得很低,但是到测试数据集的时候表现就不那么好了,原因是过分依赖于现有训练数据集的特征造成的,解决方法是可以加大数据集来进行训练。比如在图像领域可以通过拉伸旋转变换剪裁等等方式来增加训练数据集然后通过Dropout随机清零参数来避免.......“。巴拉巴拉讲了一堆,虽然我很想解释明白,但是.......总感觉有苦说不出的憋屈,最后:

这让我意识到我可能太过于沉浸于自己的世界了,没有考虑到别人的感受,我回来后寻思着不对,对于没有接触过机器学习这一块的人来说很多名词可能就听不太懂,我不能用太多的专业词,我要用最直白的语言解释,于是产生了这篇博客。
--------------------以下进行正经的解释----------------------
拟合(Fitting):就是说这个曲线能不能很好的描述某些样本,并且有比较好的泛化能力。
过拟合(Overfitting):就是太过贴近于训练数据的特征了,在训练集上表现非常优秀,近乎完美的预测/区分了所有的数据,但是在新的测试集上却表现平平,不具泛化性,拿到新样本后没有办法去准确的判断。
下面给一个代码中实际的运行结果感受一下:
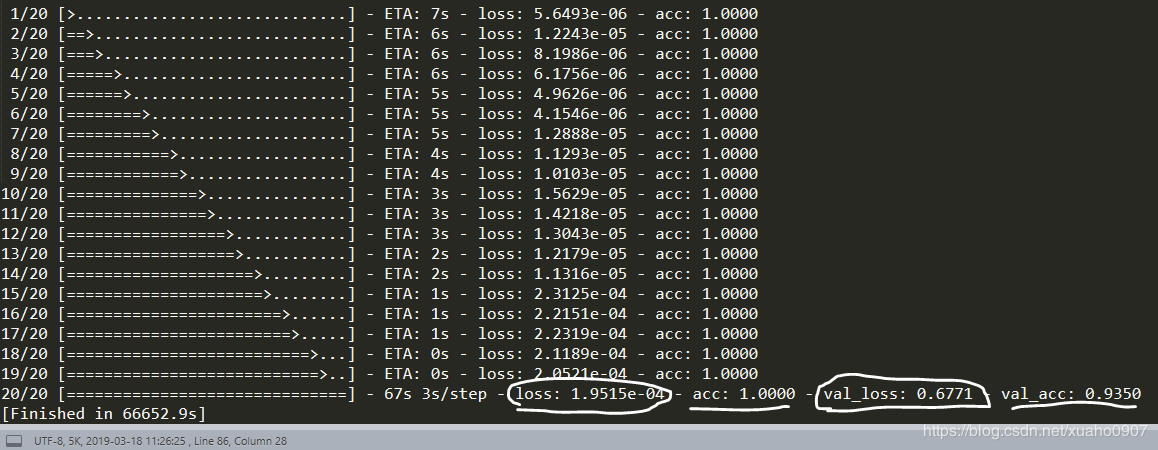
欠拟合(UnderFitting):测试样本的特性没有学到,或者是模型过于简单无法拟合或区分样本。
直观解释:
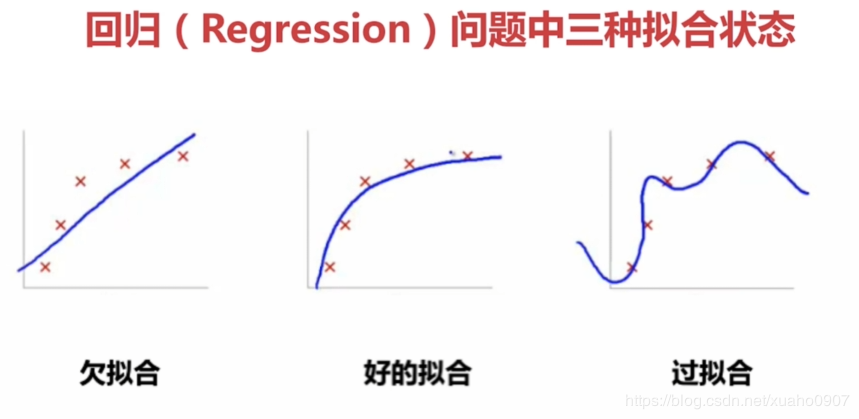
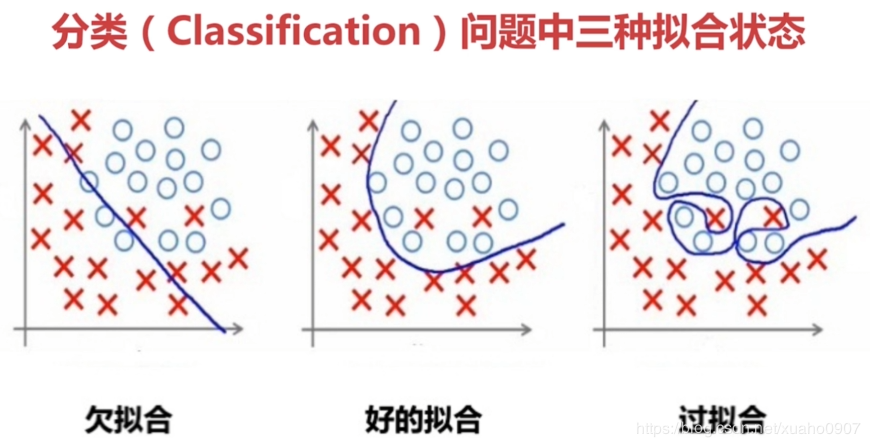
解决过拟合的方法:增大数据量,正则化(L1,L2),丢弃法Dropout(把其中的一些神经元去掉只用部分神经元去构建神经网络)
解决欠拟合的方法:优化模型,一般是模型过于简单无法描述样本的特性。
-----------------------------------正经解释完毕,以下是非正经解释----------------------------------
就好比你喜欢一个女生,这个女生有着自己的习性,为了追到这个女生我们经常会去迎合这个女生的习性。比如喝温水有固定的温度、挂电话只能她先挂、出去逛街不能哔哔太累、看书只能用书签不能折页........,这个就是我们学到的‘经验’。但是!万一也许可能这个女生某一天觉得你没有足够关心她每天都忙于自己的事情就和你分手啦.....
然后,当你再找女朋友时,你拿出这些 ‘经验’ 但是好像发现效果并不好,因为每个女生的习性和喜好都不一样,所以你就陷入过拟合。
怎么解决过拟合呢?那就是多交几个女朋友(增大训练数据量)啦!多了解一些不同女生的习性和喜好,当你已经把全世界所有女生的习性和喜好都学过之后,还有你追不到的女朋友吗? 但是,现实很残酷的,哪有那么多女朋友来供你学习的,你还可以选择丢弃法(Dropout),就是选择性的学习女朋友的喜好和习性,这样就会有概率学不到只属于她“个人癖好”的部分,你学到的就会更加具有普适性。
如何解释欠拟合...,那就简单了,就是你第一个女朋友都没追到,她的习性和喜好你还没能完全掌握。
那么怎么解决欠拟合呢?那就只能提升你自己的人格魅力了(模型复杂度),这个我也没什么资格指点你,毕竟我也是凭实力单身多年。
完美拟合,当你在追第一个女朋友的时候,你自身有一定的人格魅力(模型复杂度),并且并没有完全去迎合她的习性,毕竟存在 ‘个人癖好’ 这个‘错误’习性,你学到的是有泛化性的女生习性特征,当你用这些特征再去追女生的时候,成功率就很高了!
版权声明:本文为CSDN博主「爱吃冰淇凌的羊驼」的原创文章,
遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/xuaho0907/article/details/88649141





