Source Link
Forward Rendering & Deferred Rendering
https://gamedevelopment.tutsplus.com/articles/forward-rendering-vs-defer...
Deferred Rendering && Forward Rendering
什么是前向渲染(Forward Rendering)?
Forward Rendering是一种被大多数引擎所使用的比较传统的渲染技术,显卡(GPU)通过将应用程序阶段(CPU)所传递给它的Geometry拆解成顶点,并将其变换(transformed)和分解成为片段(fragment)或者像素,从而进入显示到屏幕前的最后的渲染操作阶段(final rendering treatment)。前向渲染的一个典型特征是一个几何体(Geometry)从传入显卡进行处理到最后屏幕显示图形的整个过程是不间断的,它是一个线性的处理过程。
下图准确的描述了Forward Rendering的处理过程:
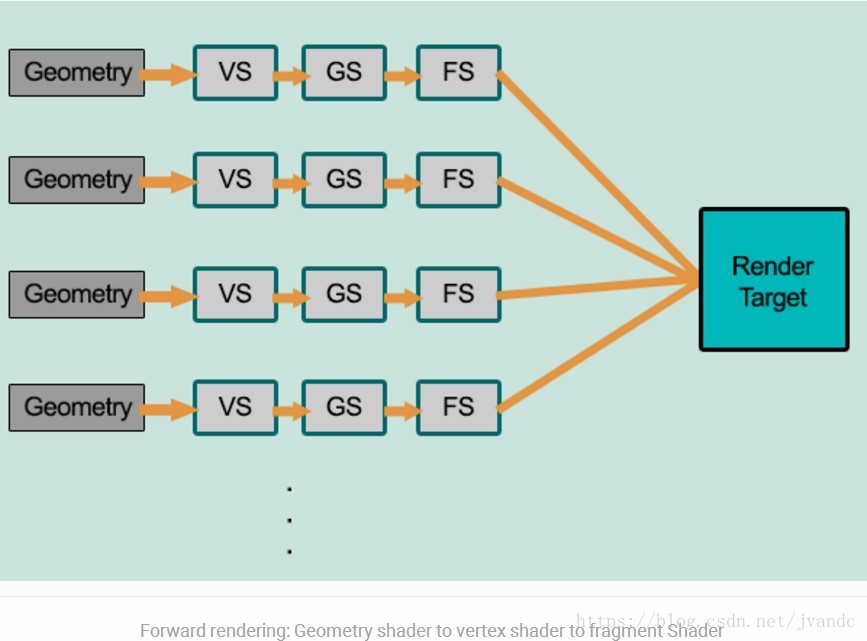
可以看到,上图有四个Geometry,对应了4个Drawcall,它们的经过VS->GS->FS,最后到达RenderTarget的阶段的过程是不会被中断的,Render Pipe(渲染管道)一次处理一个Geometry。
这就是我们常说的Forward Rendering,我们一贯的渲染路径都是采取这种方式。
什么是延迟渲染(Deferred Rendering)?
那么什么是延迟渲染(Deferred Rendering)呢?延迟二字表明了我们从Geometry到RenderTarget的处理过程不是连续的,它会将所有的Geometry从渲染管道(Render Pipe:VS->GS)输出后(输出到Geometry Buffer,也就是我们常说的G-Buffer),然后通过应用着色(applying shading)得到最后的图像,下图是Deferred Rendering的一般过程:
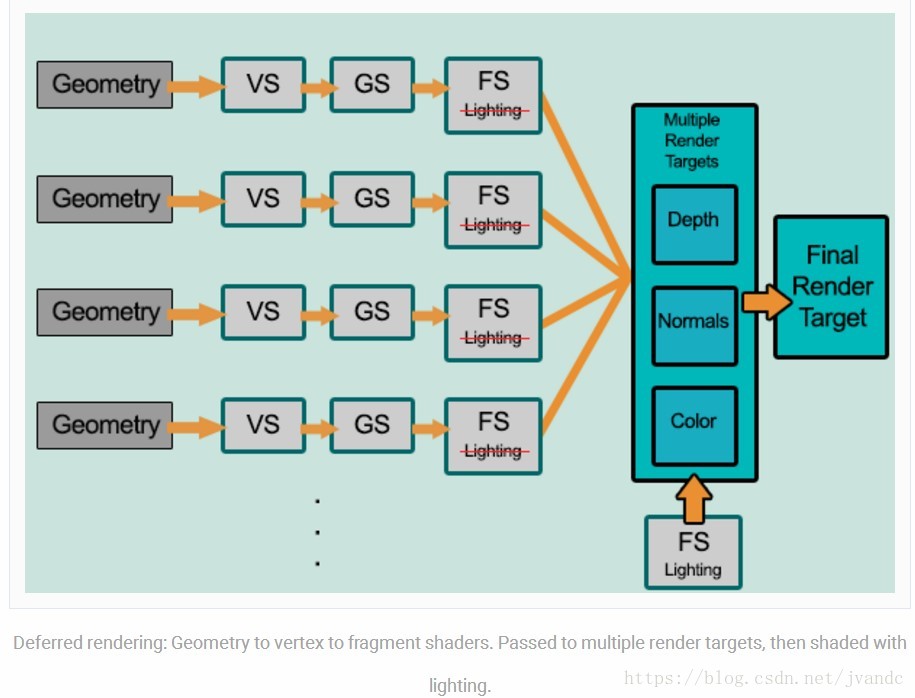
从上图我们可以看到,在MRT之前,没有FS lighting针对每一个Geometry的处理过程,FS Lighting的处理是针对MRT的。
为什么要这样做呢?
光照的计算是前向渲染和延迟渲染最主要的区别。在一个标准的前向渲染管线中,在一个可见场景中,场景中每一个光照(every light)的计算必须针对每一个顶点和每一个片段,我们假设在场景中有100个几何体(Geometries),每一个几何体有1000个顶点,粗略估算场景中会有100,000个多边形,显卡能够比较轻松的处理这样数量的多边形,但是,当这些多边形送入到片段处理器(Fragment shader)时,逐像素的光照计算(per-pixel lighting)将产生极大的开销,the real slowdown(减速) can occur。
开发者试图在Vertex Shader中处理尽可能多的光照计算,以减少Fragment Shader的计算压力。如果采用per-pixel lighting(光照效果相对更好),那么Fragment Shader将不得不针对每一个多边形的每一个可见的片段(Fragment)进行计算,即使除去重叠的部分(overlaps)和被其他多边形(polygon’s)遮挡的片段(Fragments),假设屏幕的分辨率是1024*768,这样低的分辨率,Fragment Shader要处理的像素也多达800,000个,Fragment Shader每一帧要处理的像素都达到了百万级别,并且,很多片段(Fragments)可能并不会显示在屏幕上,因为它们可能会被深度测试(depth test)剔除掉,这样大量的光照计算就浪费在这些片段上了。
设想一下,百万级别的片段光照计算,如果需要针对每一个光源都计算一次,那么,in big O notation,时间复杂度将升到O( [num lights] * 1,000,000),可见其时间复杂度直接和几何体的数量及光源个数有关。
现在来说,有一些引擎采用一些取巧的方式去减少Fragment Shader的计算量,比如,将极远处的光源直接剔除,合并光源,或者使用光照贴图(lights map,very popular,but static)。如果在获得更好的光照效果的同时又想减轻Fragment Shader的计算压力,那么,我们需要一种更好的解决方案。
延迟渲染是减少物件数量(object count, why object count?),尤其是减少片段数量(fragment count), 逐像素光照计算(per-pixel lighting)的非常有趣的一种方案,在Forward Rendering中我们需要处理所有的片段(fragments),而在Deferred Rendering中我们只需要处理分辨率大小(resolution size)数量的片段即可。它的时间复杂度是O([num lights] * screen_resolution)。
延迟渲染不会关心场景中有多少个物件会显示在屏幕上,它的计算复杂度与屏幕分辨率及光源数量有关。
延迟渲染的工作原理
延迟着色的基本原理是,通过MRT(multiple render targets)将几何体(geometry)渲染到屏幕空间,渲染过程并不包括光照着色(light shading),深度缓冲,法向量缓冲以及颜色缓冲作为不同的缓冲区被写入,这些缓冲区能够提供足够的信息使Fragment Shader每一个光源针对每一个像素完成光照计算。

知道每一个像素的距离,和它对应的法向量,我们可以得到光源照射在该像素上的最终渲染效果。
选择哪一种渲染方式呢?
如果你需要渲染光源非常复杂的场景,那么建议使用Deferred Rendering,但是同时,延迟渲染也有一些重大的缺陷:
- 首先我们上面提到延迟渲染的工作原理,它将geometry通过MRT渲染到屏幕空间,MRT在老式的显卡上是不被支持的,所以在使用这项技术的时候,应该要明确显卡是否支持MRT。
- Deferred Rendering需要比较大的带宽(bandwidth)。老式的显卡或许并不具备这种大的带宽的传输能力。
- 不能使用透明的物件(transparent object)。除非你在使用Deferred Rendering渲染不透明物件的同时,使用Forward Rendering的方式渲染透明的物件。为什么Deferred Rendering不能渲染透明的物件呢?因为Deferred Rendering它需要对物件依据深度进行排序,只能处理显示在最前面的像素,无法对透明物件进行Alpha Blend。
- Deferred Rendering不支持抗锯齿(anti-aliasing)。某些引擎可能会使用edge detection,FXAA等方法解决该问题。
- Deferred Rendering只允许存在一个材质。除非使用Deferred Rendering的一个变种Deferred Lighting。
- 由于阴影(Shadows)的表现依赖于光源的数量,Deferred Rendering对此支持并不好。
Appendix
Deferred Shading VS Deferred Lighting
Deferred Shading和Deferred Lighting应该说是Deferred Rendering两种具体的实现方法。二者的区别是:Deferred Shading将所有的Shading全部转到Deferred阶段去执行,而Deferred Lighting是选择性的将Lighting的计算转到Deferred阶段进行。下面分别对二者介绍。
Deferred Shading
从Deferred Shading的名称上来看,它实际执行的时第一个pass不会在Vertex Shader和Pixel Shader处理器中进行着色计算(Shading),着色计算(Shading)会挪到第二个pass中去。
在第一个pass中,需要被第二个pass进行着色计算(Shading)的相关信息会被收集起来,比如每一个表面的Positions,Normals和materials信息会通过“render to texture(渲染到纹理)”被渲染到geometry buffer(G-Buffer)。随后,片段着色器(Fragment Shader)或者像素着色器(Pixel Shader)使用这些屏幕空间(screen space)的纹理缓冲(texture buffers)对每一个像素或者片段进行直接(direct)或者间接(indirect)的光照(lighting)计算。
关于Deferred Shading的优缺点上一节中Deferred Rendering已经有过一些描述了,这里着重提一下一些新的术语:
- Depth peeling(深度剥离), 该技术可以用来对独立的透明物件进行排序,其代价是额外的batches和G-Buffer size。但是,透明物体排序是必要的时候,使用Deferred Shading技术并不比Foward Shading更好。
- Deferred Shading使用多个不同的材质是可能,但是与此同时,它的代价是更多的数据被存储到已经很大的G-Buffer中,并且会消耗掉更多的带宽。
- 另外,Deferred Shading 的抗锯齿技术能够通过其他技术实现,但是效率并不高,效果也并不是最佳。
Deferred Lighting
Deferred Lighting技术可以看成是Deferred Shading技术的一个变种。相比Deferred Shading,它使用了三个pass。第一个pass作用和Deferred Shading相同,只渲染必要的顶点等信息到G-Buffer中,随后,在屏幕空间中,“Deferred” pass 仅仅输出漫反射和镜面光照数据,因此,第二个pass的作用是读回整个被渲染场景的光照数据(lighting data)并且输出最后的逐像素着色(per-pixel shading)。这里一个显而易见的优点是Deferred Lighting技术大大减少(dramatic reduction)了G-buffer的大小,其所付出的代价是需要渲染场景中的几何体两次(render the scene geometry twice instead one),另外所付出的代价是Deferred pass 必须分别单独输出diffuse 和 specular irrandance。
DS的主要流程是:
- 准备G-Buffer(Normal & Depth)。
- 进行Deferred Lighting并得到L-Buffer(计算得到的F(diff) 以及 F(spec))
- 在L-Buffer的基础上重新渲染场景并进行最终的Shading。
正因为Deferred Lighting技术大大减少了G-Buffer的大小,它可以解决掉Deferred Shading的一大缺陷是可以使用多个不同的材质;另外一个优点是可以使用MSAA进行抗锯齿。
Multiple Render Targets
从PixelShader 3.0(OpenGL2.0和Direct 9.0)开始支持该技术。该技术的原理简单来说就是将每像素的数据分别保存到不同的缓冲区当中,这样的好处就是这些缓冲区数据由此可以成为照片级光照效果着色器的参数。
来源:CSDN - TwinkleStar0121
原文链接:https://blog.csdn.net/jvandc/article/details/81176675





